 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound-RL: foundation model-enhanced reinforcement learning for autonomous driving
Feb 11, 2026Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP's dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025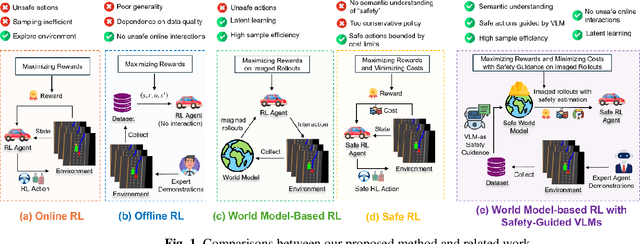
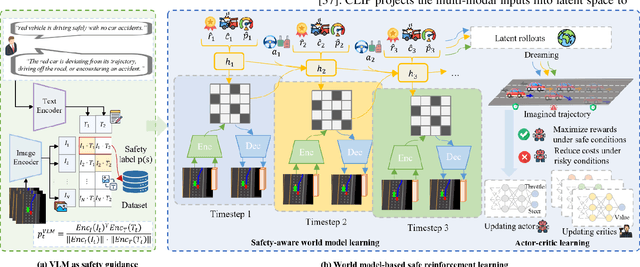
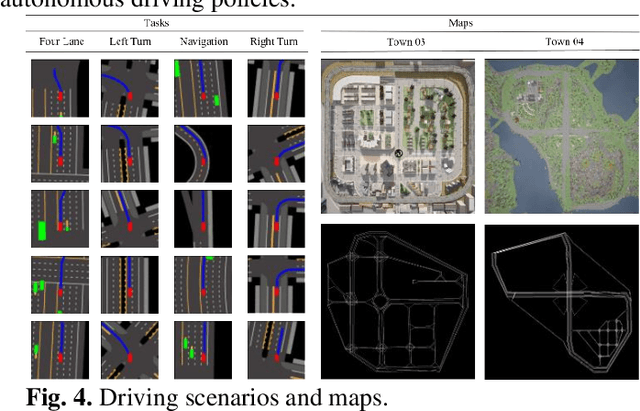
Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
A Racing Dataset and Baseline Model for Track Detection in Autonomous Racing
Feb 19, 2025A significant challenge in racing-related research is the lack of publicly available datasets containing raw images with corresponding annotations for the downstream task. In this paper, we introduce RoRaTrack, a novel dataset that contains annotated multi-camera image data from racing scenarios for track detection. The data is collected on a Dallara AV-21 at a racing circuit in Indiana, in collaboration with the Indy Autonomous Challenge (IAC). RoRaTrack addresses common problems such as blurriness due to high speed, color inversion from the camera, and absence of lane markings on the track. Consequently, we propose RaceGAN, a baseline model based on a Generative Adversarial Network (GAN) that effectively addresses these challenges. The proposed model demonstrates superior performance compared to current state-of-the-art machine learning models in track detection. The dataset and code for this work are available at github.com/RaceGAN.
PFL-LSTR: A privacy-preserving framework for driver intention inference based on in-vehicle and out-vehicle information
Sep 02, 2023



Intelligent vehicle anticipation of the movement intentions of other drivers can reduce collisions. Typically, when a human driver of another vehicle (referred to as the target vehicle) engages in specific behaviors such as checking the rearview mirror prior to lane change, a valuable clue is therein provided on the intentions of the target vehicle's driver. Furthermore, the target driver's intentions can be influenced and shaped by their driving environment. For example, if the target vehicle is too close to a leading vehicle, it may renege the lane change decision. On the other hand, a following vehicle in the target lane is too close to the target vehicle could lead to its reversal of the decision to change lanes. Knowledge of such intentions of all vehicles in a traffic stream can help enhance traffic safety. Unfortunately, such information is often captured in the form of images/videos. Utilization of personally identifiable data to train a general model could violate user privacy. Federated Learning (FL) is a promising tool to resolve this conundrum. FL efficiently trains models without exposing the underlying data. This paper introduces a Personalized Federated Learning (PFL) model embedded a long short-term transformer (LSTR) framework. The framework predicts drivers' intentions by leveraging in-vehicle videos (of driver movement, gestures, and expressions) and out-of-vehicle videos (of the vehicle's surroundings - frontal/rear areas). The proposed PFL-LSTR framework is trained and tested through real-world driving data collected from human drivers at Interstate 65 in Indiana. The results suggest that the PFL-LSTR exhibits high adaptability and high precision, and that out-of-vehicle information (particularly, the driver's rear-mirror viewing actions) is important because it helps reduce false positives and thereby enhances the precision of driver intention inference.
