 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Stage-wise Evolution of User Interests for News Recommendation
Mar 11, 2026Personalized news recommendation is highly time-sensitive, as user interests are often driven by emerging events, trending topics, and shifting real-world contexts. These dynamics make it essential to model not only users' long-term preferences, which reflect stable reading habits and high-order collaborative patterns, but also their short-term, context-dependent interests that change rapidly over time. However, most existing approaches rely on a single static interaction graph, which struggles to capture both long-term preference patterns and short-term interest changes as user behavior evolves. To address this challenge, we propose a unified framework that learns user preferences from both global and local temporal perspectives. A global preference modeling component captures long-term collaborative signals from the overall interaction graph, while a local preference modeling component partitions historical interactions into stage-wise temporal subgraphs to represent short-term dynamics. Within this module, an LSTM branch models the progressive evolution of recent interests, and a self-attention branch captures long-range temporal dependencies. Extensive experiments on two large-scale real-world datasets show that our approach consistently outperforms strong baselines and delivers fresher and more relevant recommendations across diverse user behaviors and temporal settings.
* ACM Web Conference 2026 Accepted
Revealing Perception and Generation Dynamics in LVLMs: Mitigating Hallucinations via Validated Dominance Correction
Dec 21, 2025Large Vision-Language Models (LVLMs) have shown remarkable capabilities, yet hallucinations remain a persistent challenge. This work presents a systematic analysis of the internal evolution of visual perception and token generation in LVLMs, revealing two key patterns. First, perception follows a three-stage GATE process: early layers perform a Global scan, intermediate layers Approach and Tighten on core content, and later layers Explore supplementary regions. Second, generation exhibits an SAD (Subdominant Accumulation to Dominant) pattern, where hallucinated tokens arise from the repeated accumulation of subdominant tokens lacking support from attention (visual perception) or feed-forward network (internal knowledge). Guided by these findings, we devise the VDC (Validated Dominance Correction) strategy, which detects unsupported tokens and replaces them with validated dominant ones to improve output reliability. Extensive experiments across multiple models and benchmarks confirm that VDC substantially mitigates hallucinations.
Attention and Risk-Aware Decision Framework for Safe Autonomous Driving
Sep 09, 2025Autonomous driving has attracted great interest due to its potential capability in full-unsupervised driving. Model-based and learning-based methods are widely used in autonomous driving. Model-based methods rely on pre-defined models of the environment and may struggle with unforeseen events. Proximal policy optimization (PPO), an advanced learning-based method, can adapt to the above limits by learning from interactions with the environment. However, existing PPO faces challenges with poor training results, and low training efficiency in long sequences. Moreover, the poor training results are equivalent to collisions in driving tasks. To solve these issues, this paper develops an improved PPO by introducing the risk-aware mechanism, a risk-attention decision network, a balanced reward function, and a safety-assisted mechanism. The risk-aware mechanism focuses on highlighting areas with potential collisions, facilitating safe-driving learning of the PPO. The balanced reward function adjusts rewards based on the number of surrounding vehicles, promoting efficient exploration of the control strategy during training. Additionally, the risk-attention network enhances the PPO to hold channel and spatial attention for the high-risk areas of input images. Moreover, the safety-assisted mechanism supervises and prevents the actions with risks of collisions during the lane keeping and lane changing. Simulation results on a physical engine demonstrate that the proposed algorithm outperforms benchmark algorithms in collision avoidance, achieving higher peak reward with less training time, and shorter driving time remaining on the risky areas among multiple testing traffic flow scenarios.
Marine Chlorophyll Prediction and Driver Analysis based on LSTM-RF Hybrid Models
Aug 07, 2025Marine chlorophyll concentration is an important indicator of ecosystem health and carbon cycle strength, and its accurate prediction is crucial for red tide warning and ecological response. In this paper, we propose a LSTM-RF hybrid model that combines the advantages of LSTM and RF, which solves the deficiencies of a single model in time-series modelling and nonlinear feature portrayal. Trained with multi-source ocean data(temperature, salinity, dissolved oxygen, etc.), the experimental results show that the LSTM-RF model has an R^2 of 0.5386, an MSE of 0.005806, and an MAE of 0.057147 on the test set, which is significantly better than using LSTM (R^2 = 0.0208) and RF (R^2 =0.4934) alone , respectively. The standardised treatment and sliding window approach improved the prediction accuracy of the model and provided an innovative solution for high-frequency prediction of marine ecological variables.
