 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Compute Trustworthy Sentiment Scores from Bloomberg Market Wraps?
Jan 09, 2024



We used a dataset of daily Bloomberg Financial Market Summaries from 2010 to 2023, reposted on large financial media, to determine how global news headlines may affect stock market movements using ChatGPT and a two-stage prompt approach. We document a statistically significant positive correlation between the sentiment score and future equity market returns over short to medium term, which reverts to a negative correlation over longer horizons. Validation of this correlation pattern across multiple equity markets indicates its robustness across equity regions and resilience to non-linearity, evidenced by comparison of Pearson and Spearman correlations. Finally, we provide an estimate of the optimal horizon that strikes a balance between reactivity to new information and correlation.
Adaptive learning for financial markets mixing model-based and model-free RL for volatility targeting
Apr 22, 2021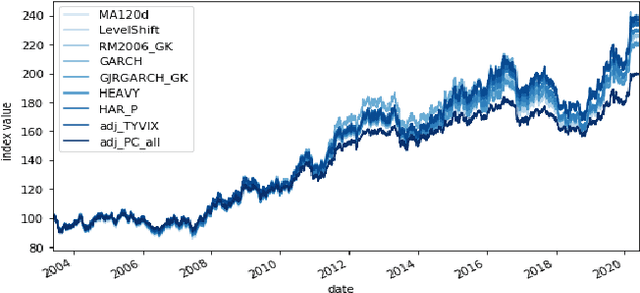

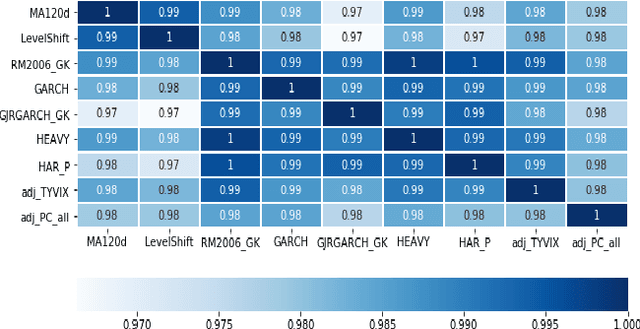

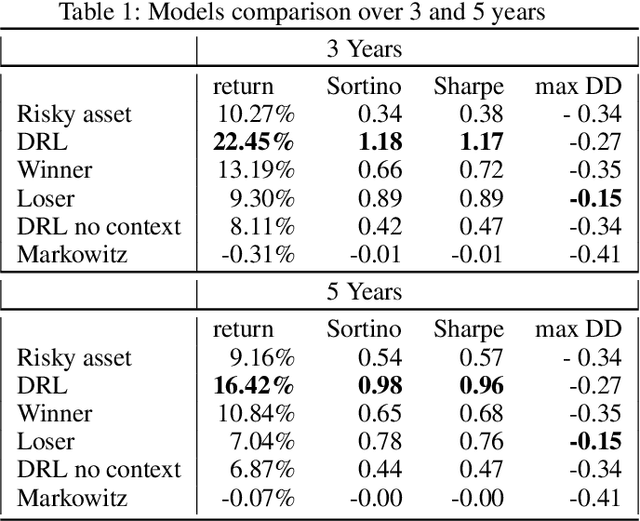
Model-Free Reinforcement Learning has achieved meaningful results in stable environments but, to this day, it remains problematic in regime changing environments like financial markets. In contrast, model-based RL is able to capture some fundamental and dynamical concepts of the environment but suffer from cognitive bias. In this work, we propose to combine the best of the two techniques by selecting various model-based approaches thanks to Model-Free Deep Reinforcement Learning. Using not only past performance and volatility, we include additional contextual information such as macro and risk appetite signals to account for implicit regime changes. We also adapt traditional RL methods to real-life situations by considering only past data for the training sets. Hence, we cannot use future information in our training data set as implied by K-fold cross validation. Building on traditional statistical methods, we use the traditional "walk-forward analysis", which is defined by successive training and testing based on expanding periods, to assert the robustness of the resulting agent. Finally, we present the concept of statistical difference's significance based on a two-tailed T-test, to highlight the ways in which our models differ from more traditional ones. Our experimental results show that our approach outperforms traditional financial baseline portfolio models such as the Markowitz model in almost all evaluation metrics commonly used in financial mathematics, namely net performance, Sharpe and Sortino ratios, maximum drawdown, maximum drawdown over volatility.
