 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precision in Appearance-based Gaze Estimation in the Wild
Feb 14, 2023Appearance-based gaze estimation systems have shown great progress recently, yet the performance of these techniques depend on the datasets used for training. Most of the existing gaze estimation datasets setup in interactive settings were recorded in laboratory conditions and those recorded in the wild conditions display limited head pose and illumination variations. Further, we observed little attention so far towards precision evaluations of existing gaze estimation approaches. In this work, we present a large gaze estimation dataset, PARKS-Gaze, with wider head pose and illumination variation and with multiple samples for a single Point of Gaze (PoG). The dataset contains 974 minutes of data from 28 participants with a head pose range of 60 degrees in both yaw and pitch directions. Our within-dataset and cross-dataset evaluations and precision evaluations indicate that the proposed dataset is more challenging and enable models to generalize on unseen participants better than the existing in-the-wild datasets. The project page can be accessed here: https://github.com/lrdmurthy/PARKS-Gaze
Similarity-Based Clustering for Enhancing Image Classification Architectures
Nov 03, 2020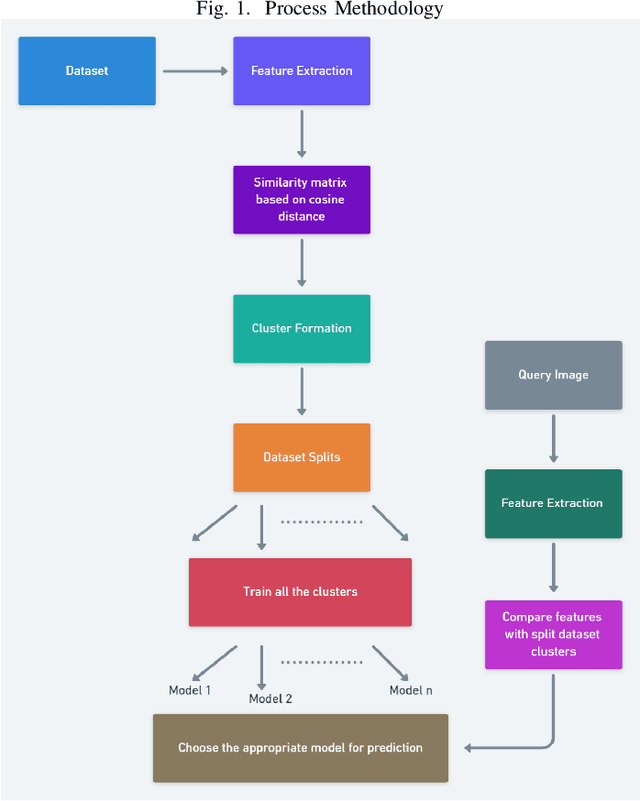
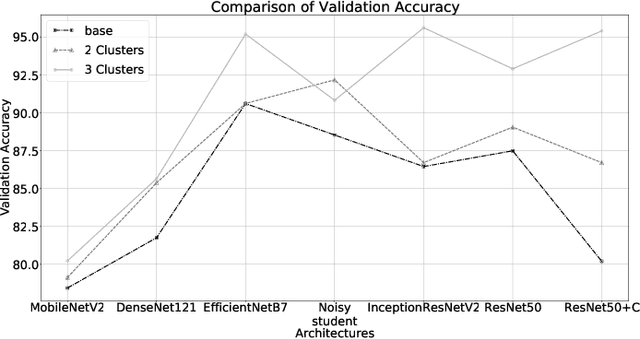


Convolutional networks are at the center of best in class computer vision applications for a wide assortment of undertakings. Since 2014, profound amount of work began to make better convolutional architectures, yielding generous additions in different benchmarks. Albeit expanded model size and computational cost will, in general, mean prompt quality increases for most undertakings but, the architectures now need to have some additional information to increase the performance. We show empirical evidence that with the amalgamation of content-based image similarity and deep learning models, we can provide the flow of information which can be used in making clustered learning possible. We show how parallel training of sub-dataset clusters not only reduces the cost of computation but also increases the benchmark accuracies by 5-11 percent.