 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHista and Numca: Estimate State Value Effectively for LLM Reinforcement Learning
May 28, 2026Reinforcement learning (RL) refines large language models (LLMs) by directly optimizing model behavior through reward signals. While accurate state value estimation is critical for stable training in classical RL, it remains an underexplored challenge in LLM post-training. In this work, we introduce the State Value Estimation Benchmark (SVEB) to assess state estimation within existing RL frameworks and show that critics in standard approaches like PPO collapse to a coarse group-average baseline. To address this, we propose two techniques: Numca, which leverages numerical spans as gradable milestones for state value estimation, and Hista, a framework that uses LLM's hidden states as representation to weighted average disjoint rollouts and their return. Extensive experiments demonstrate that both methods yield more accurate state value estimates and enhance training performance across different RL algorithms and model sizes without incurring significant computational overhead.
Generative Models in Decision Making: A Survey
Feb 25, 2025In recent years, the exceptional performance of generative models in generative tasks has sparked significant interest in their integration into decision-making processes. Due to their ability to handle complex data distributions and their strong model capacity, generative models can be effectively incorporated into decision-making systems by generating trajectories that guide agents toward high-reward state-action regions or intermediate sub-goals. This paper presents a comprehensive review of the application of generative models in decision-making tasks. We classify seven fundamental types of generative models: energy-based models, generative adversarial networks, variational autoencoders, normalizing flows, diffusion models, generative flow networks, and autoregressive models. Regarding their applications, we categorize their functions into three main roles: controllers, modelers and optimizers, and discuss how each role contributes to decision-making. Furthermore, we examine the deployment of these models across five critical real-world decision-making scenarios. Finally, we summarize the strengths and limitations of current approaches and propose three key directions for advancing next-generation generative directive models: high-performance algorithms, large-scale generalized decision-making models, and self-evolving and adaptive models.
Deep Reinforcement Learning Based Framework for Mobile Energy Disseminator Dispatching to Charge On-the-Road Electric Vehicles
Aug 29, 2023The exponential growth of electric vehicles (EVs) presents novel challenges in preserving battery health and in addressing the persistent problem of vehicle range anxiety. To address these concerns, wireless charging, particularly, Mobile Energy Disseminators (MEDs) have emerged as a promising solution. The MED is mounted behind a large vehicle and charges all participating EVs within a radius upstream of it. Unfortuantely, during such V2V charging, the MED and EVs inadvertently form platoons, thereby occupying multiple lanes and impairing overall corridor travel efficiency. In addition, constrained budgets for MED deployment necessitate the development of an effective dispatching strategy to determine optimal timing and locations for introducing the MEDs into traffic. This paper proposes a deep reinforcement learning (DRL) based methodology to develop a vehicle dispatching framework. In the first component of the framework, we develop a realistic reinforcement learning environment termed "ChargingEnv" which incorporates a reliable charging simulation system that accounts for common practical issues in wireless charging deployment, specifically, the charging panel misalignment. The second component, the Proximal-Policy Optimization (PPO) agent, is trained to control MED dispatching through continuous interactions with ChargingEnv. Numerical experiments were carried out to demonstrate the demonstrate the efficacy of the proposed MED deployment decision processor. The experiment results suggest that the proposed model can significantly enhance EV travel range while efficiently deploying a optimal number of MEDs. The proposed model is found to be not only practical in its applicability but also has promises of real-world effectiveness. The proposed model can help travelers to maximize EV range and help road agencies or private-sector vendors to manage the deployment of MEDs efficiently.
Transfusor: Transformer Diffusor for Controllable Human-like Generation of Vehicle Lane Changing Trajectories
Aug 28, 2023



With ongoing development of autonomous driving systems and increasing desire for deployment, researchers continue to seek reliable approaches for ADS systems. The virtual simulation test (VST) has become a prominent approach for testing autonomous driving systems (ADS) and advanced driver assistance systems (ADAS) due to its advantages of fast execution, low cost, and high repeatability. However, the success of these simulation-based experiments heavily relies on the realism of the testing scenarios. It is needed to create more flexible and high-fidelity testing scenarios in VST in order to increase the safety and reliabilityof ADS and ADAS.To address this challenge, this paper introduces the "Transfusor" model, which leverages the transformer and diffusor models (two cutting-edge deep learning generative technologies). The primary objective of the Transfusor model is to generate highly realistic and controllable human-like lane-changing trajectories in highway scenarios. Extensive experiments were carried out, and the results demonstrate that the proposed model effectively learns the spatiotemporal characteristics of humans' lane-changing behaviors and successfully generates trajectories that closely mimic real-world human driving. As such, the proposed model can play a critical role of creating more flexible and high-fidelity testing scenarios in the VST, ultimately leading to safer and more reliable ADS and ADAS.
