 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Efficient Audio Captioning With Faithful Guidance Using Audio-text Shared Latent Representation
Paper and Code
Sep 06, 2023
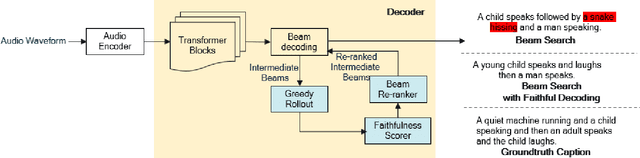


There has been significant research on developing pretrained transformer architectures for multimodal-to-text generation tasks. Albeit performance improvements, such models are frequently overparameterized, hence suffer from hallucination and large memory footprint making them challenging to deploy on edge devices. In this paper, we address both these issues for the application of automated audio captioning. First, we propose a data augmentation technique for generating hallucinated audio captions and show that similarity based on an audio-text shared latent space is suitable for detecting hallucination. Then, we propose a parameter efficient inference time faithful decoding algorithm that enables smaller audio captioning models with performance equivalent to larger models trained with more data. During the beam decoding step, the smaller model utilizes an audio-text shared latent representation to semantically align the generated text with corresponding input audio. Faithful guidance is introduced into the beam probability by incorporating the cosine similarity between latent representation projections of greedy rolled out intermediate beams and audio clip. We show the efficacy of our algorithm on benchmark datasets and evaluate the proposed scheme against baselines using conventional audio captioning and semantic similarity metrics while illustrating tradeoffs between performance and complexity.