 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFL-LSTR: A privacy-preserving framework for driver intention inference based on in-vehicle and out-vehicle information
Sep 02, 2023



Intelligent vehicle anticipation of the movement intentions of other drivers can reduce collisions. Typically, when a human driver of another vehicle (referred to as the target vehicle) engages in specific behaviors such as checking the rearview mirror prior to lane change, a valuable clue is therein provided on the intentions of the target vehicle's driver. Furthermore, the target driver's intentions can be influenced and shaped by their driving environment. For example, if the target vehicle is too close to a leading vehicle, it may renege the lane change decision. On the other hand, a following vehicle in the target lane is too close to the target vehicle could lead to its reversal of the decision to change lanes. Knowledge of such intentions of all vehicles in a traffic stream can help enhance traffic safety. Unfortunately, such information is often captured in the form of images/videos. Utilization of personally identifiable data to train a general model could violate user privacy. Federated Learning (FL) is a promising tool to resolve this conundrum. FL efficiently trains models without exposing the underlying data. This paper introduces a Personalized Federated Learning (PFL) model embedded a long short-term transformer (LSTR) framework. The framework predicts drivers' intentions by leveraging in-vehicle videos (of driver movement, gestures, and expressions) and out-of-vehicle videos (of the vehicle's surroundings - frontal/rear areas). The proposed PFL-LSTR framework is trained and tested through real-world driving data collected from human drivers at Interstate 65 in Indiana. The results suggest that the PFL-LSTR exhibits high adaptability and high precision, and that out-of-vehicle information (particularly, the driver's rear-mirror viewing actions) is important because it helps reduce false positives and thereby enhances the precision of driver intention inference.
Scalable Traffic Signal Controls using Fog-Cloud Based Multiagent Reinforcement Learning
Oct 11, 2021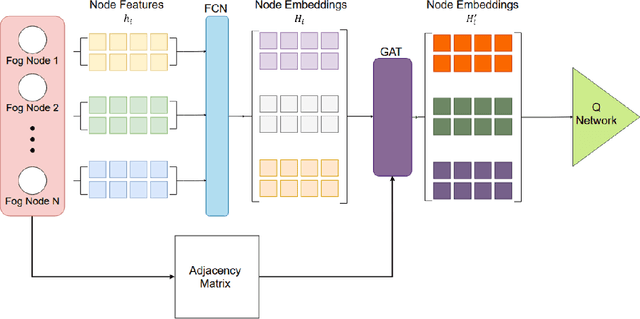
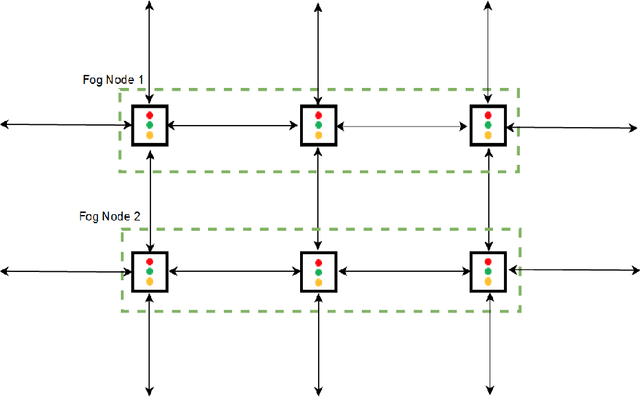
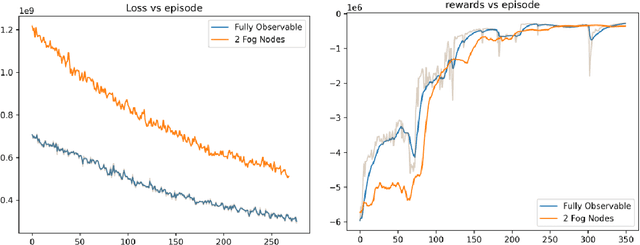
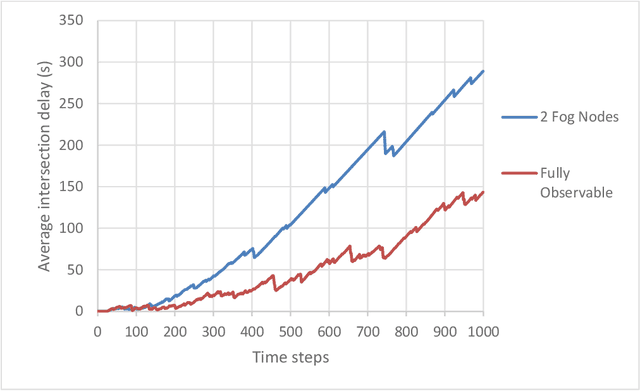
