 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024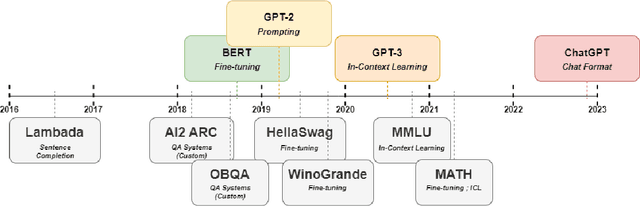
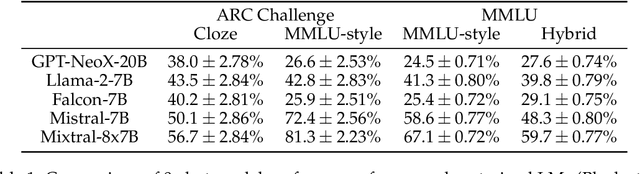
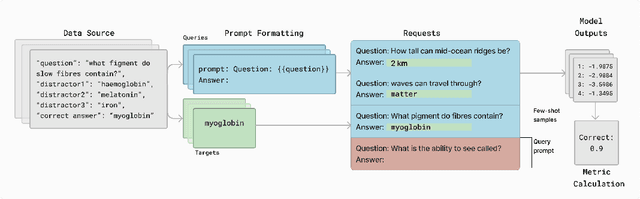

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
The Update Equivalence Framework for Decision-Time Planning
Apr 25, 2023



The process of revising (or constructing) a policy immediately prior to execution -- known as decision-time planning -- is key to achieving superhuman performance in perfect-information settings like chess and Go. A recent line of work has extended decision-time planning to more general imperfect-information settings, leading to superhuman performance in poker. However, these methods requires considering subgames whose sizes grow quickly in the amount of non-public information, making them unhelpful when the amount of non-public information is large. Motivated by this issue, we introduce an alternative framework for decision-time planning that is not based on subgames but rather on the notion of update equivalence. In this framework, decision-time planning algorithms simulate updates of synchronous learning algorithms. This framework enables us to introduce a new family of principled decision-time planning algorithms that do not rely on public information, opening the door to sound and effective decision-time planning in settings with large amounts of non-public information. In experiments, members of this family produce comparable or superior results compared to state-of-the-art approaches in Hanabi and improve performance in 3x3 Abrupt Dark Hex and Phantom Tic-Tac-Toe.
Bayesian Opponent Modeling in Multiplayer Imperfect-Information Games
Dec 12, 2022



In many real-world settings agents engage in strategic interactions with multiple opposing agents who can employ a wide variety of strategies. The standard approach for designing agents for such settings is to compute or approximate a relevant game-theoretic solution concept such as Nash equilibrium and then follow the prescribed strategy. However, such a strategy ignores any observations of opponents' play, which may indicate shortcomings that can be exploited. We present an approach for opponent modeling in multiplayer imperfect-information games where we collect observations of opponents' play through repeated interactions. We run experiments against a wide variety of real opponents and exact Nash equilibrium strategies in three-player Kuhn poker and show that our algorithm significantly outperforms all of the agents, including the exact Nash equilibrium strategies.