 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Voice-ENHANCE: Speech Restoration using a Diffusion-based Voice Conversion Framework
May 21, 2025We propose a speech enhancement system that combines speaker-agnostic speech restoration with voice conversion (VC) to obtain a studio-level quality speech signal. While voice conversion models are typically used to change speaker characteristics, they can also serve as a means of speech restoration when the target speaker is the same as the source speaker. However, since VC models are vulnerable to noisy conditions, we have included a generative speech restoration (GSR) model at the front end of our proposed system. The GSR model performs noise suppression and restores speech damage incurred during that process without knowledge about the target speaker. The VC stage then uses guidance from clean speaker embeddings to further restore the output speech. By employing this two-stage approach, we have achieved speech quality objective metric scores comparable to state-of-the-art (SOTA) methods across multiple datasets.
VC-ENHANCE: Speech Restoration with Integrated Noise Suppression and Voice Conversion
Sep 10, 2024Noise suppression (NS) algorithms are effective in improving speech quality in many cases. However, aggressive noise suppression can damage the target speech, reducing both speech intelligibility and quality despite removing the noise. This study proposes an explicit speech restoration method using a voice conversion (VC) technique for restoration after noise suppression. We observed that high-quality speech can be restored through a diffusion-based voice conversion stage, conditioned on the target speaker embedding and speech content information extracted from the de-noised speech. This speech restoration can achieve enhancement effects such as bandwidth extension, de-reverberation, and in-painting. Our experimental results demonstrate that this two-stage NS+VC framework outperforms single-stage enhancement models in terms of output speech quality, as measured by objective metrics, while scoring slightly lower in speech intelligibility. To further improve the intelligibility of the combined system, we propose a content encoder adaptation method for robust content extraction in noisy conditions.
Stylebook: Content-Dependent Speaking Style Modeling for Any-to-Any Voice Conversion using Only Speech Data
Sep 12, 2023



While many recent any-to-any voice conversion models succeed in transferring some target speech's style information to the converted speech, they still lack the ability to faithfully reproduce the speaking style of the target speaker. In this work, we propose a novel method to extract rich style information from target utterances and to efficiently transfer it to source speech content without requiring text transcriptions or speaker labeling. Our proposed approach introduces an attention mechanism utilizing a self-supervised learning (SSL) model to collect the speaking styles of a target speaker each corresponding to the different phonetic content. The styles are represented with a set of embeddings called stylebook. In the next step, the stylebook is attended with the source speech's phonetic content to determine the final target style for each source content. Finally, content information extracted from the source speech and content-dependent target style embeddings are fed into a diffusion-based decoder to generate the converted speech mel-spectrogram. Experiment results show that our proposed method combined with a diffusion-based generative model can achieve better speaker similarity in any-to-any voice conversion tasks when compared to baseline models, while the increase in computational complexity with longer utterances is suppressed.
Highly Controllable Diffusion-based Any-to-Any Voice Conversion Model with Frame-level Prosody Feature
Sep 06, 2023



We propose a highly controllable voice manipulation system that can perform any-to-any voice conversion (VC) and prosody modulation simultaneously. State-of-the-art VC systems can transfer sentence-level characteristics such as speaker, emotion, and speaking style. However, manipulating the frame-level prosody, such as pitch, energy and speaking rate, still remains challenging. Our proposed model utilizes a frame-level prosody feature to effectively transfer such properties. Specifically, pitch and energy trajectories are integrated in a prosody conditioning module and then fed alongside speaker and contents embeddings to a diffusion-based decoder generating a converted speech mel-spectrogram. To adjust the speaking rate, our system includes a self-supervised model based post-processing step which allows improved controllability. The proposed model showed comparable speech quality and improved intelligibility compared to a SOTA approach. It can cover a varying range of fundamental frequency (F0), energy and speed modulation while maintaining converted speech quality.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021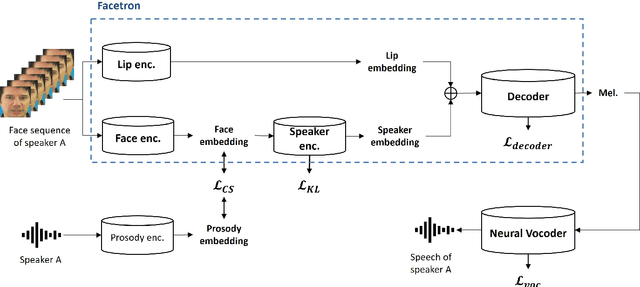
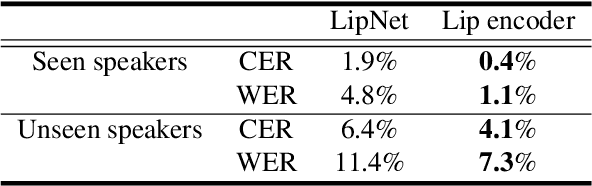
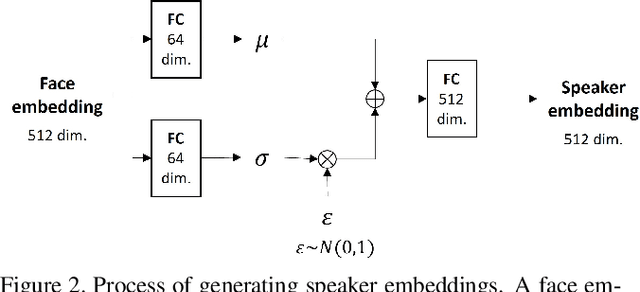