I$^3$-MRec: Invariant Learning with Information Bottleneck for Incomplete Modality Recommendation
Aug 06, 2025



Multimodal recommender systems (MRS) improve recommendation performance by integrating diverse semantic information from multiple modalities. However, the assumption of the availability of all modalities rarely holds in practice due to missing images, incomplete descriptions, or inconsistent user content. These challenges significantly degrade the robustness and generalization capabilities of current models. To address these challenges, we introduce a novel method called \textbf{I$^3$-MRec}, which uses \textbf{I}nvariant learning with \textbf{I}nformation bottleneck principle for \textbf{I}ncomplete \textbf{M}odality \textbf{Rec}ommendation. To achieve robust performance in missing modality scenarios, I$^3$-MRec enforces two pivotal properties: (i) cross-modal preference invariance, which ensures consistent user preference modeling across varying modality environments, and (ii) compact yet effective modality representation, which filters out task-irrelevant modality information while maximally preserving essential features relevant to recommendation. By treating each modality as a distinct semantic environment, I$^3$-MRec employs invariant risk minimization (IRM) to learn modality-specific item representations. In parallel, a missing-aware fusion module grounded in the Information Bottleneck (IB) principle extracts compact and effective item embeddings by suppressing modality noise and preserving core user preference signals. Extensive experiments conducted on three real-world datasets demonstrate that I$^3$-MRec consistently outperforms existing state-of-the-art MRS methods across various modality-missing scenarios, highlighting its effectiveness and robustness in practical applications. The code and processed datasets are released at https://github.com/HuilinChenJN/I3-MRec.
* ACM Multimedia 2025 Accepted
When Spatial meets Temporal in Action Recognition
Nov 22, 2024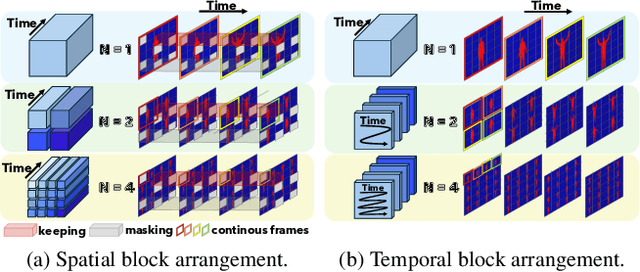



Video action recognition has made significant strides, but challenges remain in effectively using both spatial and temporal information. While existing methods often focus on either spatial features (e.g., object appearance) or temporal dynamics (e.g., motion), they rarely address the need for a comprehensive integration of both. Capturing the rich temporal evolution of video frames, while preserving their spatial details, is crucial for improving accuracy. In this paper, we introduce the Temporal Integration and Motion Enhancement (TIME) layer, a novel preprocessing technique designed to incorporate temporal information. The TIME layer generates new video frames by rearranging the original sequence, preserving temporal order while embedding $N^2$ temporally evolving frames into a single spatial grid of size $N \times N$. This transformation creates new frames that balance both spatial and temporal information, making them compatible with existing video models. When $N=1$, the layer captures rich spatial details, similar to existing methods. As $N$ increases ($N\geq2$), temporal information becomes more prominent, while the spatial information decreases to ensure compatibility with model inputs. We demonstrate the effectiveness of the TIME layer by integrating it into popular action recognition models, such as ResNet-50, Vision Transformer, and Video Masked Autoencoders, for both RGB and depth video data. Our experiments show that the TIME layer enhances recognition accuracy, offering valuable insights for video processing tasks.
