 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization and Mobile Deployment for Anthropocene Neural Style Transfer
Jan 29, 2026This paper presents AnthropoCam, a mobile-based neural style transfer (NST) system optimized for the visual synthesis of Anthropocene environments. Unlike conventional artistic NST, which prioritizes painterly abstraction, stylizing human-altered landscapes demands a careful balance between amplifying material textures and preserving semantic legibility. Industrial infrastructures, waste accumulations, and modified ecosystems contain dense, repetitive patterns that are visually expressive yet highly susceptible to semantic erosion under aggressive style transfer. To address this challenge, we systematically investigate the impact of NST parameter configurations on the visual translation of Anthropocene textures, including feature layer selection, style and content loss weighting, training stability, and output resolution. Through controlled experiments, we identify an optimal parameter manifold that maximizes stylistic expression while preventing semantic erasure. Our results demonstrate that appropriate combinations of convolutional depth, loss ratios, and resolution scaling enable the faithful transformation of anthropogenic material properties into a coherent visual language. Building on these findings, we implement a low-latency, feed-forward NST pipeline deployed on mobile devices. The system integrates a React Native frontend with a Flask-based GPU backend, achieving high-resolution inference within 3-5 seconds on general mobile hardware. This enables real-time, in-situ visual intervention at the site of image capture, supporting participatory engagement with Anthropocene landscapes. By coupling domain-specific NST optimization with mobile deployment, AnthropoCam reframes neural style transfer as a practical and expressive tool for real-time environmental visualization in the Anthropocene.
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022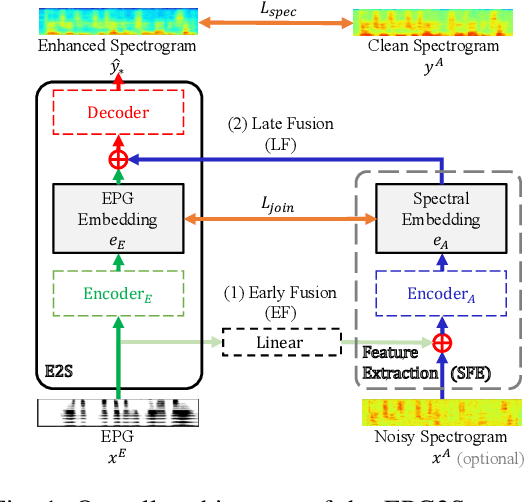
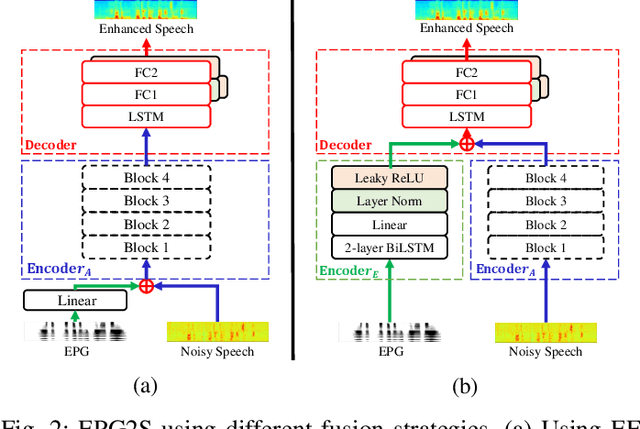
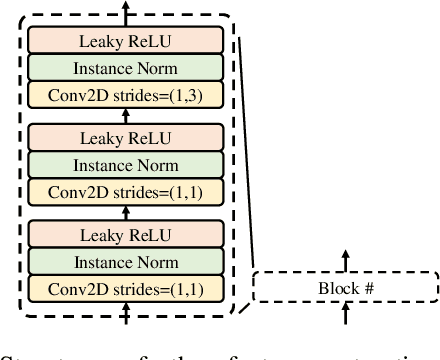
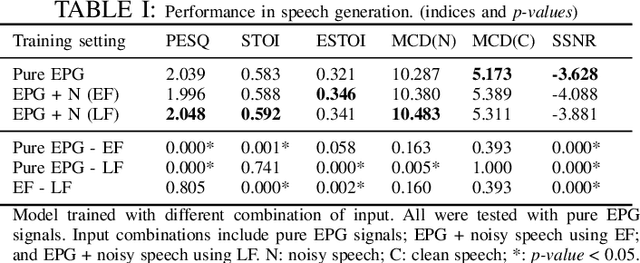
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.