In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.
ExcitNet vocoder: A neural excitation model for parametric speech synthesis systems
Nov 09, 2018


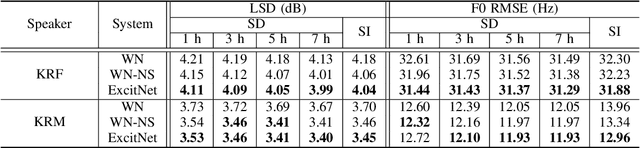
This paper proposes a WaveNet-based neural excitation model (ExcitNet) for statistical parametric speech synthesis systems. Conventional WaveNet-based neural vocoding systems significantly improve the perceptual quality of synthesized speech by statistically generating a time sequence of speech waveforms through an auto-regressive framework. However, they often suffer from noisy outputs because of the difficulties in capturing the complicated time-varying nature of speech signals. To improve modeling efficiency, the proposed ExcitNet vocoder employs an adaptive inverse filter to decouple spectral components from the speech signal. The residual component, i.e. excitation signal, is then trained and generated within the WaveNet framework. In this way, the quality of the synthesized speech signal can be further improved since the spectral component is well represented by a deep learning framework and, moreover, the residual component is efficiently generated by the WaveNet framework. Experimental results show that the proposed ExcitNet vocoder, trained both speaker-dependently and speaker-independently, outperforms traditional linear prediction vocoders and similarly configured conventional WaveNet vocoders.
Speaker-adaptive neural vocoders for statistical parametric speech synthesis systems
Nov 08, 2018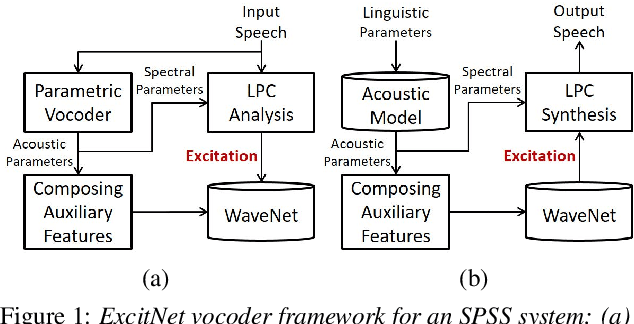



This paper proposes speaker-adaptive neural vocoders for statistical parametric speech synthesis (SPSS) systems. Recently proposed WaveNet-based neural vocoding systems successfully generate a time sequence of speech signal with an autoregressive framework. However, building high-quality speech synthesis systems with limited training data for a target speaker remains a challenge. To generate more natural speech signals with the constraint of limited training data, we employ a speaker adaptation task with an effective variation of neural vocoding models. In the proposed method, a speaker-independent training method is applied to capture universal attributes embedded in multiple speakers, and the trained model is then fine-tuned to represent the specific characteristics of the target speaker. Experimental results verify that the proposed SPSS systems with speaker-adaptive neural vocoders outperform those with traditional source-filter model-based vocoders and those with WaveNet vocoders, trained either speaker-dependently or speaker-independently.