Computer vision tasks for intelligent aerospace missions: An overview
Jul 09, 2024

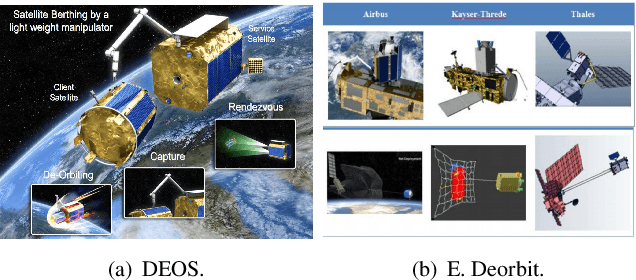
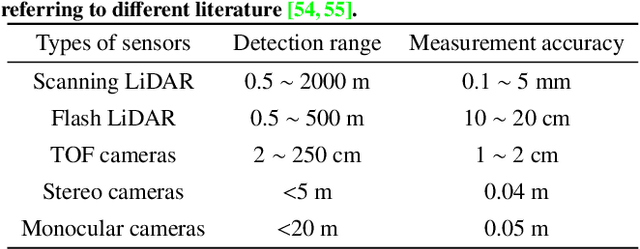
Computer vision tasks are crucial for aerospace missions as they help spacecraft to understand and interpret the space environment, such as estimating position and orientation, reconstructing 3D models, and recognizing objects, which have been extensively studied to successfully carry out the missions. However, traditional methods like Kalman Filtering, Structure from Motion, and Multi-View Stereo are not robust enough to handle harsh conditions, leading to unreliable results. In recent years, deep learning (DL)-based perception technologies have shown great potential and outperformed traditional methods, especially in terms of their robustness to changing environments. To further advance DL-based aerospace perception, various frameworks, datasets, and strategies have been proposed, indicating significant potential for future applications. In this survey, we aim to explore the promising techniques used in perception tasks and emphasize the importance of DL-based aerospace perception. We begin by providing an overview of aerospace perception, including classical space programs developed in recent years, commonly used sensors, and traditional perception methods. Subsequently, we delve into three fundamental perception tasks in aerospace missions: pose estimation, 3D reconstruction, and recognition, as they are basic and crucial for subsequent decision-making and control. Finally, we discuss the limitations and possibilities in current research and provide an outlook on future developments, including the challenges of working with limited datasets, the need for improved algorithms, and the potential benefits of multi-source information fusion.
IBAFormer: Intra-batch Attention Transformer for Domain Generalized Semantic Segmentation
Sep 12, 2023Domain generalized semantic segmentation (DGSS) is a critical yet challenging task, where the model is trained only on source data without access to any target data. Despite the proposal of numerous DGSS strategies, the generalization capability remains limited in CNN architectures. Though some Transformer-based segmentation models show promising performance, they primarily focus on capturing intra-sample attentive relationships, disregarding inter-sample correlations which can potentially benefit DGSS. To this end, we enhance the attention modules in Transformer networks for improving DGSS by incorporating information from other independent samples in the same batch, enriching contextual information, and diversifying the training data for each attention block. Specifically, we propose two alternative intra-batch attention mechanisms, namely mean-based intra-batch attention (MIBA) and element-wise intra-batch attention (EIBA), to capture correlations between different samples, enhancing feature representation and generalization capabilities. Building upon intra-batch attention, we introduce IBAFormer, which integrates self-attention modules with the proposed intra-batch attention for DGSS. Extensive experiments demonstrate that IBAFormer achieves SOTA performance in DGSS, and ablation studies further confirm the effectiveness of each introduced component.