Optimizing traffic signal control (TSC) at intersections continues to pose a challenging problem, particularly for large-scale traffic networks. It has been shown in past research that it is feasible to optimize the operations of individual TSC systems or a small number of such systems. However, it has been computationally difficult to scale these solution approaches to large networks partly due to the curse of dimensionality that is encountered as the number of intersections increases. Fortunately, recent studies have recognized the potential of exploiting advancements in deep and reinforcement learning to address this problem, and some preliminary successes have been achieved in this regard. However, facilitating such intelligent solution approaches may require large amounts of infrastructural investments such as roadside units (RSUs) and drones in order to ensure thorough connectivity across all intersections in large networks, an investment that may be burdensome for agencies to undertake. As such, this study builds on recent work to present a scalable TSC model that may reduce the number of required enabling infrastructure. This is achieved using graph attention networks (GATs) to serve as the neural network for deep reinforcement learning, which aids in maintaining the graph topology of the traffic network while disregarding any irrelevant or unnecessary information. A case study is carried out to demonstrate the effectiveness of the proposed model, and the results show much promise. The overall research outcome suggests that by decomposing large networks using fog-nodes, the proposed fog-based graphic RL (FG-RL) model can be easily applied to scale into larger traffic networks.
Reason induced visual attention for explainable autonomous driving
Oct 11, 2021
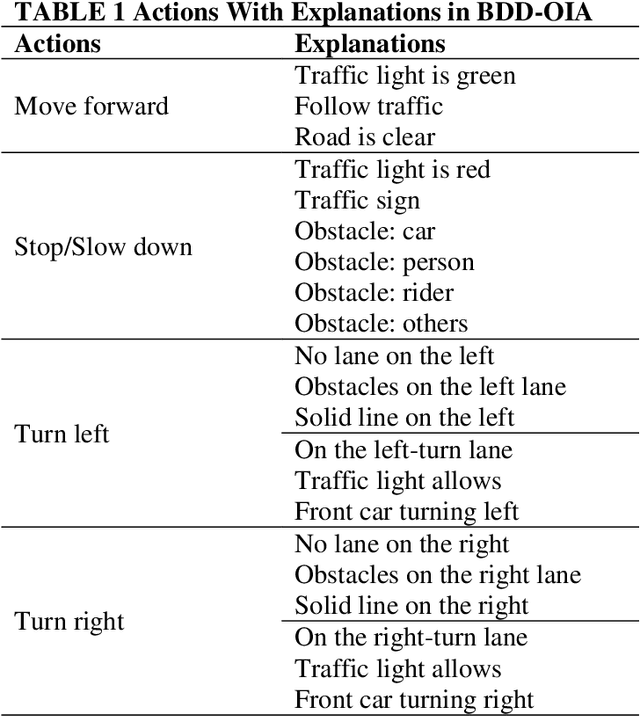
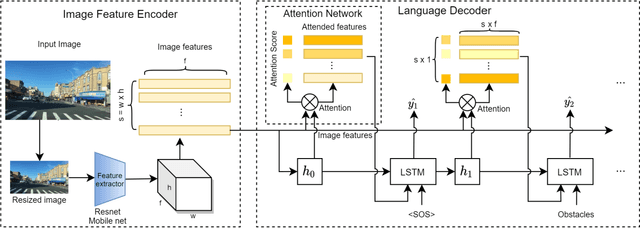
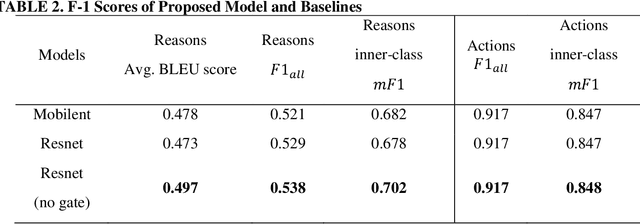
Deep learning (DL) based computer vision (CV) models are generally considered as black boxes due to poor interpretability. This limitation impedes efficient diagnoses or predictions of system failure, thereby precluding the widespread deployment of DLCV models in safety-critical tasks such as autonomous driving. This study is motivated by the need to enhance the interpretability of DL model in autonomous driving and therefore proposes an explainable DL-based framework that generates textual descriptions of the driving environment and makes appropriate decisions based on the generated descriptions. The proposed framework imitates the learning process of human drivers by jointly modeling the visual input (images) and natural language, while using the language to induce the visual attention in the image. The results indicate strong explainability of autonomous driving decisions obtained by focusing on relevant features from visual inputs. Furthermore, the output attention maps enhance the interpretability of the model not only by providing meaningful explanation to the model behavior but also by identifying the weakness of and potential improvement directions for the model.