Development and testing of an image transformer for explainable autonomous driving systems
Oct 11, 2021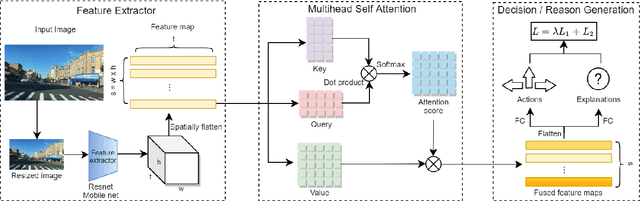

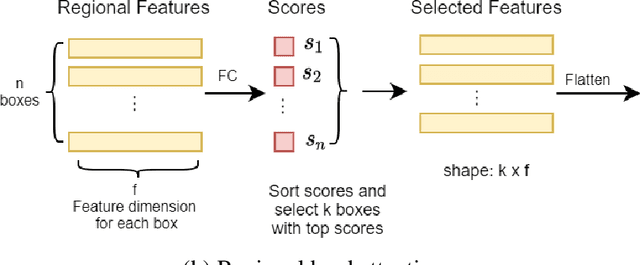

In the last decade, deep learning (DL) approaches have been used successfully in computer vision (CV) applications. However, DL-based CV models are generally considered to be black boxes due to their lack of interpretability. This black box behavior has exacerbated user distrust and therefore has prevented widespread deployment DLCV models in autonomous driving tasks even though some of these models exhibit superiority over human performance. For this reason, it is essential to develop explainable DL models for autonomous driving task. Explainable DL models can not only boost user trust in autonomy but also serve as a diagnostic approach to identify anydefects and weaknesses of the model during the system development phase. In this paper, we propose an explainable end-to-end autonomous driving system based on "Transformer", a state-of-the-art (SOTA) self-attention based model, to map visual features from images collected by onboard cameras to guide potential driving actions with corresponding explanations. The model achieves a soft attention over the global features of the image. The results demonstrate the efficacy of our proposed model as it exhibits superior performance (in terms of correct prediction of actions and explanations) compared to the benchmark model by a significant margin with lower computational cost.
Addressing crash-imminent situations caused by human driven vehicle errors in a mixed traffic stream: a model-based reinforcement learning approach for CAV
Oct 11, 2021

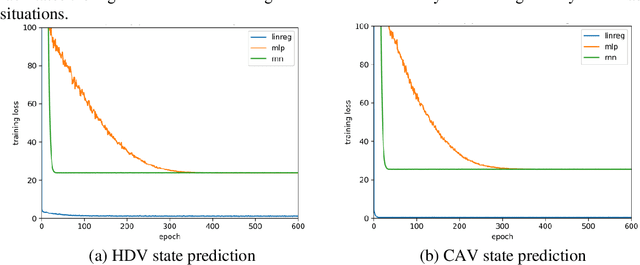
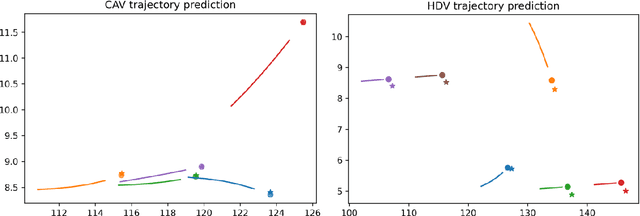
It is anticipated that the era of fully autonomous vehicle operations will be preceded by a lengthy "Transition Period" where the traffic stream will be mixed, that is, consisting of connected autonomous vehicles (CAVs), human-driven vehicles (HDVs) and connected human-driven vehicles (CHDVs). In recognition of the fact that public acceptance of CAVs will hinge on safety performance of automated driving systems, and that there will likely be safety challenges in the early part of the transition period, significant research efforts have been expended in the development of safety-conscious automated driving systems. Yet still, there appears to be a lacuna in the literature regarding the handling of the crash-imminent situations that are caused by errant human driven vehicles (HDVs) in the vicinity of the CAV during operations on the roadway. In this paper, we develop a simple model-based Reinforcement Learning (RL) based system that can be deployed in the CAV to generate trajectories that anticipate and avoid potential collisions caused by drivers of the HDVs. The model involves an end-to-end data-driven approach that contains a motion prediction model based on deep learning, and a fast trajectory planning algorithm based on model predictive control (MPC). The proposed system requires no prior knowledge or assumption about the physical environment including the vehicle dynamics, and therefore represents a general approach that can be deployed on any type of vehicle (e.g., truck, buse, motorcycle, etc.). The framework is trained and tested in the CARLA simulator with multiple collision imminent scenarios, and the results indicate the proposed model can avoid the collision at high successful rate (>85%) even in highly compact and dangerous situations.