Bridging the gap between Markowitz planning and deep reinforcement learning
Sep 30, 2020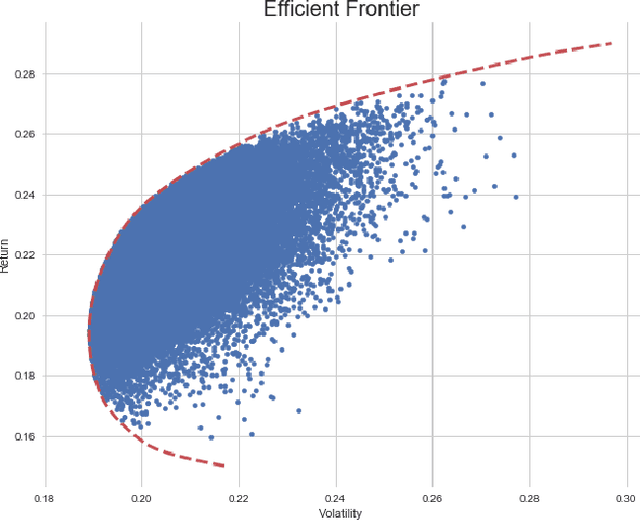
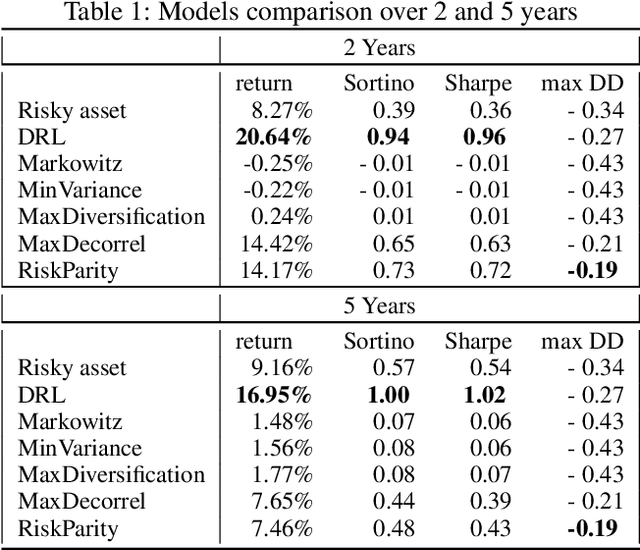
While researchers in the asset management industry have mostly focused on techniques based on financial and risk planning techniques like Markowitz efficient frontier, minimum variance, maximum diversification or equal risk parity, in parallel, another community in machine learning has started working on reinforcement learning and more particularly deep reinforcement learning to solve other decision making problems for challenging task like autonomous driving, robot learning, and on a more conceptual side games solving like Go. This paper aims to bridge the gap between these two approaches by showing Deep Reinforcement Learning (DRL) techniques can shed new lights on portfolio allocation thanks to a more general optimization setting that casts portfolio allocation as an optimal control problem that is not just a one-step optimization, but rather a continuous control optimization with a delayed reward. The advantages are numerous: (i) DRL maps directly market conditions to actions by design and hence should adapt to changing environment, (ii) DRL does not rely on any traditional financial risk assumptions like that risk is represented by variance, (iii) DRL can incorporate additional data and be a multi inputs method as opposed to more traditional optimization methods. We present on an experiment some encouraging results using convolution networks.
