 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Next-Best-View Optimization for Risk-Averse Planning
Jun 02, 2026Multi-agent Next-Best-View (NBV) selection for safe path planning in uncertain and unknown environments requires informative, safety-aware, and efficient coordination. Centralized approaches rely on sharing raw sensor data or significant communication overhead, resulting in limited scalability. We propose a distributed, risk-aware multi-agent NBV framework in which each robot maintains a private local 3D Gaussian Splatting map and the team jointly maximizes expected information gain (EIG) restricted to masked zones along planned trajectories. The resulting distributed objective is solved by Consensus ADMM (C-ADMM) over a communication graph, with each robot exchanging only candidate viewpoints, planned trajectory descriptors, and scalar EIG contributions. Collision risk along each trajectory is modeled via Average Value-at-Risk (AV@R) over the local 3DGS map and used both to shape the masking radius and to score planned paths. Experiments in Gibson environments at multiple team sizes show that the distributed formulation approaches the centralized baseline in mapping quality and trajectory safety while reducing communication by orders of magnitude.
Conflict-Aware Active Perception and Control in 3D Gaussian Splatting Fields via Control Barrier Functions
May 19, 2026Active perception in uncertain environments requires robots to navigate safely while acquiring informative observations to reduce map uncertainty. These objectives inherently conflict, as informative viewpoints often lie near uncertain regions with higher collision risk. To address this challenge, we develop a conflict-aware active perception and control framework for robotic systems operating in environments represented by 3D Gaussian Splatting (3DGS). Safety is enforced using a Control Barrier Function (CBF) derived from an Average Value-at-Risk AV@R collision-risk metric that accounts for geometric uncertainty and guarantees forward invariance of a safe set. To improve perception, we propose a risk-aware Expected Information Gain (EIG) formulation for selecting the next-best-view and introduce perception barrier functions that align the camera orientation with the local information-ascent direction. To obtain a tractable formulation for these conflicting safety and perception objectives, we propose a unified safety-critical, perception-aware quadratic program that enforces safety as a hard constraint while relaxing perception constraints through slack variables. Simulation results demonstrate that the proposed method improves both safety and information acquisition compared to existing 3DGS-based approaches.
Beyond Uncertainty: Risk-Aware Active View Acquisition for Safe Robot Navigation and 3D Scene Understanding with FisherRF
Mar 18, 2024



This work proposes a novel approach to bolster both the robot's risk assessment and safety measures while deepening its understanding of 3D scenes, which is achieved by leveraging Radiance Field (RF) models and 3D Gaussian Splatting. To further enhance these capabilities, we incorporate additional sampled views from the environment with the RF model. One of our key contributions is the introduction of Risk-aware Environment Masking (RaEM), which prioritizes crucial information by selecting the next-best-view that maximizes the expected information gain. This targeted approach aims to minimize uncertainties surrounding the robot's path and enhance the safety of its navigation. Our method offers a dual benefit: improved robot safety and increased efficiency in risk-aware 3D scene reconstruction and understanding. Extensive experiments in real-world scenarios demonstrate the effectiveness of our proposed approach, highlighting its potential to establish a robust and safety-focused framework for active robot exploration and 3D scene understanding.
