 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer
Paper and Code
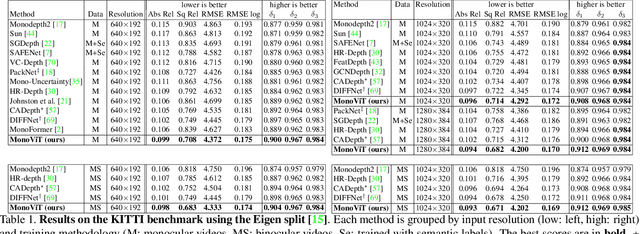
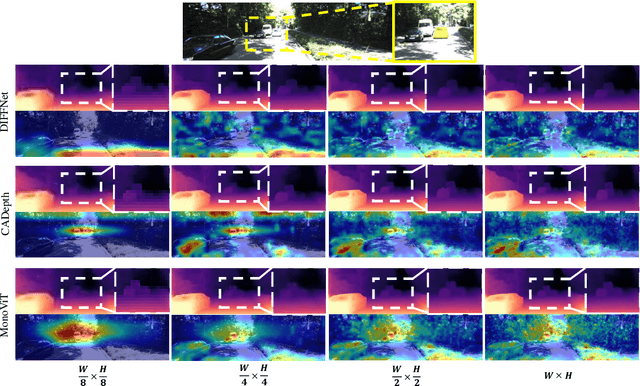
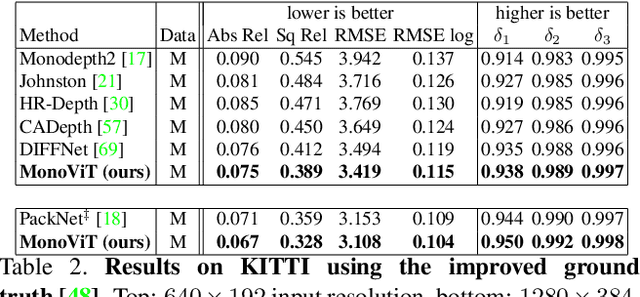
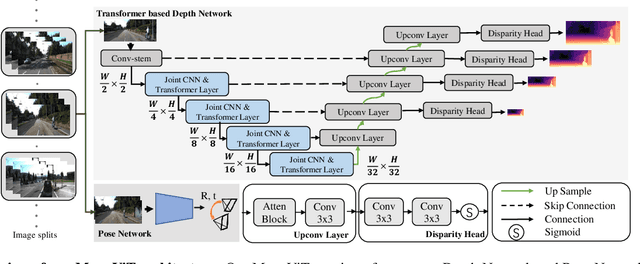
Self-supervised monocular depth estimation is an attractive solution that does not require hard-to-source depth labels for training. Convolutional neural networks (CNNs) have recently achieved great success in this task. However, their limited receptive field constrains existing network architectures to reason only locally, dampening the effectiveness of the self-supervised paradigm. In the light of the recent successes achieved by Vision Transformers (ViTs), we propose MonoViT, a brand-new framework combining the global reasoning enabled by ViT models with the flexibility of self-supervised monocular depth estimation. By combining plain convolutions with Transformer blocks, our model can reason locally and globally, yielding depth prediction at a higher level of detail and accuracy, allowing MonoViT to achieve state-of-the-art performance on the established KITTI dataset. Moreover, MonoViT proves its superior generalization capacities on other datasets such as Make3D and DrivingStereo.