 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning based Multi-Robot Classification via Scalable Communication Structure
Dec 18, 2020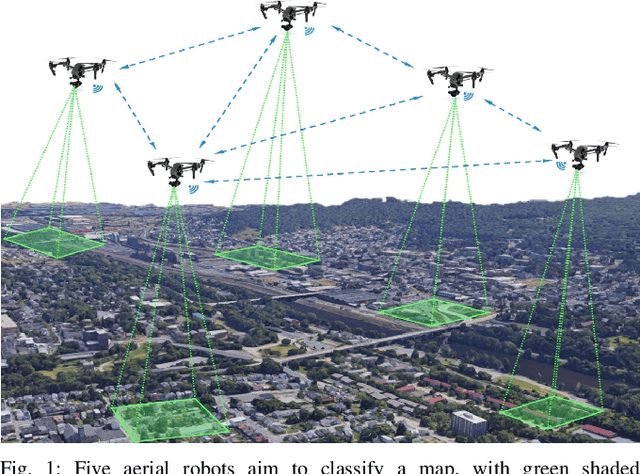
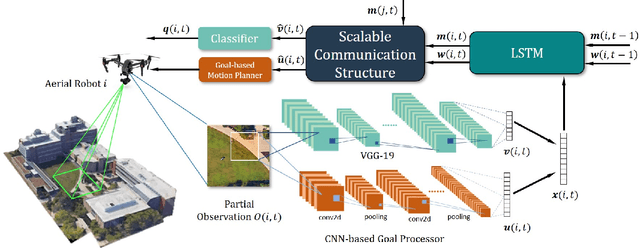
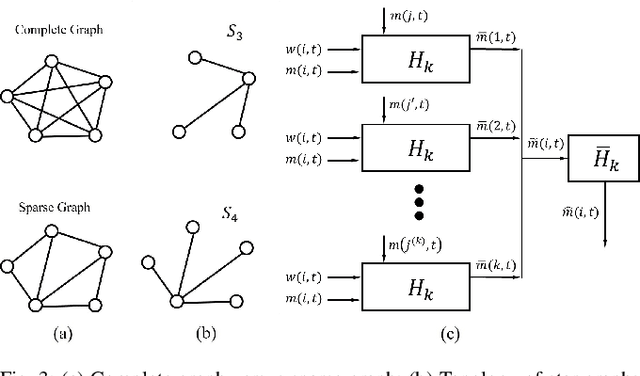

In the multi-robot collaboration domain, training with Reinforcement Learning (RL) can become intractable, and performance starts to deteriorate drastically as the number of robots increases. In this work, we proposed a distributed multi-robot learning architecture with a scalable communication structure capable of learning a robust communication policy for time-varying communication topology. We construct the communication structure with Long-Short Term Memory (LSTM) cells and star graphs, in which the computational complexity of the proposed learning algorithm scales linearly with the number of robots and suitable for application with a large number of robots. The proposed methodology is validated with a map classification problem in the simulated environment. It is shown that the proposed architecture achieves a comparable classification accuracy with the centralized methods, maintains high performance with various numbers of robots without additional training cost, and robust to hacking and loss of the robots in the network.