Scalable Networked Feature Selection with Randomized Algorithm for Robot Navigation
Mar 18, 2024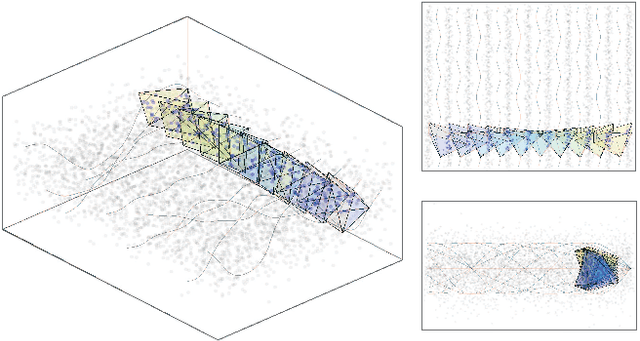
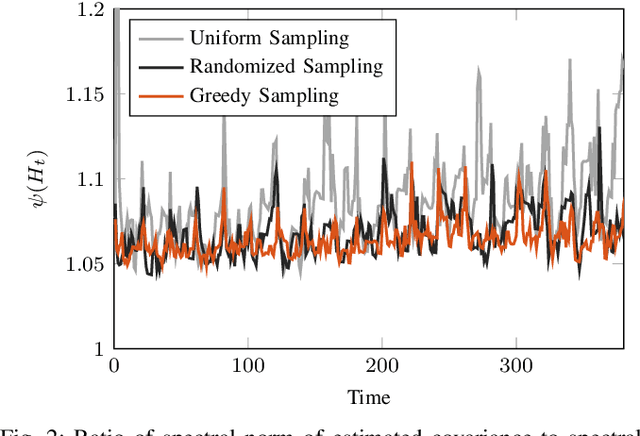
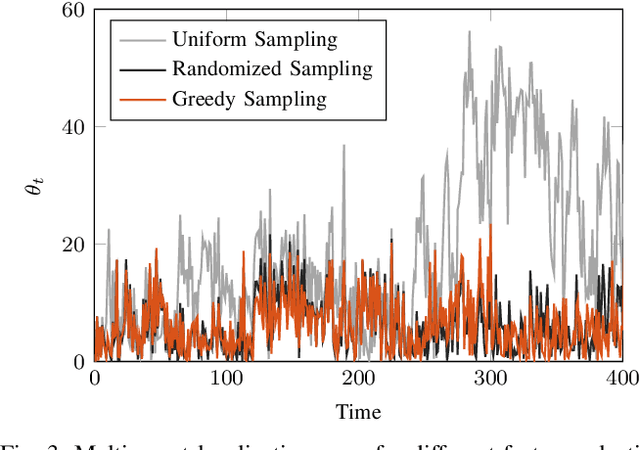
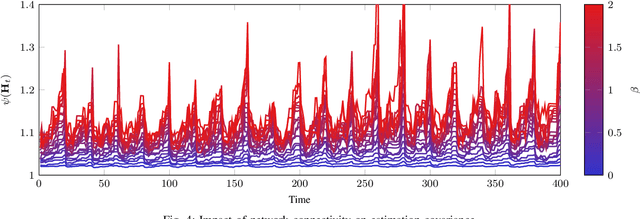
We address the problem of sparse selection of visual features for localizing a team of robots navigating an unknown environment, where robots can exchange relative position measurements with neighbors. We select a set of the most informative features by anticipating their importance in robots localization by simulating trajectories of robots over a prediction horizon. Through theoretical proofs, we establish a crucial connection between graph Laplacian and the importance of features. We show that strong network connectivity translates to uniformity in feature importance, which enables uniform random sampling of features and reduces the overall computational complexity. We leverage a scalable randomized algorithm for sparse sums of positive semidefinite matrices to efficiently select the set of the most informative features and significantly improve the probabilistic performance bounds. Finally, we support our findings with extensive simulations.
Symbolic Perception Risk in Autonomous Driving
Mar 16, 2023



We develop a novel framework to assess the risk of misperception in a traffic sign classification task in the presence of exogenous noise. We consider the problem in an autonomous driving setting, where visual input quality gradually improves due to improved resolution, and less noise since the distance to traffic signs decreases. Using the estimated perception statistics obtained using the standard classification algorithms, we aim to quantify the risk of misperception to mitigate the effects of imperfect visual observation. By exploring perception outputs, their expected high-level actions, and potential costs, we show the closed-form representation of the conditional value-at-risk (CVaR) of misperception. Several case studies support the effectiveness of our proposed methodology.
Learning Nonlinear Couplings in Network of Agents from a Single Sample Trajectory
Nov 20, 2022We consider a class of stochastic dynamical networks whose governing dynamics can be modeled using a coupling function. It is shown that the dynamics of such networks can generate geometrically ergodic trajectories under some reasonable assumptions. We show that a general class of coupling functions can be learned using only one sample trajectory from the network. This is practically plausible as in numerous applications it is desired to run an experiment only once but for a longer period of time, rather than repeating the same experiment multiple times from different initial conditions. Building upon ideas from the concentration inequalities for geometrically ergodic Markov chains, we formulate several results about the convergence of the empirical estimator to the true coupling function. Our theoretical findings are supported by extensive simulation results.