Deep Reinforcement Learning Based Framework for Mobile Energy Disseminator Dispatching to Charge On-the-Road Electric Vehicles
Aug 29, 2023The exponential growth of electric vehicles (EVs) presents novel challenges in preserving battery health and in addressing the persistent problem of vehicle range anxiety. To address these concerns, wireless charging, particularly, Mobile Energy Disseminators (MEDs) have emerged as a promising solution. The MED is mounted behind a large vehicle and charges all participating EVs within a radius upstream of it. Unfortuantely, during such V2V charging, the MED and EVs inadvertently form platoons, thereby occupying multiple lanes and impairing overall corridor travel efficiency. In addition, constrained budgets for MED deployment necessitate the development of an effective dispatching strategy to determine optimal timing and locations for introducing the MEDs into traffic. This paper proposes a deep reinforcement learning (DRL) based methodology to develop a vehicle dispatching framework. In the first component of the framework, we develop a realistic reinforcement learning environment termed "ChargingEnv" which incorporates a reliable charging simulation system that accounts for common practical issues in wireless charging deployment, specifically, the charging panel misalignment. The second component, the Proximal-Policy Optimization (PPO) agent, is trained to control MED dispatching through continuous interactions with ChargingEnv. Numerical experiments were carried out to demonstrate the demonstrate the efficacy of the proposed MED deployment decision processor. The experiment results suggest that the proposed model can significantly enhance EV travel range while efficiently deploying a optimal number of MEDs. The proposed model is found to be not only practical in its applicability but also has promises of real-world effectiveness. The proposed model can help travelers to maximize EV range and help road agencies or private-sector vendors to manage the deployment of MEDs efficiently.
Transfusor: Transformer Diffusor for Controllable Human-like Generation of Vehicle Lane Changing Trajectories
Aug 28, 2023



With ongoing development of autonomous driving systems and increasing desire for deployment, researchers continue to seek reliable approaches for ADS systems. The virtual simulation test (VST) has become a prominent approach for testing autonomous driving systems (ADS) and advanced driver assistance systems (ADAS) due to its advantages of fast execution, low cost, and high repeatability. However, the success of these simulation-based experiments heavily relies on the realism of the testing scenarios. It is needed to create more flexible and high-fidelity testing scenarios in VST in order to increase the safety and reliabilityof ADS and ADAS.To address this challenge, this paper introduces the "Transfusor" model, which leverages the transformer and diffusor models (two cutting-edge deep learning generative technologies). The primary objective of the Transfusor model is to generate highly realistic and controllable human-like lane-changing trajectories in highway scenarios. Extensive experiments were carried out, and the results demonstrate that the proposed model effectively learns the spatiotemporal characteristics of humans' lane-changing behaviors and successfully generates trajectories that closely mimic real-world human driving. As such, the proposed model can play a critical role of creating more flexible and high-fidelity testing scenarios in the VST, ultimately leading to safer and more reliable ADS and ADAS.
Using UAVs for vehicle tracking and collision risk assessment at intersections
Oct 11, 2021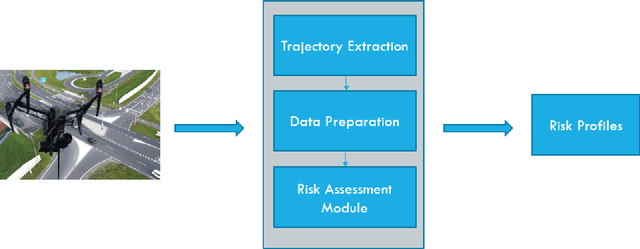
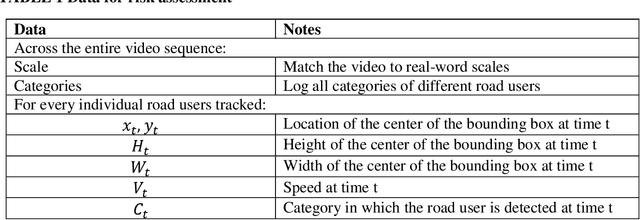
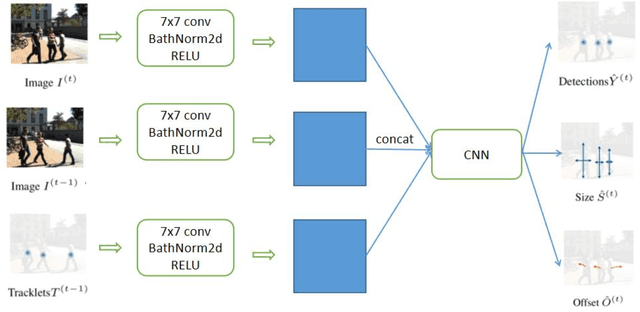

Assessing collision risk is a critical challenge to effective traffic safety management. The deployment of unmanned aerial vehicles (UAVs) to address this issue has shown much promise, given their wide visual field and movement flexibility. This research demonstrates the application of UAVs and V2X connectivity to track the movement of road users and assess potential collisions at intersections. The study uses videos captured by UAVs. The proposed method combines deep-learning based tracking algorithms and time-to-collision tasks. The results not only provide beneficial information for vehicle's recognition of potential crashes and motion planning but also provided a valuable tool for urban road agencies and safety management engineers.