Urban traffic dynamic rerouting framework: A DRL-based model with fog-cloud architecture
Oct 11, 2021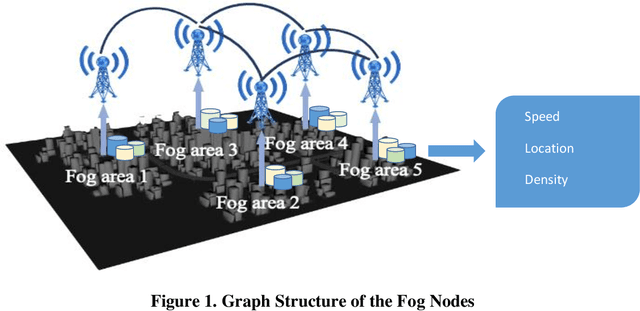
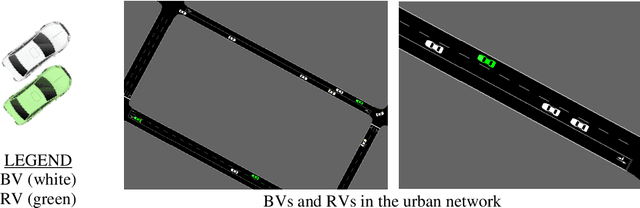
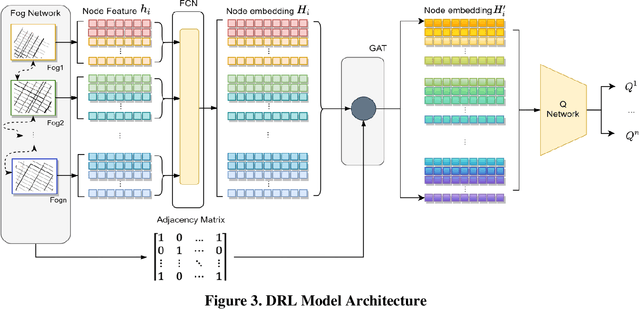
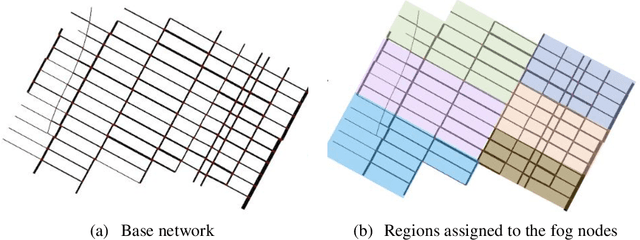
Past research and practice have demonstrated that dynamic rerouting framework is effective in mitigating urban traffic congestion and thereby improve urban travel efficiency. It has been suggested that dynamic rerouting could be facilitated using emerging technologies such as fog-computing which offer advantages of low-latency capabilities and information exchange between vehicles and roadway infrastructure. To address this question, this study proposes a two-stage model that combines GAQ (Graph Attention Network - Deep Q Learning) and EBkSP (Entropy Based k Shortest Path) using a fog-cloud architecture, to reroute vehicles in a dynamic urban environment and therefore to improve travel efficiency in terms of travel speed. First, GAQ analyzes the traffic conditions on each road and for each fog area, and then assigns a road index based on the information attention from both local and neighboring areas. Second, EBkSP assigns the route for each vehicle based on the vehicle priority and route popularity. A case study experiment is carried out to investigate the efficacy of the proposed model. At the model training stage, different methods are used to establish the vehicle priorities, and their impact on the results is assessed. Also, the proposed model is tested under various scenarios with different ratios of rerouting and background (non-rerouting) vehicles. The results demonstrate that vehicle rerouting using the proposed model can help attain higher speed and reduces possibility of severe congestion. This result suggests that the proposed model can be deployed by urban transportation agencies for dynamic rerouting and ultimately, to reduce urban traffic congestion.