Reason induced visual attention for explainable autonomous driving
Oct 11, 2021
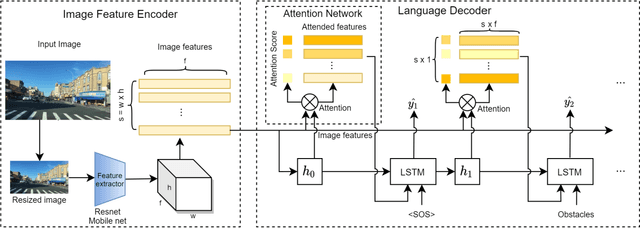
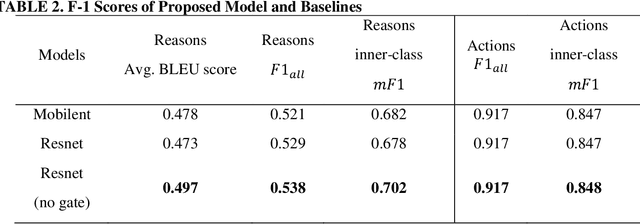
Deep learning (DL) based computer vision (CV) models are generally considered as black boxes due to poor interpretability. This limitation impedes efficient diagnoses or predictions of system failure, thereby precluding the widespread deployment of DLCV models in safety-critical tasks such as autonomous driving. This study is motivated by the need to enhance the interpretability of DL model in autonomous driving and therefore proposes an explainable DL-based framework that generates textual descriptions of the driving environment and makes appropriate decisions based on the generated descriptions. The proposed framework imitates the learning process of human drivers by jointly modeling the visual input (images) and natural language, while using the language to induce the visual attention in the image. The results indicate strong explainability of autonomous driving decisions obtained by focusing on relevant features from visual inputs. Furthermore, the output attention maps enhance the interpretability of the model not only by providing meaningful explanation to the model behavior but also by identifying the weakness of and potential improvement directions for the model.
Urban traffic dynamic rerouting framework: A DRL-based model with fog-cloud architecture
Oct 11, 2021
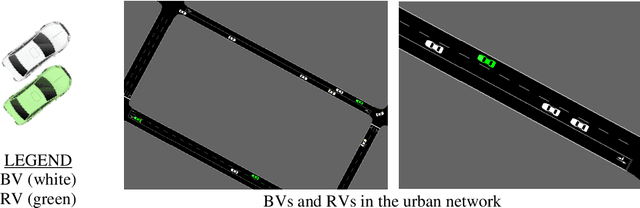
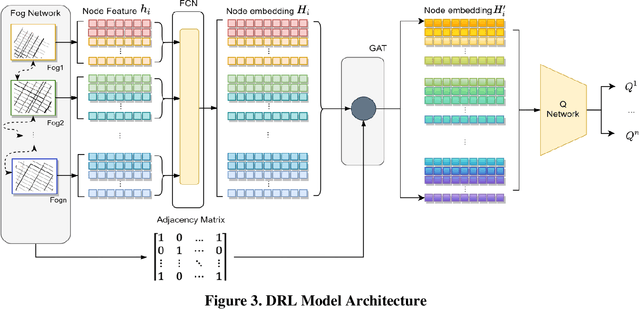
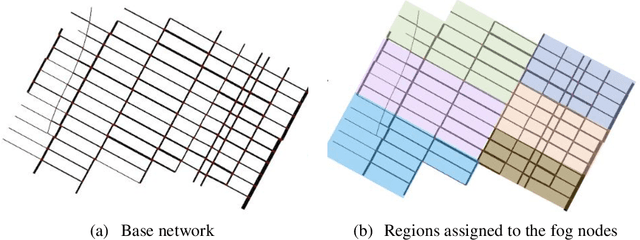
Past research and practice have demonstrated that dynamic rerouting framework is effective in mitigating urban traffic congestion and thereby improve urban travel efficiency. It has been suggested that dynamic rerouting could be facilitated using emerging technologies such as fog-computing which offer advantages of low-latency capabilities and information exchange between vehicles and roadway infrastructure. To address this question, this study proposes a two-stage model that combines GAQ (Graph Attention Network - Deep Q Learning) and EBkSP (Entropy Based k Shortest Path) using a fog-cloud architecture, to reroute vehicles in a dynamic urban environment and therefore to improve travel efficiency in terms of travel speed. First, GAQ analyzes the traffic conditions on each road and for each fog area, and then assigns a road index based on the information attention from both local and neighboring areas. Second, EBkSP assigns the route for each vehicle based on the vehicle priority and route popularity. A case study experiment is carried out to investigate the efficacy of the proposed model. At the model training stage, different methods are used to establish the vehicle priorities, and their impact on the results is assessed. Also, the proposed model is tested under various scenarios with different ratios of rerouting and background (non-rerouting) vehicles. The results demonstrate that vehicle rerouting using the proposed model can help attain higher speed and reduces possibility of severe congestion. This result suggests that the proposed model can be deployed by urban transportation agencies for dynamic rerouting and ultimately, to reduce urban traffic congestion.
