 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Deep Learning Models for Custom Hardware Accelerators
Paper and Code
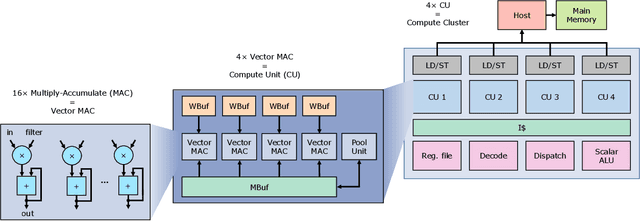
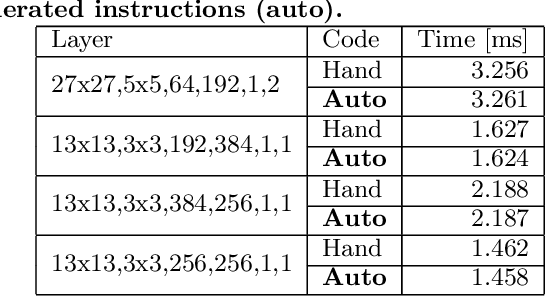

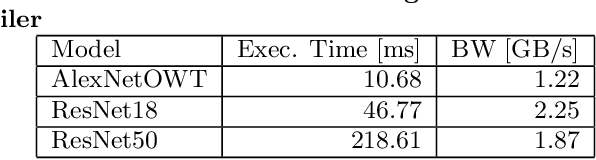
Convolutional neural networks (CNNs) are the core of most state-of-the-art deep learning algorithms specialized for object detection and classification. CNNs are both computationally complex and embarrassingly parallel. Two properties that leave room for potential software and hardware optimizations for embedded systems. Given a programmable hardware accelerator with a CNN oriented custom instructions set, the compiler's task is to exploit the hardware's full potential, while abiding with the hardware constraints and maintaining generality to run different CNN models with varying workload properties. Snowflake is an efficient and scalable hardware accelerator implemented on programmable logic devices. It implements a control pipeline for a custom instruction set. The goal of this paper is to present Snowflake's compiler that generates machine level instructions from Torch7 model description files. The main software design points explored in this work are: model structure parsing, CNN workload breakdown, loop rearrangement for memory bandwidth optimizations and memory access balancing. The performance achieved by compiler generated instructions matches against hand optimized code for convolution layers. Generated instructions also efficiently execute AlexNet and ResNet18 inference on Snowflake. Snowflake with $256$ processing units was synthesized on Xilinx's Zynq XC7Z045 FPGA. At $250$ MHz, AlexNet achieved in $93.6$ frames/s and $1.2$ GB/s of off-chip memory bandwidth, and $21.4$ frames/s and $2.2$ GB/s for ResNet18. Total on-chip power is $5$ W.