AAMDRL: Augmented Asset Management with Deep Reinforcement Learning
Sep 30, 2020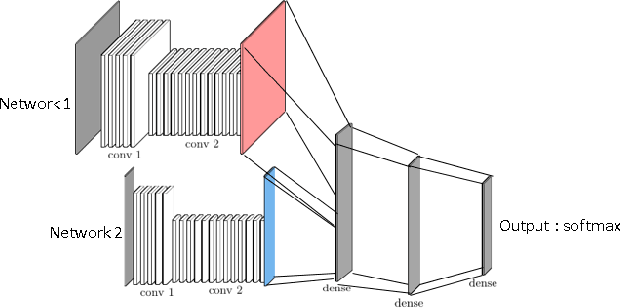

Can an agent learn efficiently in a noisy and self adapting environment with sequential, non-stationary and non-homogeneous observations? Through trading bots, we illustrate how Deep Reinforcement Learning (DRL) can tackle this challenge. Our contributions are threefold: (i) the use of contextual information also referred to as augmented state in DRL, (ii) the impact of a one period lag between observations and actions that is more realistic for an asset management environment, (iii) the implementation of a new repetitive train test method called walk forward analysis, similar in spirit to cross validation for time series. Although our experiment is on trading bots, it can easily be translated to other bot environments that operate in sequential environment with regime changes and noisy data. Our experiment for an augmented asset manager interested in finding the best portfolio for hedging strategies shows that AAMDRL achieves superior returns and lower risk.
Time your hedge with Deep Reinforcement Learning
Sep 16, 2020
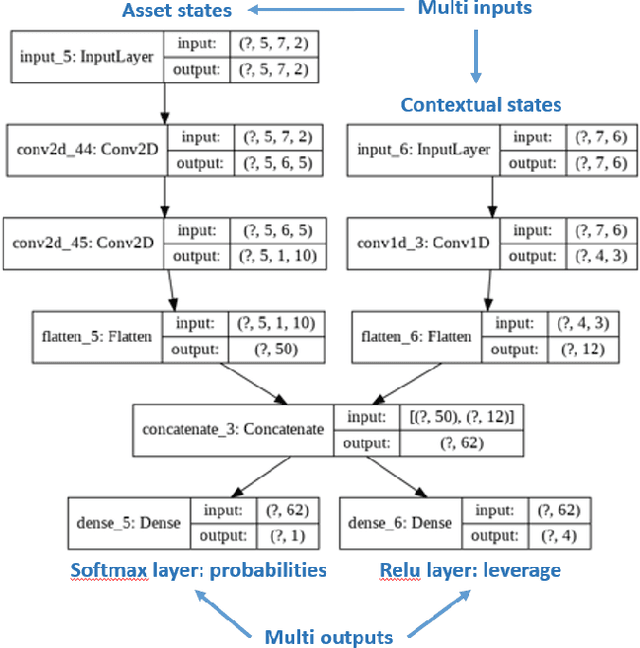
Can an asset manager plan the optimal timing for her/his hedging strategies given market conditions? The standard approach based on Markowitz or other more or less sophisticated financial rules aims to find the best portfolio allocation thanks to forecasted expected returns and risk but fails to fully relate market conditions to hedging strategies decision. In contrast, Deep Reinforcement Learning (DRL) can tackle this challenge by creating a dynamic dependency between market information and hedging strategies allocation decisions. In this paper, we present a realistic and augmented DRL framework that: (i) uses additional contextual information to decide an action, (ii) has a one period lag between observations and actions to account for one day lag turnover of common asset managers to rebalance their hedge, (iii) is fully tested in terms of stability and robustness thanks to a repetitive train test method called anchored walk forward training, similar in spirit to k fold cross validation for time series and (iv) allows managing leverage of our hedging strategy. Our experiment for an augmented asset manager interested in sizing and timing his hedges shows that our approach achieves superior returns and lower risk.