Leveraging the Capabilities of Connected and Autonomous Vehicles and Multi-Agent Reinforcement Learning to Mitigate Highway Bottleneck Congestion
Oct 12, 2020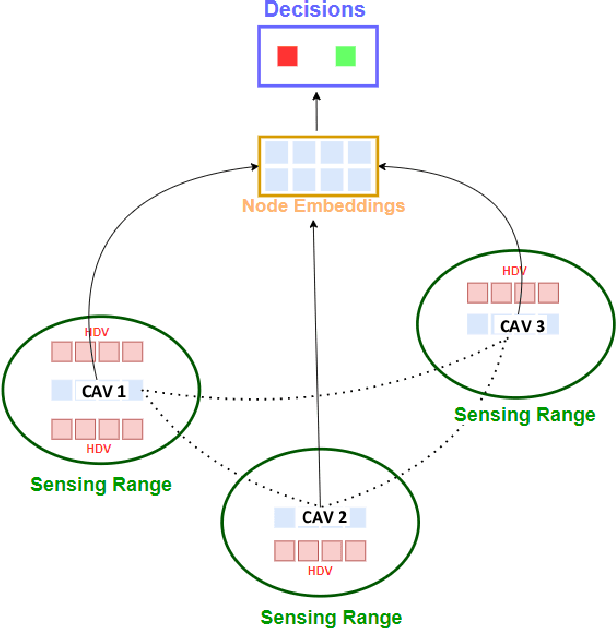
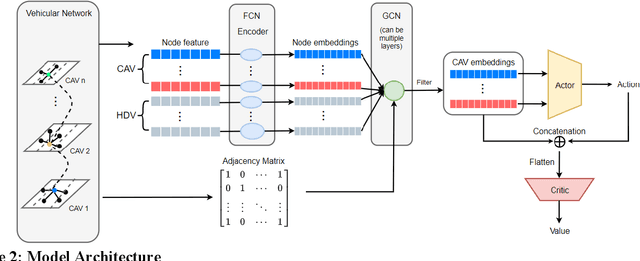
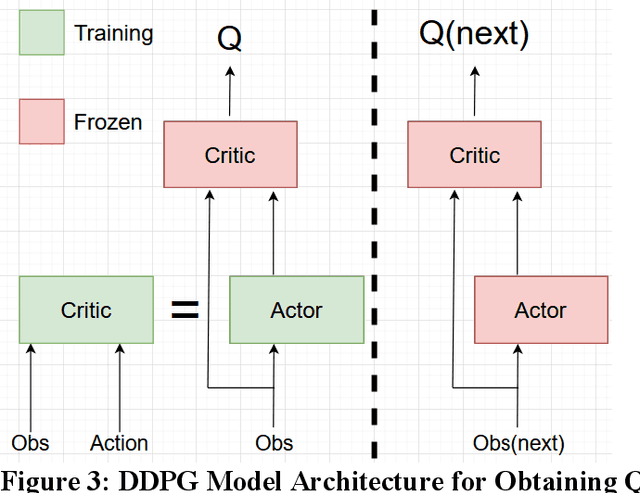

Active Traffic Management strategies are often adopted in real-time to address such sudden flow breakdowns. When queuing is imminent, Speed Harmonization (SH), which adjusts speeds in upstream traffic to mitigate traffic showckwaves downstream, can be applied. However, because SH depends on driver awareness and compliance, it may not always be effective in mitigating congestion. The use of multiagent reinforcement learning for collaborative learning, is a promising solution to this challenge. By incorporating this technique in the control algorithms of connected and autonomous vehicle (CAV), it may be possible to train the CAVs to make joint decisions that can mitigate highway bottleneck congestion without human driver compliance to altered speed limits. In this regard, we present an RL-based multi-agent CAV control model to operate in mixed traffic (both CAVs and human-driven vehicles (HDVs)). The results suggest that even at CAV percent share of corridor traffic as low as 10%, CAVs can significantly mitigate bottlenecks in highway traffic. Another objective was to assess the efficacy of the RL-based controller vis-\`a-vis that of the rule-based controller. In addressing this objective, we duly recognize that one of the main challenges of RL-based CAV controllers is the variety and complexity of inputs that exist in the real world, such as the information provided to the CAV by other connected entities and sensed information. These translate as dynamic length inputs which are difficult to process and learn from. For this reason, we propose the use of Graphical Convolution Networks (GCN), a specific RL technique, to preserve information network topology and corresponding dynamic length inputs. We then use this, combined with Deep Deterministic Policy Gradient (DDPG), to carry out multi-agent training for congestion mitigation using the CAV controllers.