Hierarchical Reinforcement Learning for Deep Goal Reasoning: An Expressiveness Analysis
Jun 21, 2020
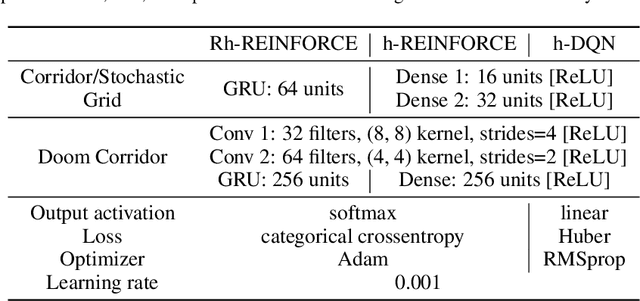
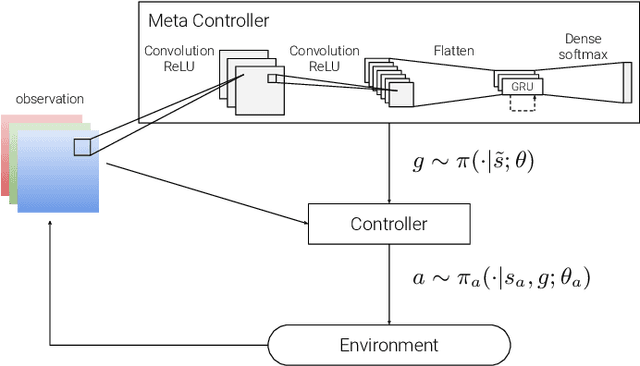
Hierarchical DQN (h-DQN) is a two-level architecture of feedforward neural networks where the meta level selects goals and the lower level takes actions to achieve the goals. We show tasks that cannot be solved by h-DQN, exemplifying the limitation of this type of hierarchical framework (HF). We describe the recurrent hierarchical framework (RHF), generalizing architectures that use a recurrent neural network at the meta level. We analyze the expressiveness of HF and RHF using context-sensitive grammars. We show that RHF is more expressive than HF. We perform experiments comparing an implementation of RHF with two HF baselines; the results corroborate our theoretical findings.
A Layered Architecture for Active Perception: Image Classification using Deep Reinforcement Learning
Sep 20, 2019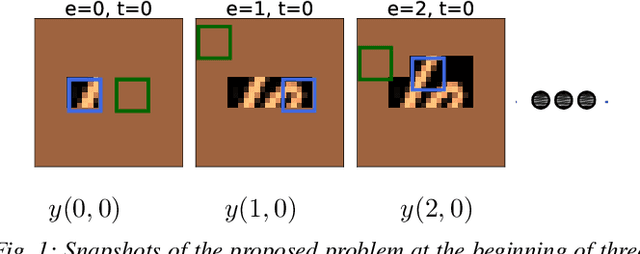
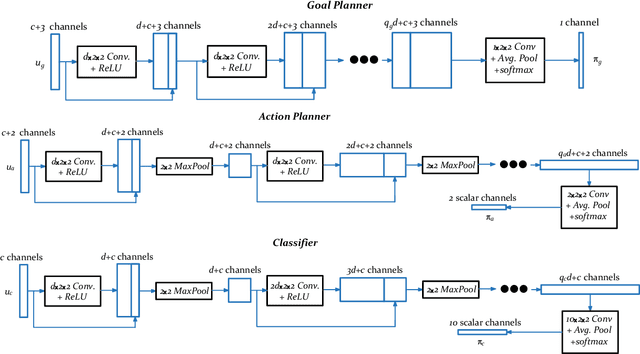

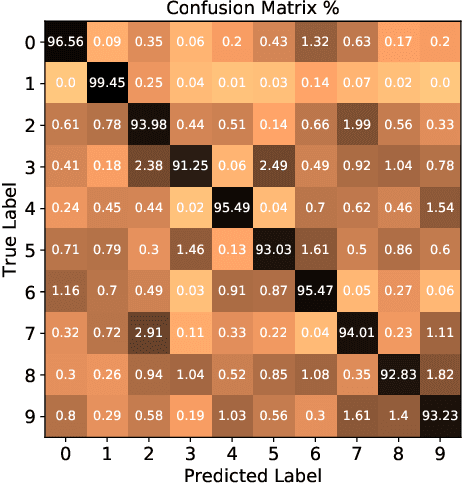
We propose a planning and perception mechanism for a robot (agent), that can only observe the underlying environment partially, in order to solve an image classification problem. A three-layer architecture is suggested that consists of a meta-layer that decides the intermediate goals, an action-layer that selects local actions as the agent navigates towards a goal, and a classification-layer that evaluates the reward and makes a prediction. We design and implement these layers using deep reinforcement learning. A generalized policy gradient algorithm is utilized to learn the parameters of these layers to maximize the expected reward. Our proposed methodology is tested on the MNIST dataset of handwritten digits, which provides us with a level of explainability while interpreting the agent's intermediate goals and course of action.