Detecting and adapting to crisis pattern with context based Deep Reinforcement Learning
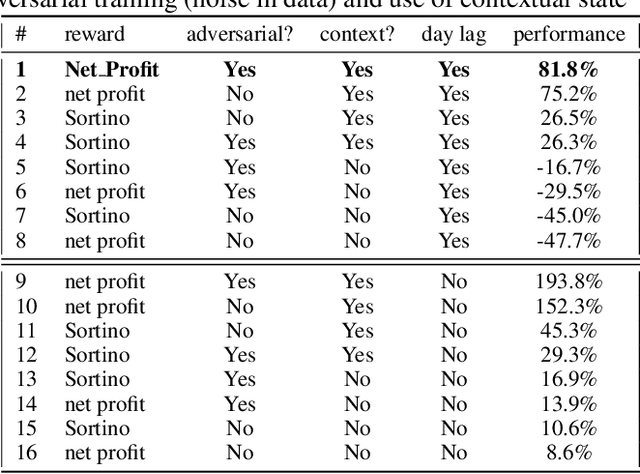
Sep 07, 2020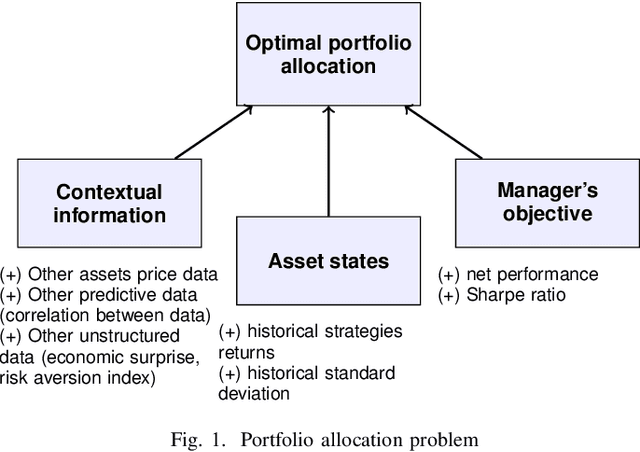

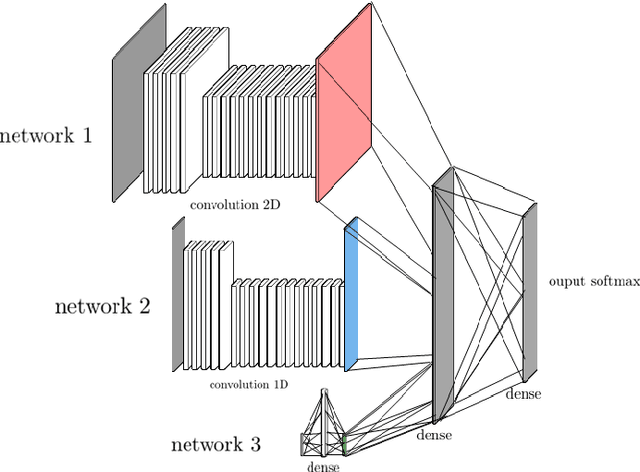
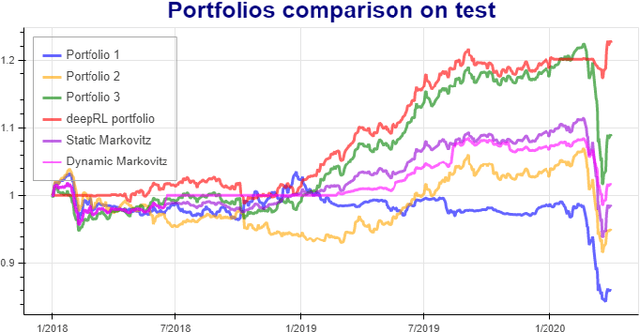
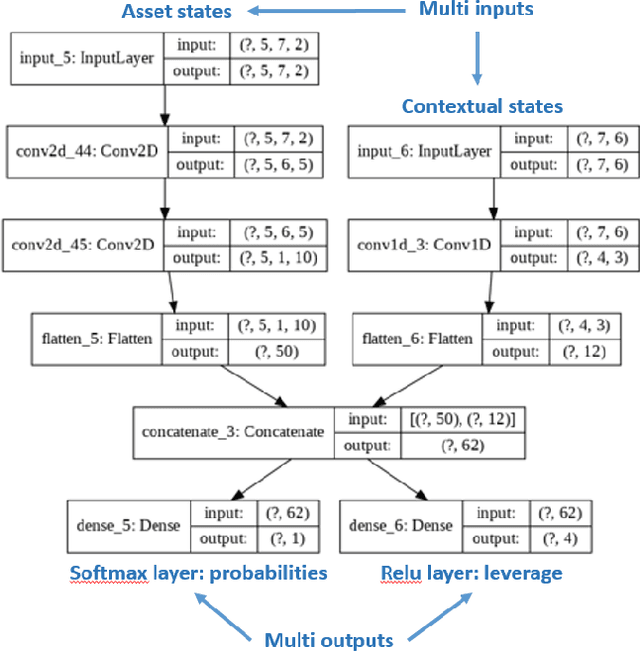
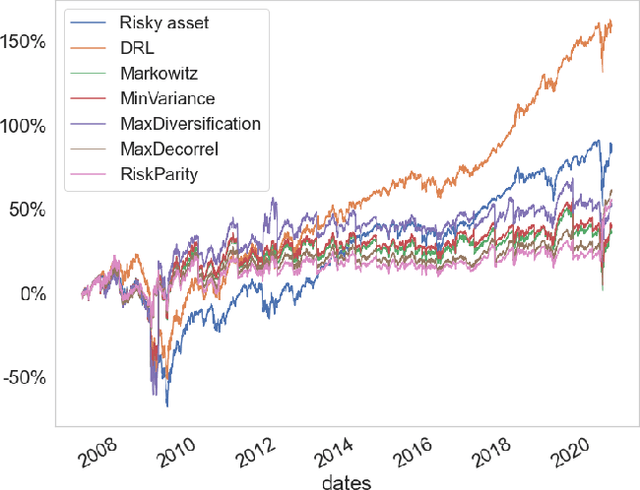
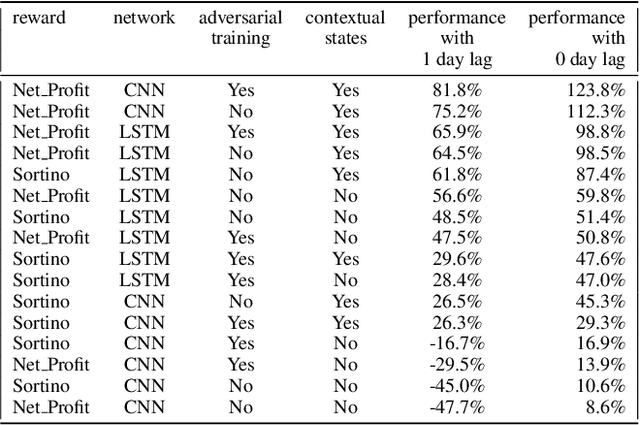
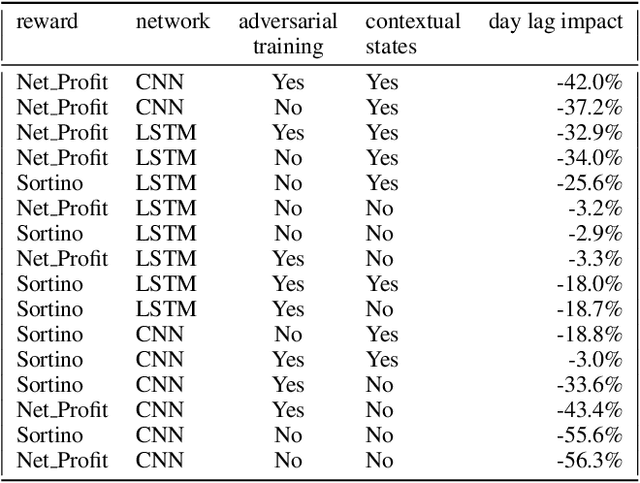
Deep reinforcement learning (DRL) has reached super human levels in complex tasks like game solving (Go and autonomous driving). However, it remains an open question whether DRL can reach human level in applications to financial problems and in particular in detecting pattern crisis and consequently dis-investing. In this paper, we present an innovative DRL framework consisting in two sub-networks fed respectively with portfolio strategies past performances and standard deviations as well as additional contextual features. The second sub network plays an important role as it captures dependencies with common financial indicators features like risk aversion, economic surprise index and correlations between assets that allows taking into account context based information. We compare different network architectures either using layers of convolutions to reduce network's complexity or LSTM block to capture time dependency and whether previous allocations is important in the modeling. We also use adversarial training to make the final model more robust. Results on test set show this approach substantially over-performs traditional portfolio optimization methods like Markowitz and is able to detect and anticipate crisis like the current Covid one.