Robustness Analysis of Classification Using Recurrent Neural Networks with Perturbed Sequential Input
Mar 10, 2022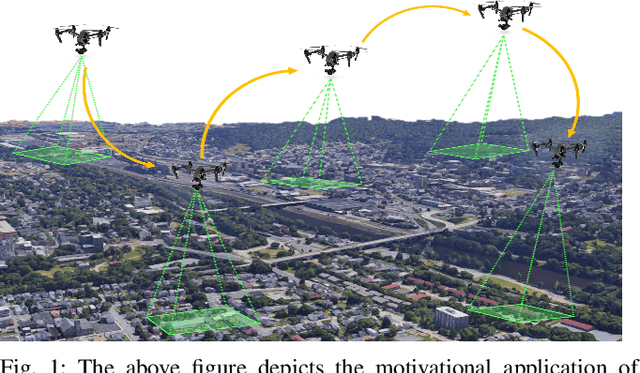
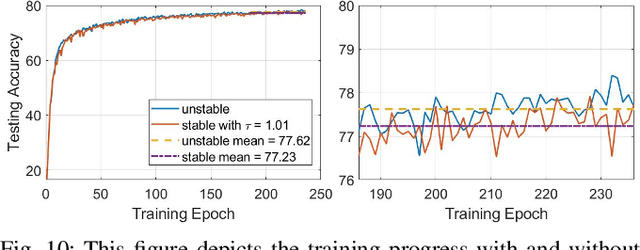


For a given stable recurrent neural network (RNN) that is trained to perform a classification task using sequential inputs, we quantify explicit robustness bounds as a function of trainable weight matrices. The sequential inputs can be perturbed in various ways, e.g., streaming images can be deformed due to robot motion or imperfect camera lens. Using the notion of the Voronoi diagram and Lipschitz properties of stable RNNs, we provide a thorough analysis and characterize the maximum allowable perturbations while guaranteeing the full accuracy of the classification task. We illustrate and validate our theoretical results using a map dataset with clouds as well as the MNIST dataset.
Robust Learning of Recurrent Neural Networks in Presence of Exogenous Noise
May 04, 2021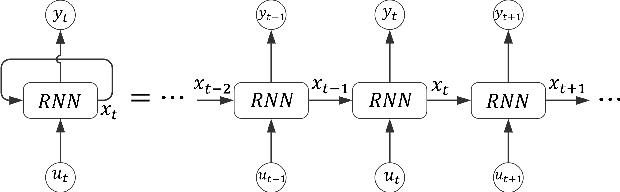
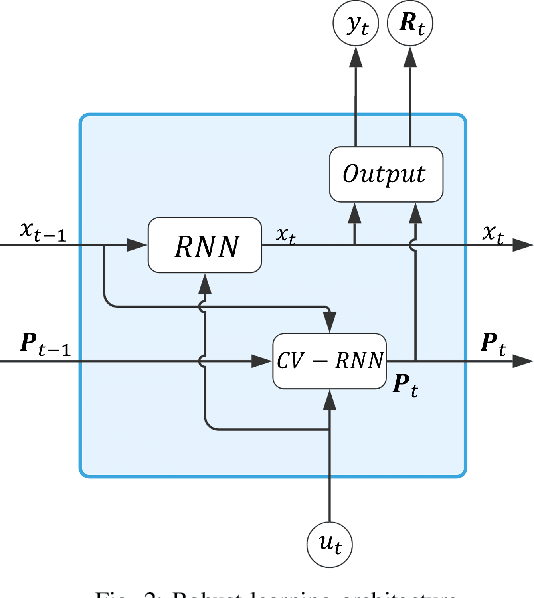
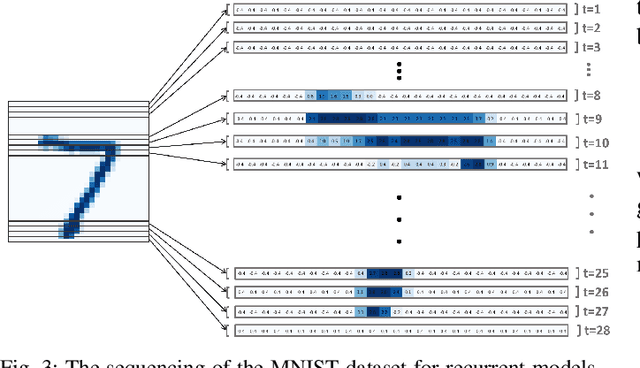

Recurrent Neural networks (RNN) have shown promising potential for learning dynamics of sequential data. However, artificial neural networks are known to exhibit poor robustness in presence of input noise, where the sequential architecture of RNNs exacerbates the problem. In this paper, we will use ideas from control and estimation theories to propose a tractable robustness analysis for RNN models that are subject to input noise. The variance of the output of the noisy system is adopted as a robustness measure to quantify the impact of noise on learning. It is shown that the robustness measure can be estimated efficiently using linearization techniques. Using these results, we proposed a learning method to enhance robustness of a RNN with respect to exogenous Gaussian noise with known statistics. Our extensive simulations on benchmark problems reveal that our proposed methodology significantly improves robustness of recurrent neural networks.
