 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChat Vector: A Simple Approach to Equip LLMs With New Language Chat Capabilities
Paper and Code

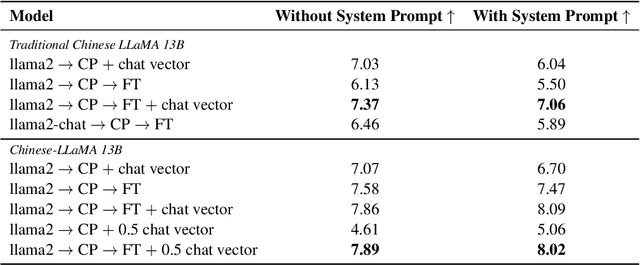

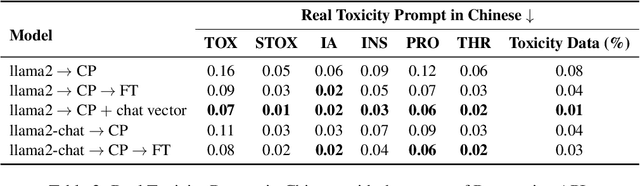
With the advancements in conversational AI, such as ChatGPT, this paper focuses on exploring developing Large Language Models (LLMs) for non-English languages, especially emphasizing alignment with human preferences. We introduce a computationally efficient method, leveraging chat vector, to synergize pre-existing knowledge and behaviors in LLMs, restructuring the conventional training paradigm from continual pre-train -> SFT -> RLHF to continual pre-train + chat vector. Our empirical studies, primarily focused on Traditional Chinese, employ LLaMA2 as the base model and acquire the chat vector by subtracting the pre-trained weights, LLaMA2, from the weights of LLaMA2-chat. Evaluating from three distinct facets, which are toxicity, ability of instruction following, and multi-turn dialogue demonstrates the chat vector's superior efficacy in chatting. To confirm the adaptability of our approach, we extend our experiments to include models pre-trained in both Korean and Simplified Chinese, illustrating the versatility of our methodology. Overall, we present a significant solution in aligning LLMs with human preferences efficiently across various languages, accomplished by the chat vector.