 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing UAVs for vehicle tracking and collision risk assessment at intersections
Oct 11, 2021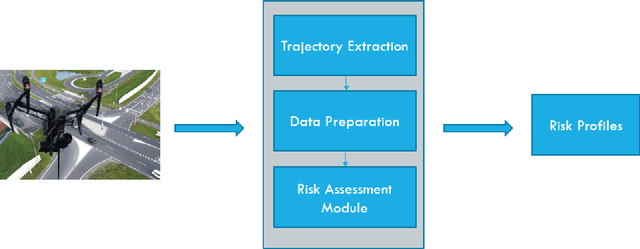
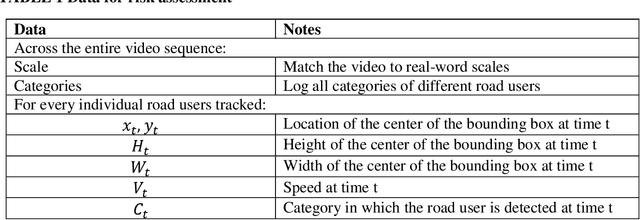
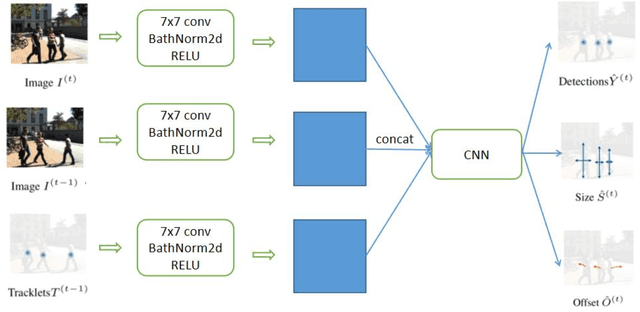

Assessing collision risk is a critical challenge to effective traffic safety management. The deployment of unmanned aerial vehicles (UAVs) to address this issue has shown much promise, given their wide visual field and movement flexibility. This research demonstrates the application of UAVs and V2X connectivity to track the movement of road users and assess potential collisions at intersections. The study uses videos captured by UAVs. The proposed method combines deep-learning based tracking algorithms and time-to-collision tasks. The results not only provide beneficial information for vehicle's recognition of potential crashes and motion planning but also provided a valuable tool for urban road agencies and safety management engineers.
Towards Safer Transportation: a self-supervised learning approach for traffic video deraining
Oct 11, 2021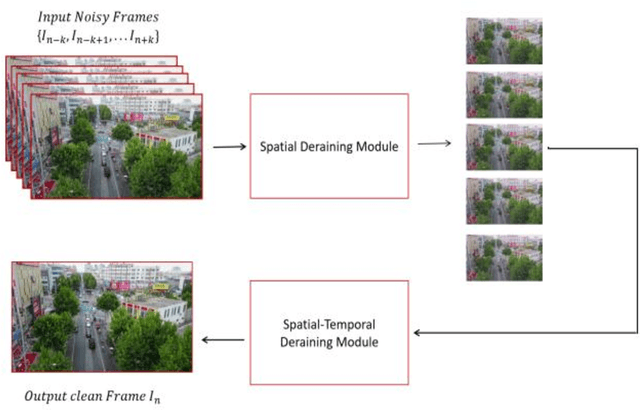
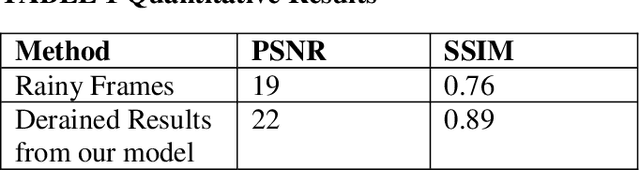
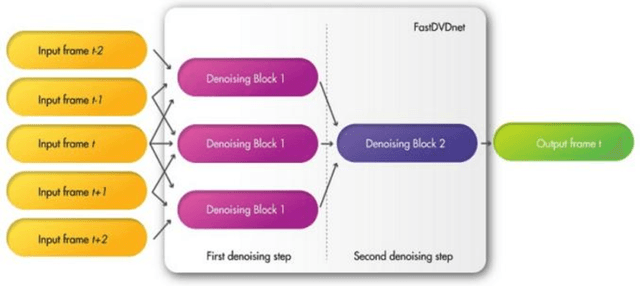

Video monitoring of traffic is useful for traffic management and control, traffic counting, and traffic law enforcement. However, traffic monitoring during inclement weather such as rain is a challenging task because video quality is corrupted by streaks of falling rain on the video image, and this hinders reliable characterization not only of the road environment but also of road-user behavior during such adverse weather events. This study proposes a two-stage self-supervised learning method to remove rain streaks in traffic videos. The first and second stages address intra- and inter-frame noise, respectively. The results indicated that the model exhibits satisfactory performance in terms of the image visual quality and the Peak Signal-Noise Ratio value.
Development and testing of an image transformer for explainable autonomous driving systems
Oct 11, 2021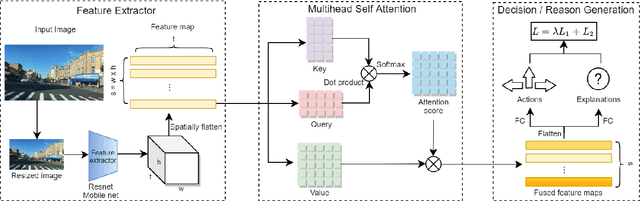

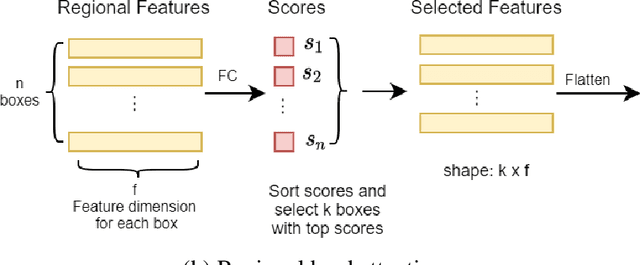

In the last decade, deep learning (DL) approaches have been used successfully in computer vision (CV) applications. However, DL-based CV models are generally considered to be black boxes due to their lack of interpretability. This black box behavior has exacerbated user distrust and therefore has prevented widespread deployment DLCV models in autonomous driving tasks even though some of these models exhibit superiority over human performance. For this reason, it is essential to develop explainable DL models for autonomous driving task. Explainable DL models can not only boost user trust in autonomy but also serve as a diagnostic approach to identify anydefects and weaknesses of the model during the system development phase. In this paper, we propose an explainable end-to-end autonomous driving system based on "Transformer", a state-of-the-art (SOTA) self-attention based model, to map visual features from images collected by onboard cameras to guide potential driving actions with corresponding explanations. The model achieves a soft attention over the global features of the image. The results demonstrate the efficacy of our proposed model as it exhibits superior performance (in terms of correct prediction of actions and explanations) compared to the benchmark model by a significant margin with lower computational cost.