A DRL-based Multiagent Cooperative Control Framework for CAV Networks: a Graphic Convolution Q Network
Oct 12, 2020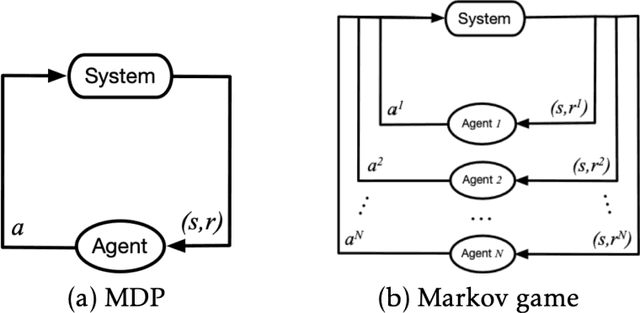

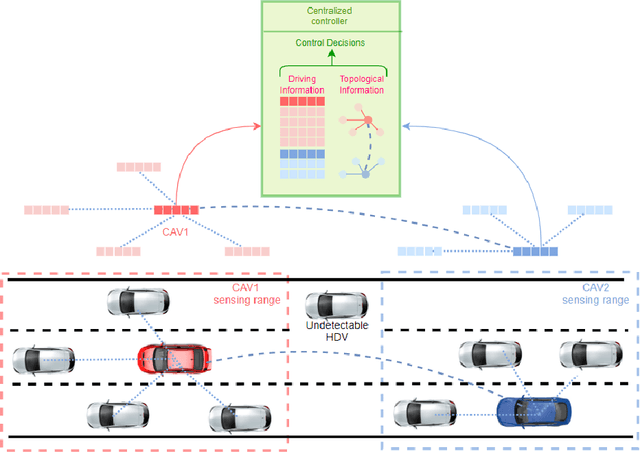
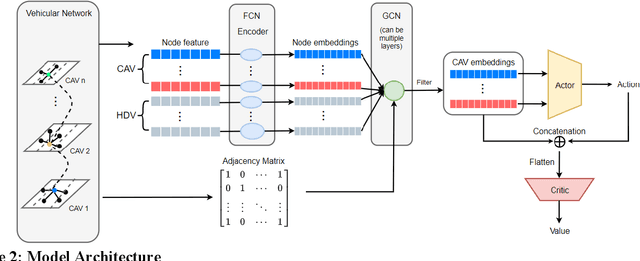
Connected Autonomous Vehicle (CAV) Network can be defined as a collection of CAVs operating at different locations on a multilane corridor, which provides a platform to facilitate the dissemination of operational information as well as control instructions. Cooperation is crucial in CAV operating systems since it can greatly enhance operation in terms of safety and mobility, and high-level cooperation between CAVs can be expected by jointly plan and control within CAV network. However, due to the highly dynamic and combinatory nature such as dynamic number of agents (CAVs) and exponentially growing joint action space in a multiagent driving task, achieving cooperative control is NP hard and cannot be governed by any simple rule-based methods. In addition, existing literature contains abundant information on autonomous driving's sensing technology and control logic but relatively little guidance on how to fuse the information acquired from collaborative sensing and build decision processor on top of fused information. In this paper, a novel Deep Reinforcement Learning (DRL) based approach combining Graphic Convolution Neural Network (GCN) and Deep Q Network (DQN), namely Graphic Convolution Q network (GCQ) is proposed as the information fusion module and decision processor. The proposed model can aggregate the information acquired from collaborative sensing and output safe and cooperative lane changing decisions for multiple CAVs so that individual intention can be satisfied even under a highly dynamic and partially observed mixed traffic. The proposed algorithm can be deployed on centralized control infrastructures such as road-side units (RSU) or cloud platforms to improve the CAV operation.