Facilitating Connected Autonomous Vehicle Operations Using Space-weighted Information Fusion and Deep Reinforcement Learning Based Control
Sep 30, 2020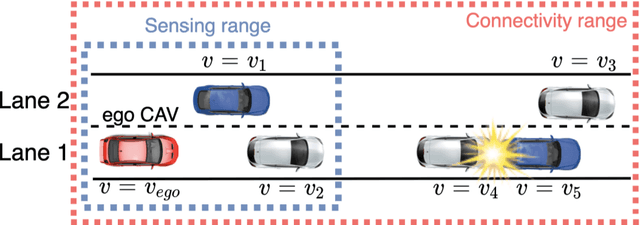
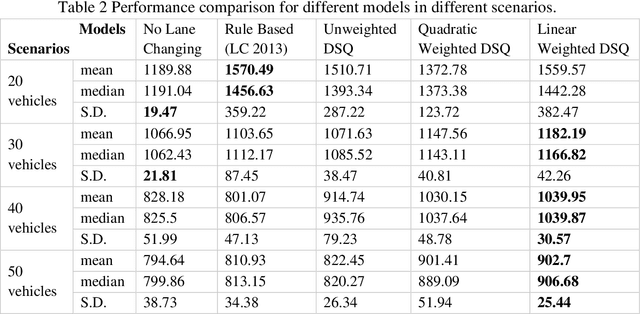
The connectivity aspect of connected autonomous vehicles (CAV) is beneficial because it facilitates dissemination of traffic-related information to vehicles through Vehicle-to-External (V2X) communication. Onboard sensing equipment including LiDAR and camera can reasonably characterize the traffic environment in the immediate locality of the CAV. However, their performance is limited by their sensor range (SR). On the other hand, longer-range information is helpful for characterizing imminent conditions downstream. By contemporaneously coalescing the short- and long-range information, the CAV can construct comprehensively its surrounding environment and thereby facilitate informed, safe, and effective movement planning in the short-term (local decisions including lane change) and long-term (route choice). In this paper, we describe a Deep Reinforcement Learning based approach that integrates the data collected through sensing and connectivity capabilities from other vehicles located in the proximity of the CAV and from those located further downstream, and we use the fused data to guide lane changing, a specific context of CAV operations. In addition, recognizing the importance of the connectivity range (CR) to the performance of not only the algorithm but also of the vehicle in the actual driving environment, the paper carried out a case study. The case study demonstrates the application of the proposed algorithm and duly identifies the appropriate CR for each level of prevailing traffic density. It is expected that implementation of the algorithm in CAVs can enhance the safety and mobility associated with CAV driving operations. From a general perspective, its implementation can provide guidance to connectivity equipment manufacturers and CAV operators, regarding the default CR settings for CAVs or the recommended CR setting in a given traffic environment.