 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precision in Appearance-based Gaze Estimation in the Wild
Feb 14, 2023Appearance-based gaze estimation systems have shown great progress recently, yet the performance of these techniques depend on the datasets used for training. Most of the existing gaze estimation datasets setup in interactive settings were recorded in laboratory conditions and those recorded in the wild conditions display limited head pose and illumination variations. Further, we observed little attention so far towards precision evaluations of existing gaze estimation approaches. In this work, we present a large gaze estimation dataset, PARKS-Gaze, with wider head pose and illumination variation and with multiple samples for a single Point of Gaze (PoG). The dataset contains 974 minutes of data from 28 participants with a head pose range of 60 degrees in both yaw and pitch directions. Our within-dataset and cross-dataset evaluations and precision evaluations indicate that the proposed dataset is more challenging and enable models to generalize on unseen participants better than the existing in-the-wild datasets. The project page can be accessed here: https://github.com/lrdmurthy/PARKS-Gaze
To show or not to show: Redacting sensitive text from videos of electronic displays
Aug 19, 2022
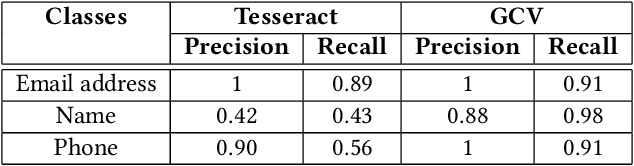
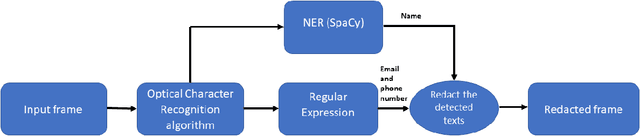

With the increasing prevalence of video recordings there is a growing need for tools that can maintain the privacy of those recorded. In this paper, we define an approach for redacting personally identifiable text from videos using a combination of optical character recognition (OCR) and natural language processing (NLP) techniques. We examine the relative performance of this approach when used with different OCR models, specifically Tesseract and the OCR system from Google Cloud Vision (GCV). For the proposed approach the performance of GCV, in both accuracy and speed, is significantly higher than Tesseract. Finally, we explore the advantages and disadvantages of both models in real-world applications.