Variance Reduction in Actor Critic Methods (ACM)
Jul 23, 2019
After presenting Actor Critic Methods (ACM), we show ACM are control variate estimators. Using the projection theorem, we prove that the Q and Advantage Actor Critic (A2C) methods are optimal in the sense of the $L^2$ norm for the control variate estimators spanned by functions conditioned by the current state and action. This straightforward application of Pythagoras theorem provides a theoretical justification of the strong performance of QAC and AAC most often referred to as A2C methods in deep policy gradient methods. This enables us to derive a new formulation for Advantage Actor Critic methods that has lower variance and improves the traditional A2C method.
NGO-GM: Natural Gradient Optimization for Graphical Models
May 14, 2019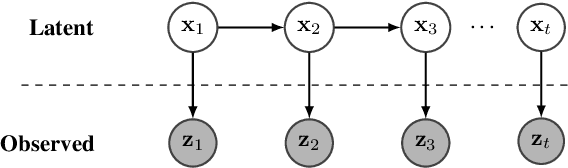
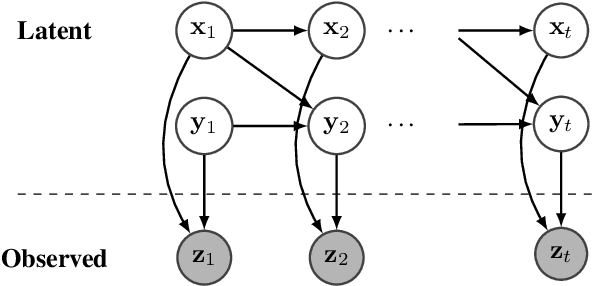


This paper deals with estimating model parameters in graphical models. We reformulate it as an information geometric optimization problem and introduce a natural gradient descent strategy that incorporates additional meta parameters. We show that our approach is a strong alternative to the celebrated EM approach for learning in graphical models. Actually, our natural gradient based strategy leads to learning optimal parameters for the final objective function without artificially trying to fit a distribution that may not correspond to the real one. We support our theoretical findings with the question of trend detection in financial markets and show that the learned model performs better than traditional practitioner methods and is less prone to overfitting.
Similarities between policy gradient methods (PGM) in Reinforcement learning (RL) and supervised learning (SL)
May 02, 2019


Reinforcement learning (RL) is about sequential decision making and is traditionally opposed to supervised learning (SL) and unsupervised learning (USL). In RL, given the current state, the agent makes a decision that may influence the next state as opposed to SL (and USL) where, the next state remains the same, regardless of the decisions taken, either in batch or online learning. Although this difference is fundamental between SL and RL, there are connections that have been overlooked. In particular, we prove in this paper that gradient policy method can be cast as a supervised learning problem where true label are replaced with discounted rewards. We provide a new proof of policy gradient methods (PGM) that emphasizes the tight link with the cross entropy and supervised learning. We provide a simple experiment where we interchange label and pseudo rewards. We conclude that other relationships with SL could be made if we modify the reward functions wisely.
BCMA-ES II: revisiting Bayesian CMA-ES
Apr 09, 2019
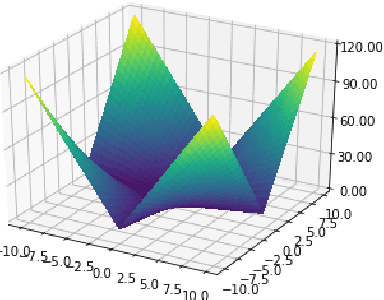
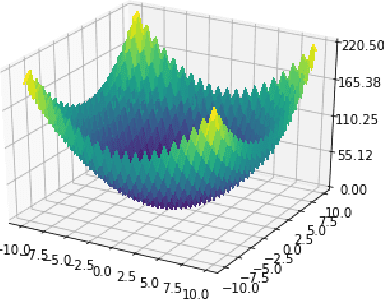
This paper revisits the Bayesian CMA-ES and provides updates for normal Wishart. It emphasizes the difference between a normal and normal inverse Wishart prior. After some computation, we prove that the only difference relies surprisingly in the expected covariance. We prove that the expected covariance should be lower in the normal Wishart prior model because of the convexity of the inverse. We present a mixture model that generalizes both normal Wishart and normal inverse Wishart model. We finally present various numerical experiments to compare both methods as well as the generalized method.