Leveraging the Capabilities of Connected and Autonomous Vehicles and Multi-Agent Reinforcement Learning to Mitigate Highway Bottleneck Congestion
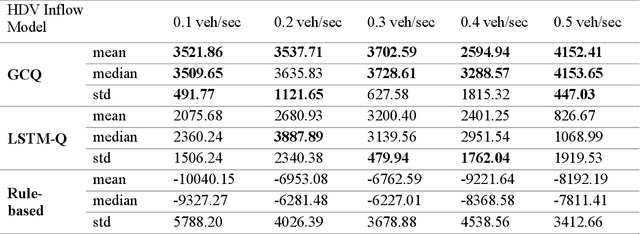
Oct 12, 2020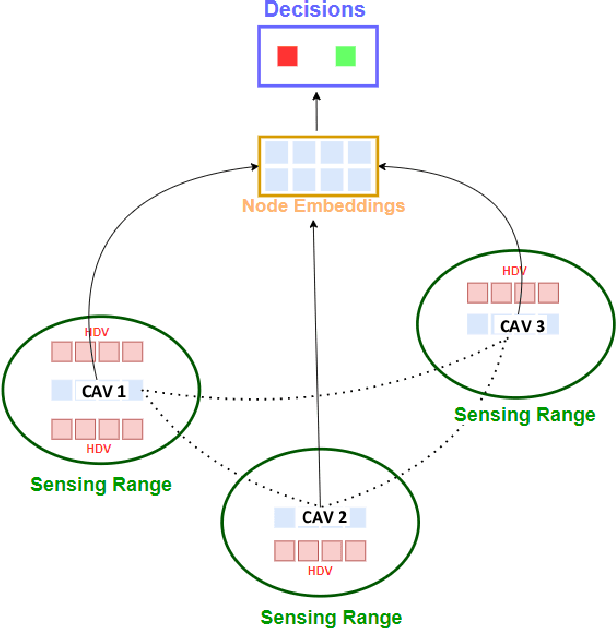
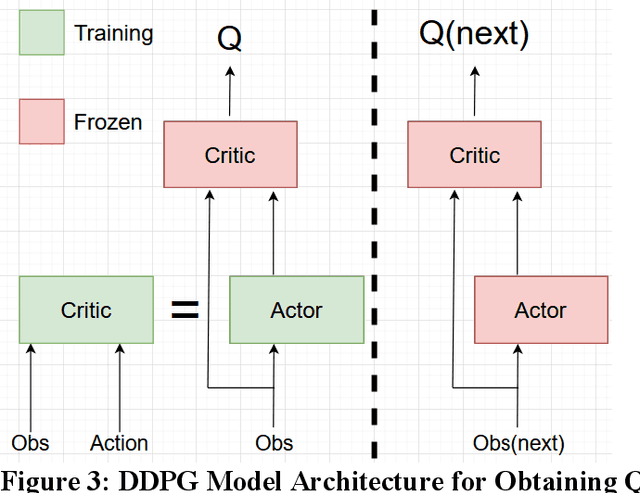

Active Traffic Management strategies are often adopted in real-time to address such sudden flow breakdowns. When queuing is imminent, Speed Harmonization (SH), which adjusts speeds in upstream traffic to mitigate traffic showckwaves downstream, can be applied. However, because SH depends on driver awareness and compliance, it may not always be effective in mitigating congestion. The use of multiagent reinforcement learning for collaborative learning, is a promising solution to this challenge. By incorporating this technique in the control algorithms of connected and autonomous vehicle (CAV), it may be possible to train the CAVs to make joint decisions that can mitigate highway bottleneck congestion without human driver compliance to altered speed limits. In this regard, we present an RL-based multi-agent CAV control model to operate in mixed traffic (both CAVs and human-driven vehicles (HDVs)). The results suggest that even at CAV percent share of corridor traffic as low as 10%, CAVs can significantly mitigate bottlenecks in highway traffic. Another objective was to assess the efficacy of the RL-based controller vis-\`a-vis that of the rule-based controller. In addressing this objective, we duly recognize that one of the main challenges of RL-based CAV controllers is the variety and complexity of inputs that exist in the real world, such as the information provided to the CAV by other connected entities and sensed information. These translate as dynamic length inputs which are difficult to process and learn from. For this reason, we propose the use of Graphical Convolution Networks (GCN), a specific RL technique, to preserve information network topology and corresponding dynamic length inputs. We then use this, combined with Deep Deterministic Policy Gradient (DDPG), to carry out multi-agent training for congestion mitigation using the CAV controllers.