Semantic-Guided Feature Distillation for Multimodal Recommendation
Aug 06, 2023



Multimodal recommendation exploits the rich multimodal information associated with users or items to enhance the representation learning for better performance. In these methods, end-to-end feature extractors (e.g., shallow/deep neural networks) are often adopted to tailor the generic multimodal features that are extracted from raw data by pre-trained models for recommendation. However, compact extractors, such as shallow neural networks, may find it challenging to extract effective information from complex and high-dimensional generic modality features. Conversely, DNN-based extractors may encounter the data sparsity problem in recommendation. To address this problem, we propose a novel model-agnostic approach called Semantic-guided Feature Distillation (SGFD), which employs a teacher-student framework to extract feature for multimodal recommendation. The teacher model first extracts rich modality features from the generic modality feature by considering both the semantic information of items and the complementary information of multiple modalities. SGFD then utilizes response-based and feature-based distillation loss to effectively transfer the knowledge encoded in the teacher model to the student model. To evaluate the effectiveness of our SGFD, we integrate SGFD into three backbone multimodal recommendation models. Extensive experiments on three public real-world datasets demonstrate that SGFD-enhanced models can achieve substantial improvement over their counterparts.
* ACM Multimedia 2023 Accepted
Privacy-Preserving Synthetic Data Generation for Recommendation Systems
Sep 27, 2022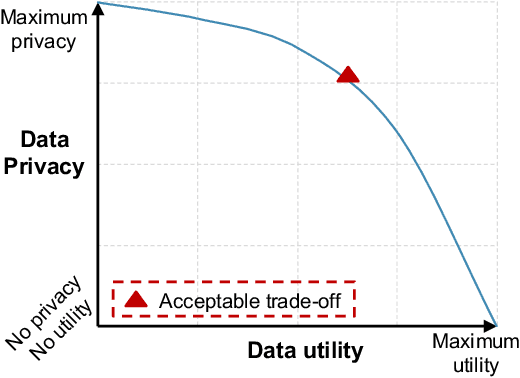
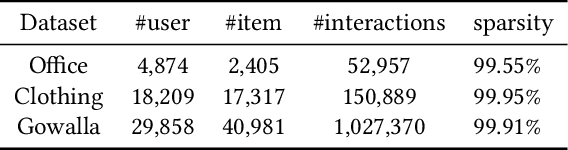

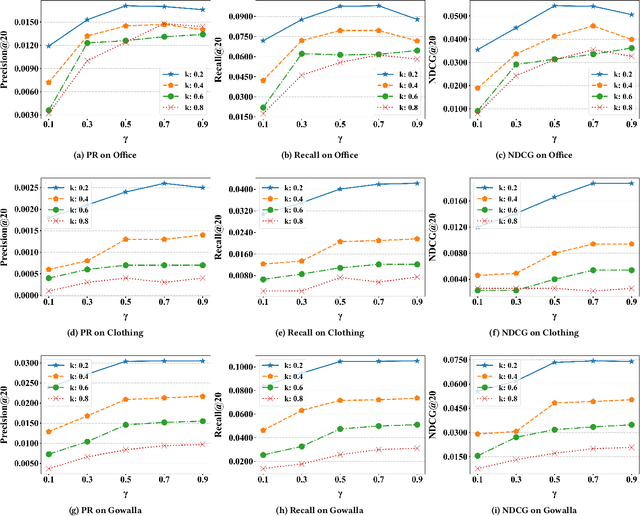
Recommendation systems make predictions chiefly based on users' historical interaction data (e.g., items previously clicked or purchased). There is a risk of privacy leakage when collecting the users' behavior data for building the recommendation model. However, existing privacy-preserving solutions are designed for tackling the privacy issue only during the model training and results collection phases. The problem of privacy leakage still exists when directly sharing the private user interaction data with organizations or releasing them to the public. To address this problem, in this paper, we present a User Privacy Controllable Synthetic Data Generation model (short for UPC-SDG), which generates synthetic interaction data for users based on their privacy preferences. The generation model aims to provide certain privacy guarantees while maximizing the utility of the generated synthetic data at both data level and item level. Specifically, at the data level, we design a selection module that selects those items that contribute less to a user's preferences from the user's interaction data. At the item level, a synthetic data generation module is proposed to generate a synthetic item corresponding to the selected item based on the user's preferences. Furthermore, we also present a privacy-utility trade-off strategy to balance the privacy and utility of the synthetic data. Extensive experiments and ablation studies have been conducted on three publicly accessible datasets to justify our method, demonstrating its effectiveness in generating synthetic data under users' privacy preferences.