Reinforcement Learning based Multi-Robot Classification via Scalable Communication Structure
Dec 18, 2020
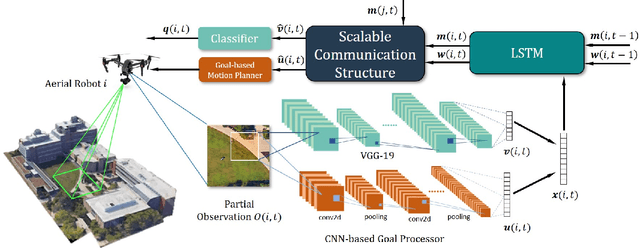
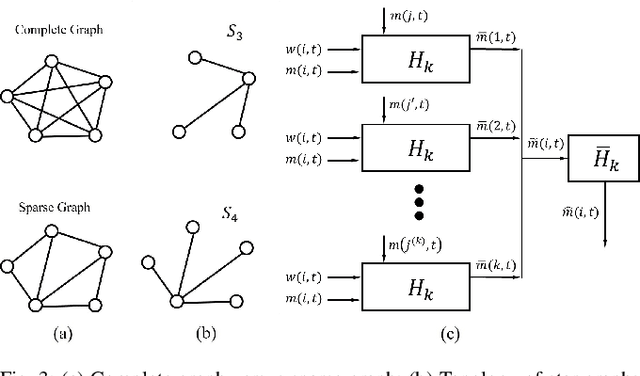

In the multi-robot collaboration domain, training with Reinforcement Learning (RL) can become intractable, and performance starts to deteriorate drastically as the number of robots increases. In this work, we proposed a distributed multi-robot learning architecture with a scalable communication structure capable of learning a robust communication policy for time-varying communication topology. We construct the communication structure with Long-Short Term Memory (LSTM) cells and star graphs, in which the computational complexity of the proposed learning algorithm scales linearly with the number of robots and suitable for application with a large number of robots. The proposed methodology is validated with a map classification problem in the simulated environment. It is shown that the proposed architecture achieves a comparable classification accuracy with the centralized methods, maintains high performance with various numbers of robots without additional training cost, and robust to hacking and loss of the robots in the network.
A Layered Architecture for Active Perception: Image Classification using Deep Reinforcement Learning
Sep 20, 2019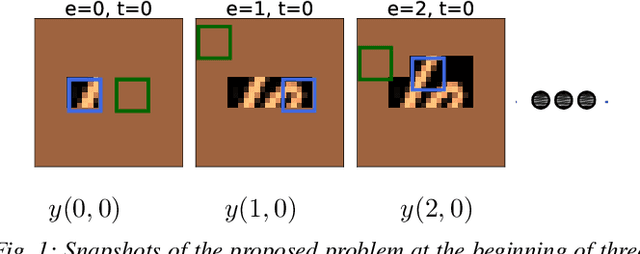
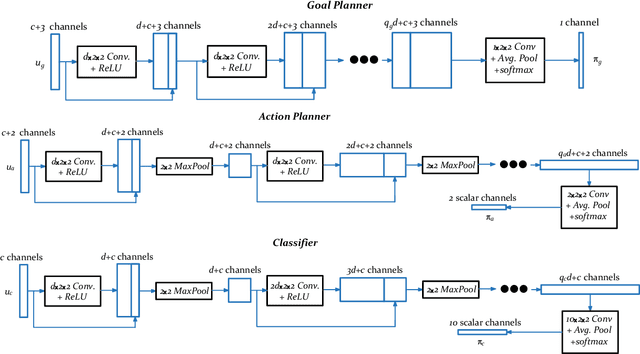

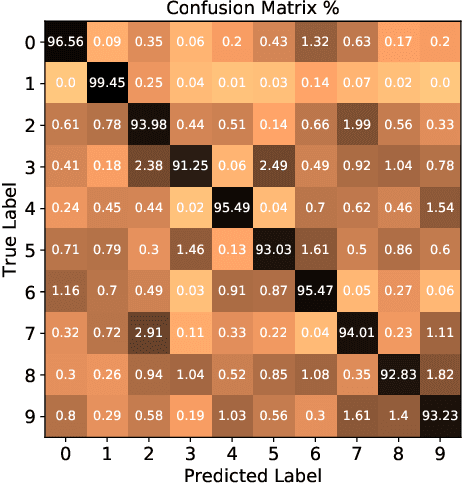
We propose a planning and perception mechanism for a robot (agent), that can only observe the underlying environment partially, in order to solve an image classification problem. A three-layer architecture is suggested that consists of a meta-layer that decides the intermediate goals, an action-layer that selects local actions as the agent navigates towards a goal, and a classification-layer that evaluates the reward and makes a prediction. We design and implement these layers using deep reinforcement learning. A generalized policy gradient algorithm is utilized to learn the parameters of these layers to maximize the expected reward. Our proposed methodology is tested on the MNIST dataset of handwritten digits, which provides us with a level of explainability while interpreting the agent's intermediate goals and course of action.