Towards Safer Transportation: a self-supervised learning approach for traffic video deraining
Oct 11, 2021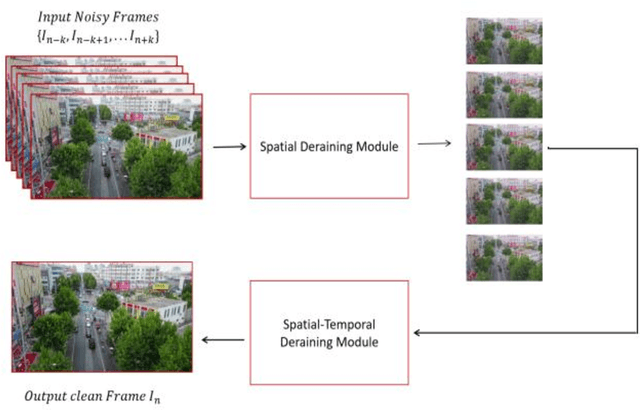
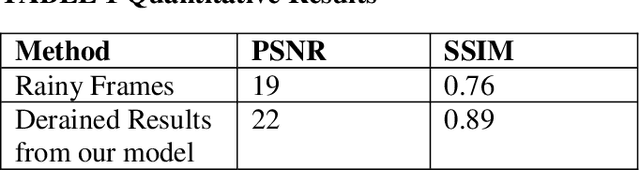

Video monitoring of traffic is useful for traffic management and control, traffic counting, and traffic law enforcement. However, traffic monitoring during inclement weather such as rain is a challenging task because video quality is corrupted by streaks of falling rain on the video image, and this hinders reliable characterization not only of the road environment but also of road-user behavior during such adverse weather events. This study proposes a two-stage self-supervised learning method to remove rain streaks in traffic videos. The first and second stages address intra- and inter-frame noise, respectively. The results indicated that the model exhibits satisfactory performance in terms of the image visual quality and the Peak Signal-Noise Ratio value.
Scalable Traffic Signal Controls using Fog-Cloud Based Multiagent Reinforcement Learning
Oct 11, 2021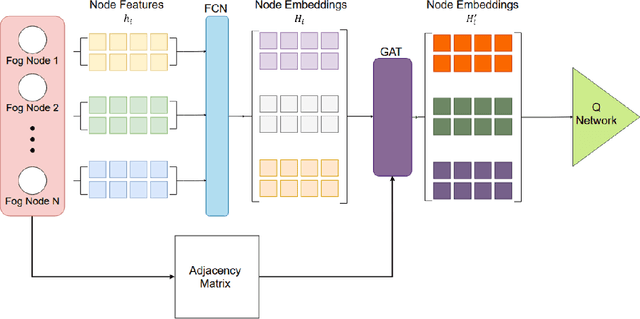
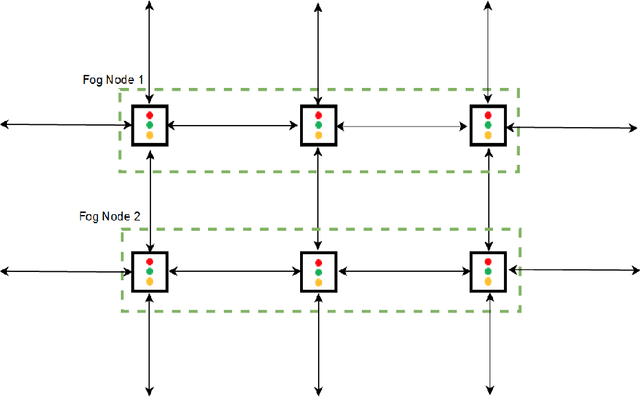
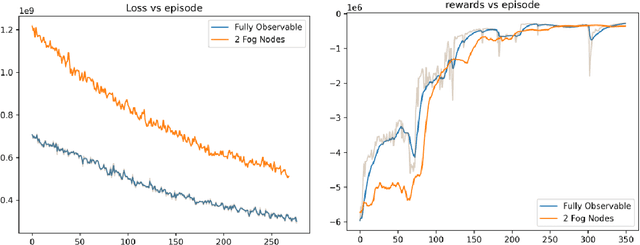
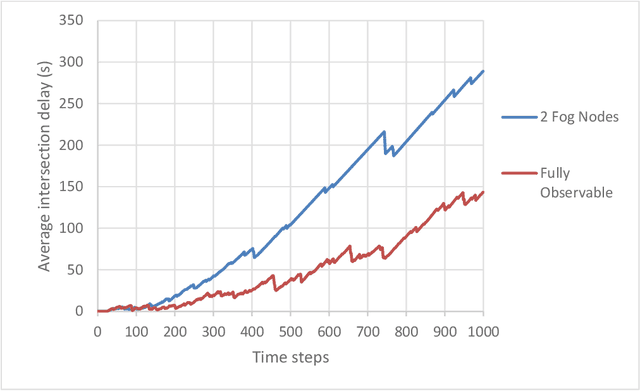
Optimizing traffic signal control (TSC) at intersections continues to pose a challenging problem, particularly for large-scale traffic networks. It has been shown in past research that it is feasible to optimize the operations of individual TSC systems or a small number of such systems. However, it has been computationally difficult to scale these solution approaches to large networks partly due to the curse of dimensionality that is encountered as the number of intersections increases. Fortunately, recent studies have recognized the potential of exploiting advancements in deep and reinforcement learning to address this problem, and some preliminary successes have been achieved in this regard. However, facilitating such intelligent solution approaches may require large amounts of infrastructural investments such as roadside units (RSUs) and drones in order to ensure thorough connectivity across all intersections in large networks, an investment that may be burdensome for agencies to undertake. As