Bridging the gap between Markowitz planning and deep reinforcement learning
Sep 30, 2020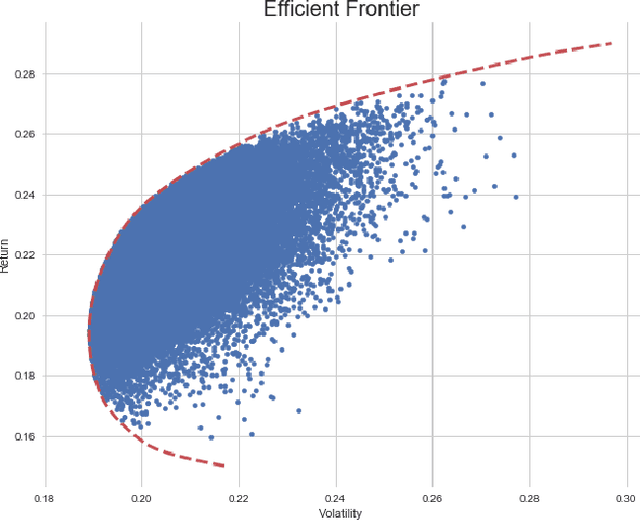
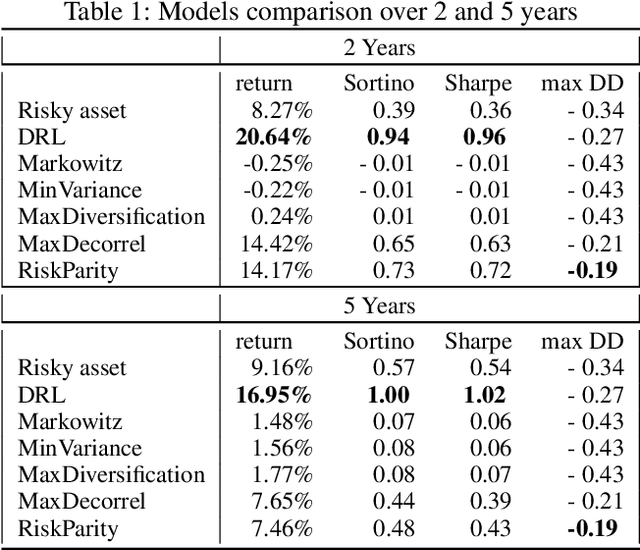
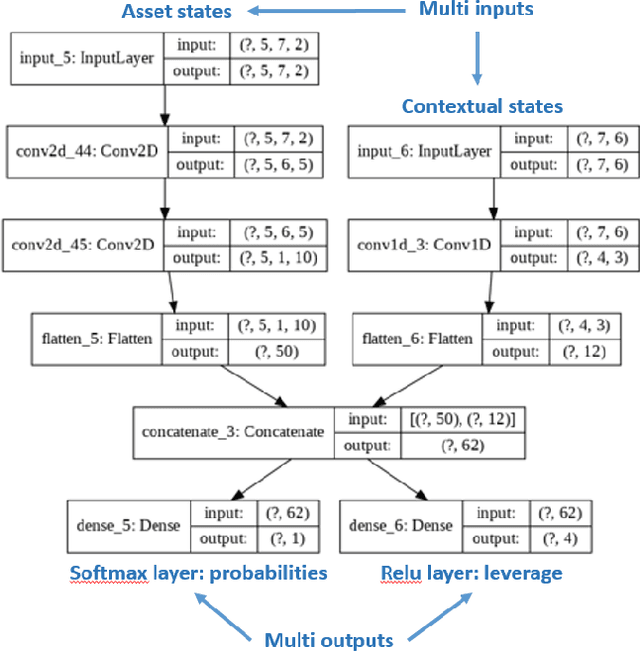
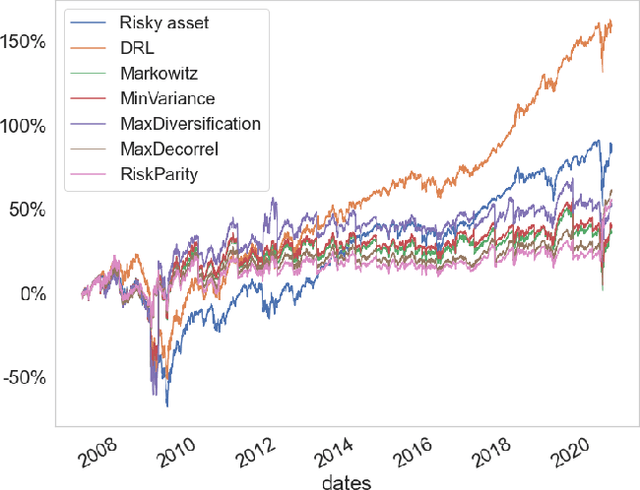
While researchers in the asset management industry have mostly focused on techniques based on financial and risk planning techniques like Markowitz efficient frontier, minimum variance, maximum diversification or equal risk parity, in parallel, another community in machine learning has started working on reinforcement learning and more particularly deep reinforcement learning to solve other decision making problems for challenging task like autonomous driving, robot learning, and on a more conceptual side games solving like Go. This paper aims to bridge the gap between these two approaches by showing Deep Reinforcement Learning (DRL) techniques can shed new lights on portfolio allocation thanks to a more general optimization setting that casts portfolio allocation as an optimal control problem that is not just a one-step optimization, but rather a continuous control optimization with a delayed reward. The advantages are numerous: (i) DRL maps directly market conditions to actions by design and hence should adapt to changing environment, (ii) DRL does not rely on any traditional financial risk assumptions like that risk is represented by variance, (iii) DRL can incorporate additional data and be a multi inputs method as opposed to more traditional optimization methods. We present on an experiment some encouraging results using convolution networks.
