 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration for Audio Captioning Models
Paper and Code
Sep 13, 2024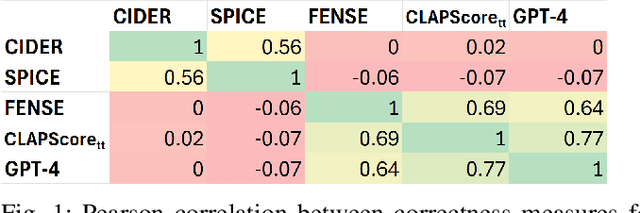
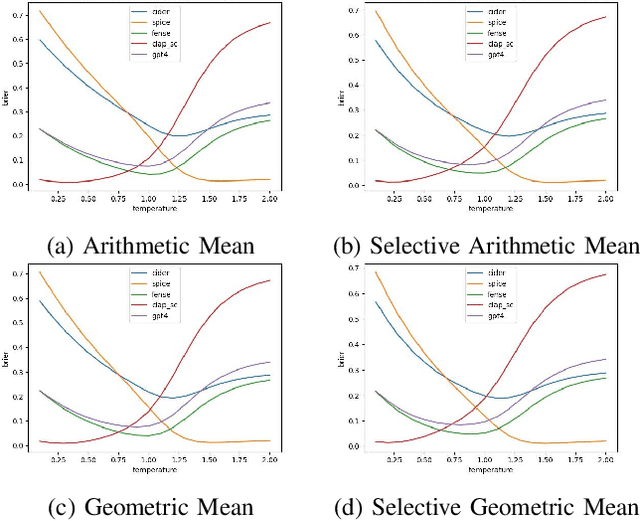
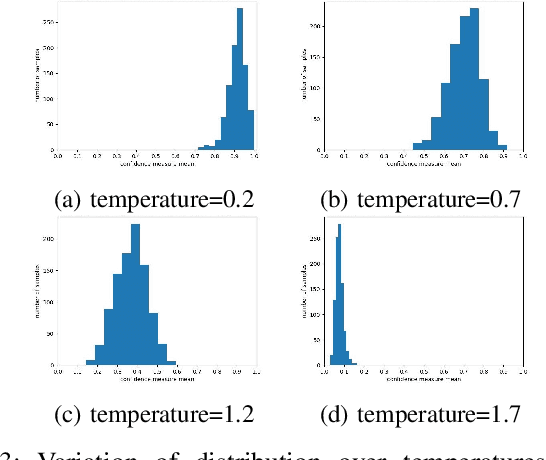
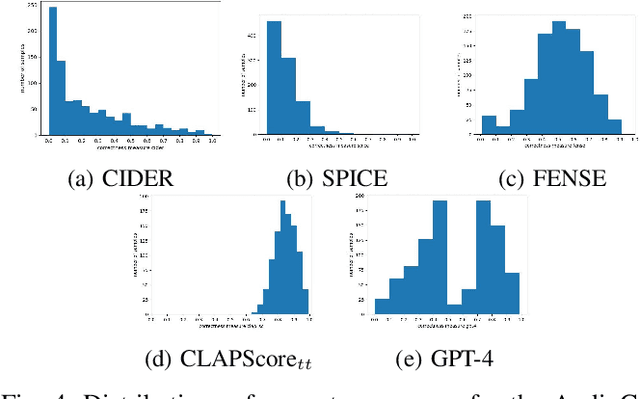
Systems that automatically generate text captions for audio, images and video lack a confidence indicator of the relevance and correctness of the generated sequences. To address this, we build on existing methods of confidence measurement for text by introduce selective pooling of token probabilities, which aligns better with traditional correctness measures than conventional pooling does. Further, we propose directly measuring the similarity between input audio and text in a shared embedding space. To measure self-consistency, we adapt semantic entropy for audio captioning, and find that these two methods align even better than pooling-based metrics with the correctness measure that calculates acoustic similarity between captions. Finally, we explain why temperature scaling of confidences improves calibration.