 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Networks Hardware Implementation on FPGA
Mar 04, 2016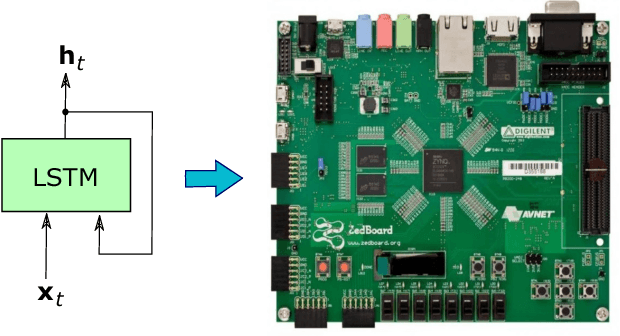
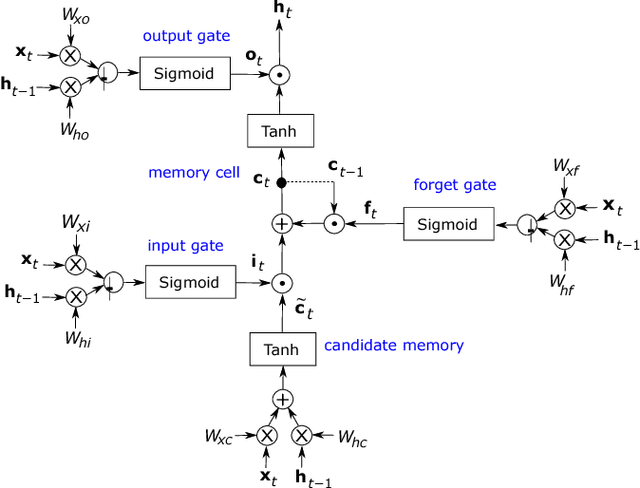
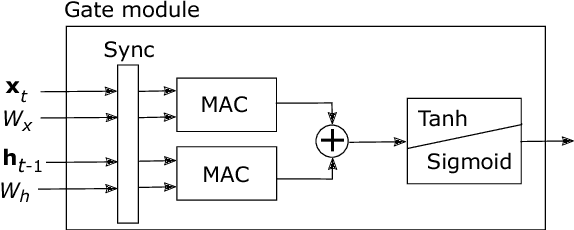
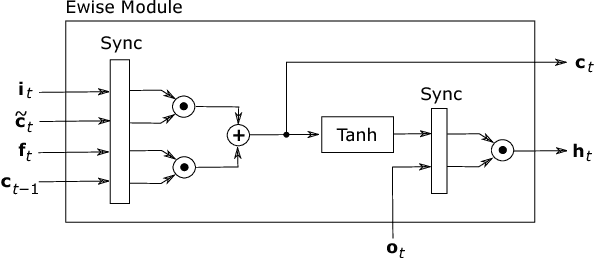
Recurrent Neural Networks (RNNs) have the ability to retain memory and learn data sequences. Due to the recurrent nature of RNNs, it is sometimes hard to parallelize all its computations on conventional hardware. CPUs do not currently offer large parallelism, while GPUs offer limited parallelism due to sequential components of RNN models. In this paper we present a hardware implementation of Long-Short Term Memory (LSTM) recurrent network on the programmable logic Zynq 7020 FPGA from Xilinx. We implemented a RNN with $2$ layers and $128$ hidden units in hardware and it has been tested using a character level language model. The implementation is more than $21\times$ faster than the ARM CPU embedded on the Zynq 7020 FPGA. This work can potentially evolve to a RNN co-processor for future mobile devices.