 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivity report analysis with automatic single or multispan answer extraction
Paper and Code

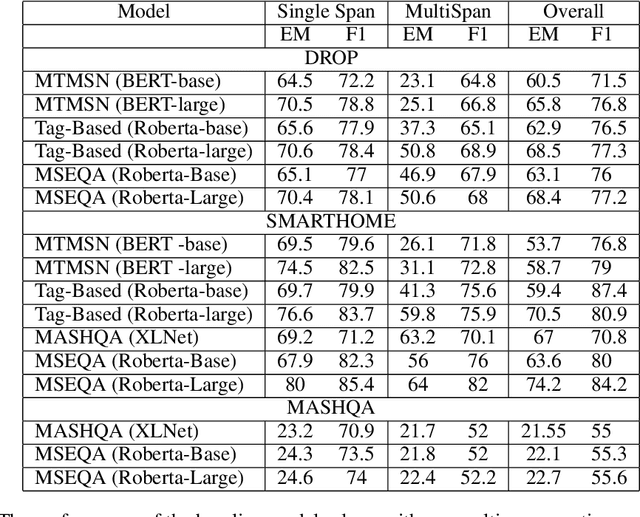
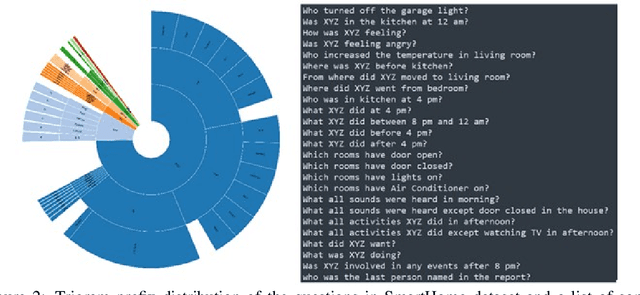
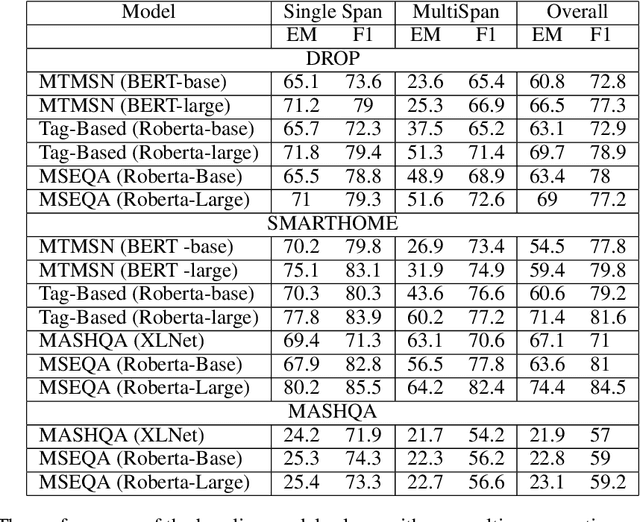
In the era of loT (Internet of Things) we are surrounded by a plethora of Al enabled devices that can transcribe images, video, audio, and sensors signals into text descriptions. When such transcriptions are captured in activity reports for monitoring, life logging and anomaly detection applications, a user would typically request a summary or ask targeted questions about certain sections of the report they are interested in. Depending on the context and the type of question asked, a question answering (QA) system would need to automatically determine whether the answer covers single-span or multi-span text components. Currently available QA datasets primarily focus on single span responses only (such as SQuAD[4]) or contain a low proportion of examples with multiple span answers (such as DROP[3]). To investigate automatic selection of single/multi-span answers in the use case described, we created a new smart home environment dataset comprised of questions paired with single-span or multi-span answers depending on the question and context queried. In addition, we propose a RoBERTa[6]-based multiple span extraction question answering (MSEQA) model returning the appropriate answer span for a given question. Our experiments show that the proposed model outperforms state-of-the-art QA models on our dataset while providing comparable performance on published individual single/multi-span task datasets.