AAMDRL: Augmented Asset Management with Deep Reinforcement Learning
Sep 30, 2020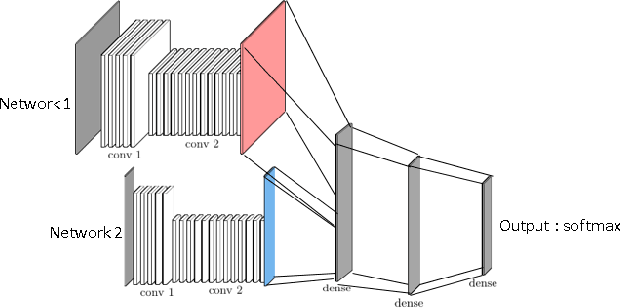
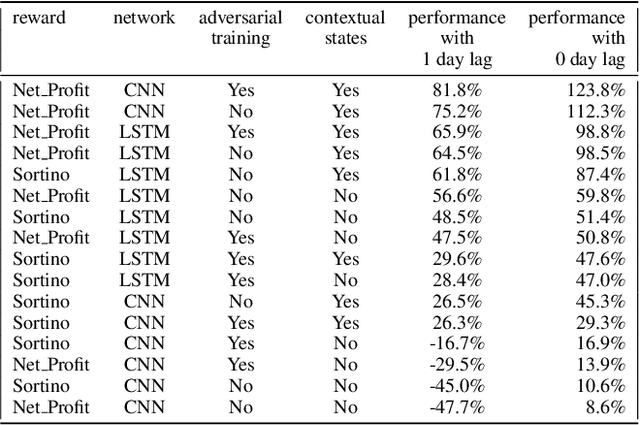

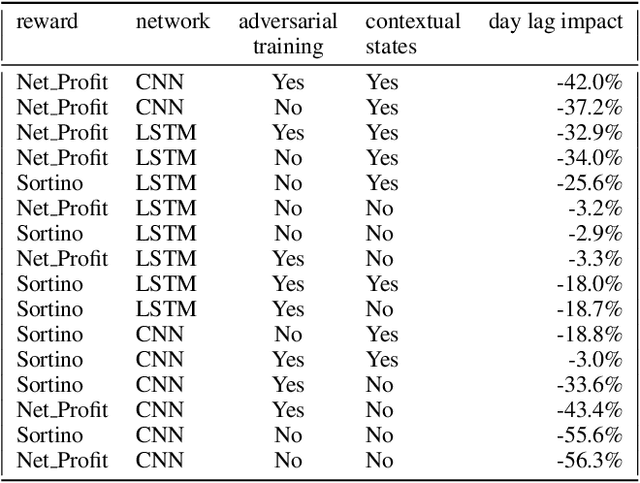
Can an agent learn efficiently in a noisy and self adapting environment with sequential, non-stationary and non-homogeneous observations? Through trading bots, we illustrate how Deep Reinforcement Learning (DRL) can tackle this challenge. Our contributions are threefold: (i) the use of contextual information also referred to as augmented state in DRL, (ii) the impact of a one period lag between observations and actions that is more realistic for an asset management environment, (iii) the implementation of a new repetitive train test method called walk forward analysis, similar in spirit to cross validation for time series. Although our experiment is on trading bots, it can easily be translated to other bot environments that operate in sequential environment with regime changes and noisy data. Our experiment for an augmented asset manager interested in finding the best portfolio for hedging strategies shows that AAMDRL achieves superior returns and lower risk.
Time your hedge with Deep Reinforcement Learning
Sep 16, 2020
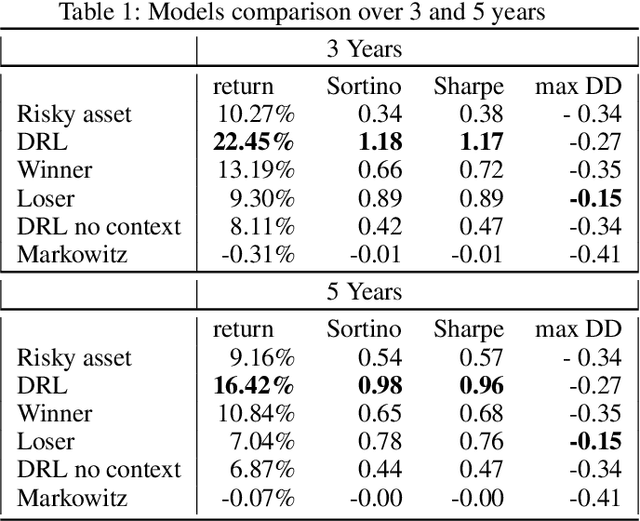
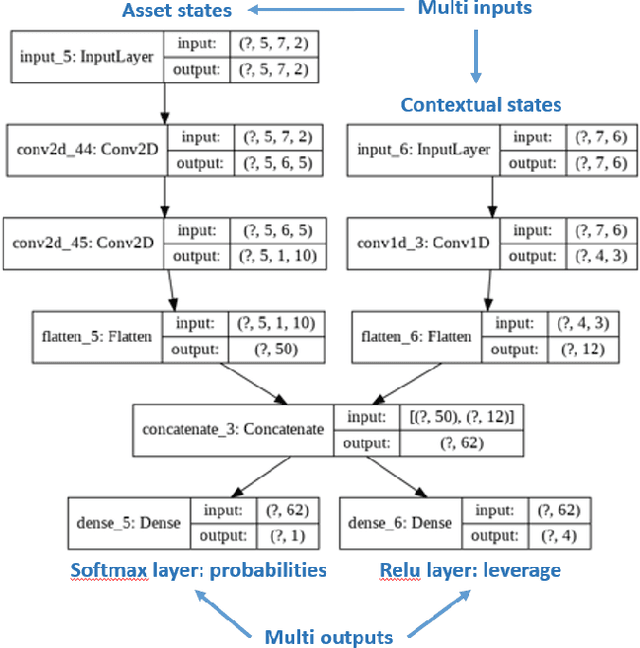
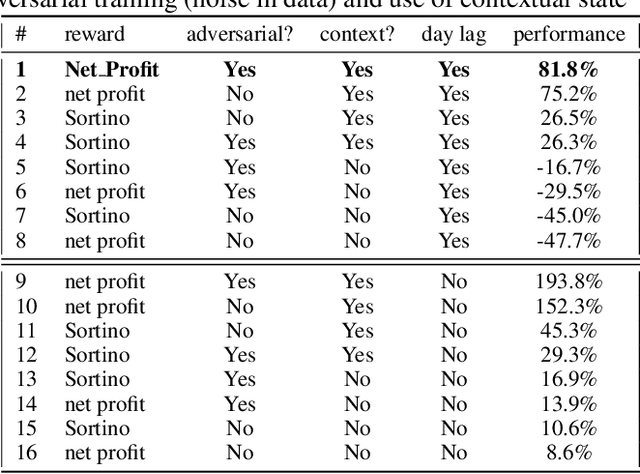
Can an asset manager plan the optimal timing for her/his hedging strategies given market conditions? The standard approach based on Markowitz or other more or less sophisticated financial rules aims to find the best portfolio allocation thanks to forecasted expected returns and risk but fails to fully relate market