 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Multimodal Model Architectures
Paper and Code
May 28, 2024
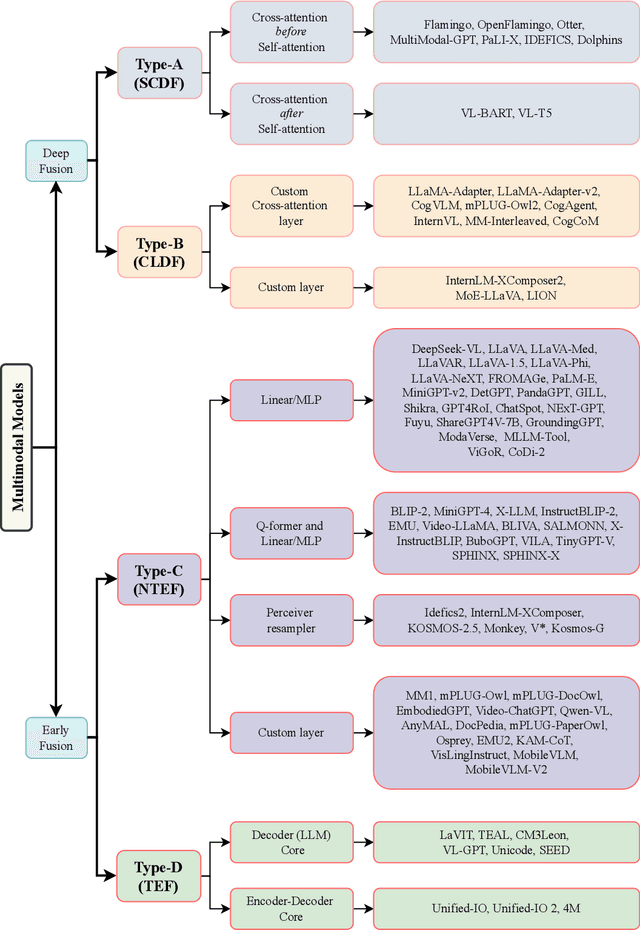
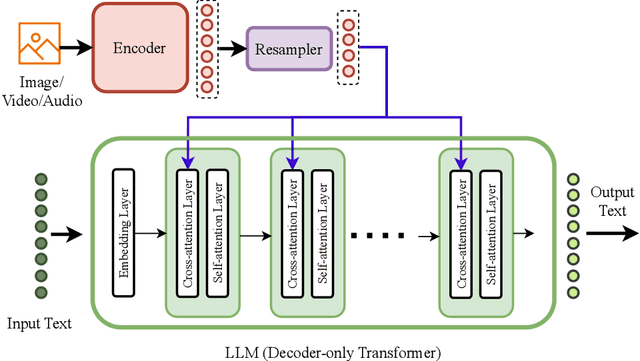
This work uniquely identifies and characterizes four prevalent multimodal model architectural patterns in the contemporary multimodal landscape. Systematically categorizing models by architecture type facilitates monitoring of developments in the multimodal domain. Distinct from recent survey papers that present general information on multimodal architectures, this research conducts a comprehensive exploration of architectural details and identifies four specific architectural types. The types are distinguished by their respective methodologies for integrating multimodal inputs into the deep neural network model. The first two types (Type A and B) deeply fuses multimodal inputs within the internal layers of the model, whereas the following two types (Type C and D) facilitate early fusion at the input stage. Type-A employs standard cross-attention, whereas Type-B utilizes custom-designed layers for modality fusion within the internal layers. On the other hand, Type-C utilizes modality-specific encoders, while Type-D leverages tokenizers to process the modalities at the model's input stage. The identified architecture types aid the monitoring of any-to-any multimodal model development. Notably, Type-C and Type-D are currently favored in the construction of any-to-any multimodal models. Type-C, distinguished by its non-tokenizing multimodal model architecture, is emerging as a viable alternative to Type-D, which utilizes input-tokenizing techniques. To assist in model selection, this work highlights the advantages and disadvantages of each architecture type based on data and compute requirements, architecture complexity, scalability, simplification of adding modalities, training objectives, and any-to-any multimodal generation capability.