such, this study builds on recent work to present a scalable TSC model that may reduce the number of required enabling infrastructure. This is achieved using graph attention networks (GATs) to serve as the neural network for deep reinforcement learning, which aids in maintaining the graph topology of the traffic network while disregarding any irrelevant or unnecessary information. A case study is carried out to demonstrate the effectiveness of the proposed model, and the results show much promise. The overall research outcome suggests that by decomposing large networks using fog-nodes, the proposed fog-based graphic RL (FG-RL) model can be easily applied to scale into larger traffic networks.
Development and testing of an image transformer for explainable autonomous driving systems
Oct 11, 2021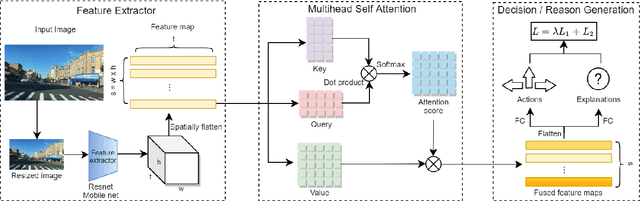

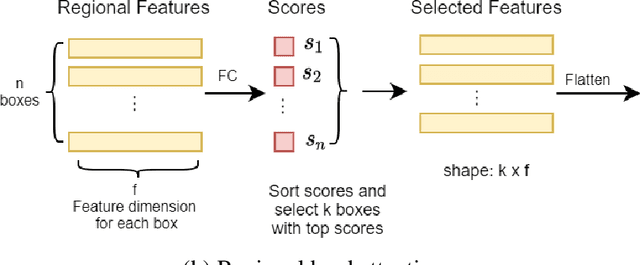

In the last decade, deep learning (DL) approaches have been used successfully in computer vision (CV) applications. However, DL-based CV models are generally considered to be black boxes due to their lack of interpretability. This black box behavior has exacerbated user distrust and therefore has prevented widespread deployment DLCV models in autonomous driving tasks even though some of these models exhibit superiority over human performance. For this reason, it is essential to develop explainable DL models for autonomous driving task. Explainable DL models can not only boost user trust in autonomy but also serve as a diagnostic approach to identify anydefects and weaknesses of the model during the system development phase. In this paper, we propose an explainable end-to-end autonomous driving system based on "Transformer", a state-of-the-art (SOTA) self-attention based model, to map visual features from images collected by onboard cameras to guide potential driving actions with corresponding explanations. The model achieves a soft attention over the global features of the image. The results demonstrate the efficacy of our proposed model as it exhibits superior performance (in terms of correct prediction of actions and explanations) compared to the benchmark model by a significant margin with lower computational cost.