 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsule Network Performance with Autonomous Navigation
Paper and Code
Feb 08, 2020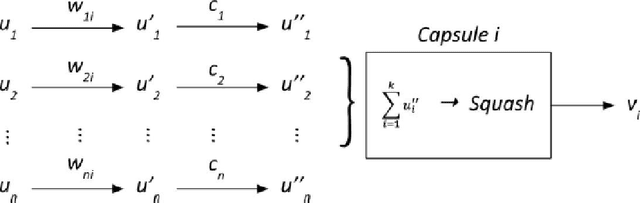


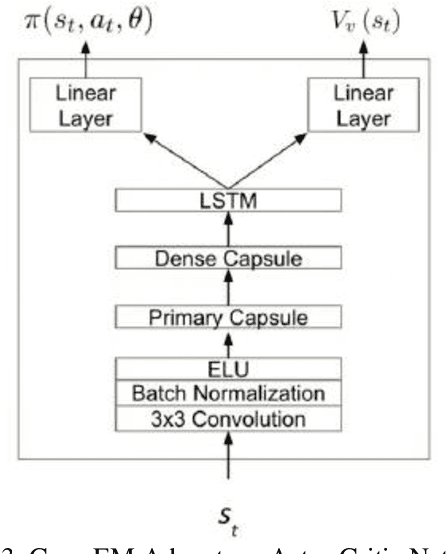
Capsule Networks (CapsNets) have been proposed as an alternative to Convolutional Neural Networks (CNNs). This paper showcases how CapsNets are more capable than CNNs for autonomous agent exploration of realistic scenarios. In real world navigation, rewards external to agents may be rare. In turn, reinforcement learning algorithms can struggle to form meaningful policy functions. This paper's approach Capsules Exploration Module (Caps-EM) pairs a CapsNets architecture with an Advantage Actor Critic algorithm. Other approaches for navigating sparse environments require intrinsic reward generators, such as the Intrinsic Curiosity Module (ICM) and Augmented Curiosity Modules (ACM). Caps-EM uses a more compact architecture without need for intrinsic rewards. Tested using ViZDoom, the Caps-EM uses 44% and 83% fewer trainable network parameters than the ICM and Depth-Augmented Curiosity Module (D-ACM), respectively, for 1141% and 437% average time improvement over the ICM and D-ACM, respectively, for converging to a policy function across "My Way Home" scenarios.