conditions to hedging strategies decision. In contrast, Deep Reinforcement Learning (DRL) can tackle this challenge by creating a dynamic dependency between market information and hedging strategies allocation decisions. In this paper, we present a realistic and augmented DRL framework that: (i) uses additional contextual information to decide an action, (ii) has a one period lag between observations and actions to account for one day lag turnover of common asset managers to rebalance their hedge, (iii) is fully tested in terms of stability and robustness thanks to a repetitive train test method called anchored walk forward training, similar in spirit to k fold cross validation for time series and (iv) allows managing leverage of our hedging strategy. Our experiment for an augmented asset manager interested in sizing and timing his hedges shows that our approach achieves superior returns and lower risk.
Decoding CNN based Object Classifier Using Visualization
Jul 15, 2020
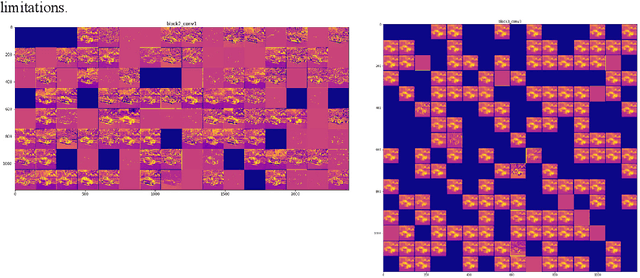

This paper investigates how working of Convolutional Neural Network (CNN) can be explained through visualization in the context of machine perception of autonomous vehicles. We visualize what type of features are extracted in different convolution layers of CNN that helps to understand how CNN gradually increases spatial information in every layer. Thus, it concentrates on region of interests in every transformation. Visualizing heat map of activation helps us to understand how CNN classifies and localizes different objects in image. This study also helps us to reason behind low accuracy of a model helps to increase trust on object detection module.