 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Extension Patch: A simple and efficient way to extend an object detection model
Oct 06, 2021
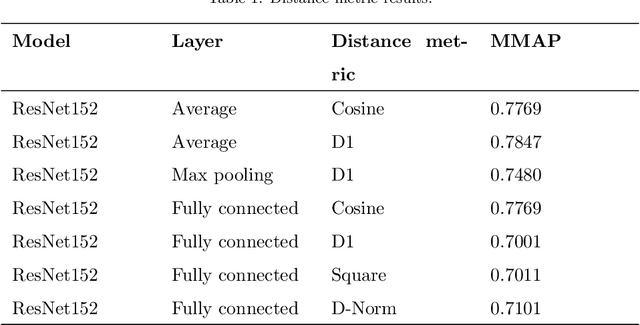
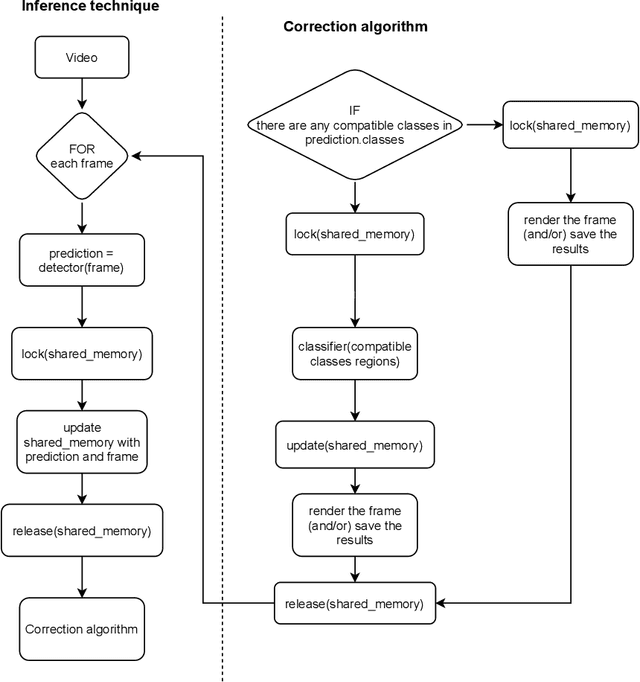
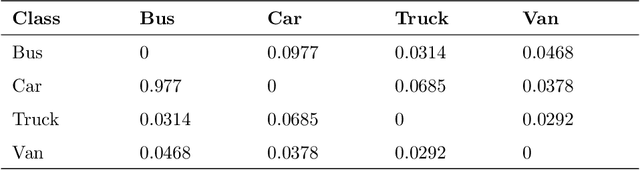
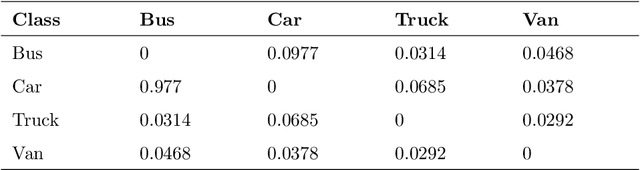
While building convolutional network-based systems, the toll it takes to train the network is something that cannot be ignored. In cases where we need to append additional capabilities to the existing model, the attention immediately goes towards retraining techniques. In this paper, I show how to leverage knowledge about the dataset to append the class faster while maintaining the speed of inference as well as the accuracies; while reducing the amount of time and data required. The method can extend a class in the existing object detection model in 1/10th of the time compared to the other existing methods. S-Extension patch not only offers faster training but also speed and ease of adaptation, as it can be appended to any existing system, given it fulfills the similarity threshold condition.
Dataset Structural Index: Understanding a machine's perspective towards visual data
Oct 05, 2021


With advances in vision and perception architectures, we have realized that working with data is equally crucial, if not more, than the algorithms. Till today, we have trained machines based on our knowledge and perspective of the world. The entire concept of Dataset Structural Index(DSI) revolves around understanding a machine`s perspective of the dataset. With DSI, I show two meta values with which we can get more information over a visual dataset and use it to optimize data, create better architectures, and have an ability to guess which model would work best. These two values are the Variety contribution ratio and Similarity matrix. In the paper, I show many applications of DSI, one of which is how the same level of accuracy can be achieved with the same model architectures trained over less amount of data.
Similarity-Based Clustering for Enhancing Image Classification Architectures
Nov 03, 2020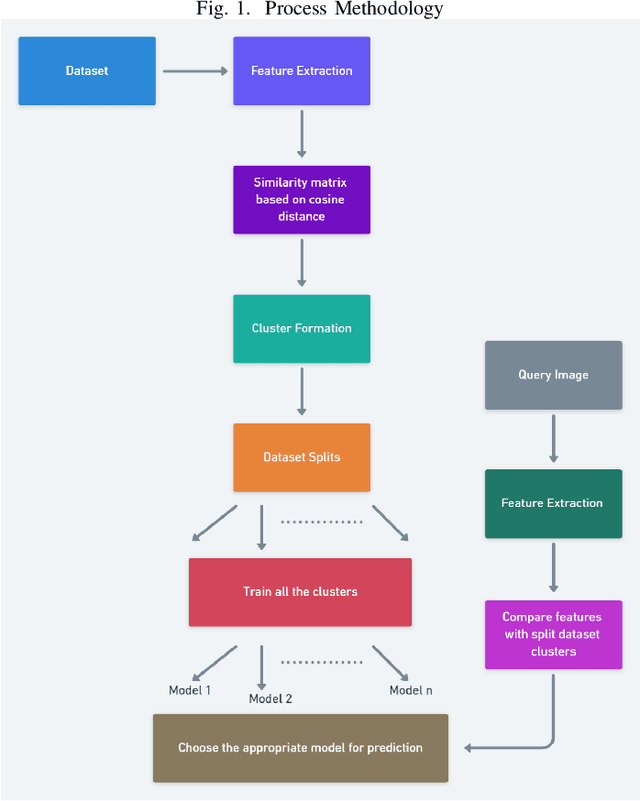
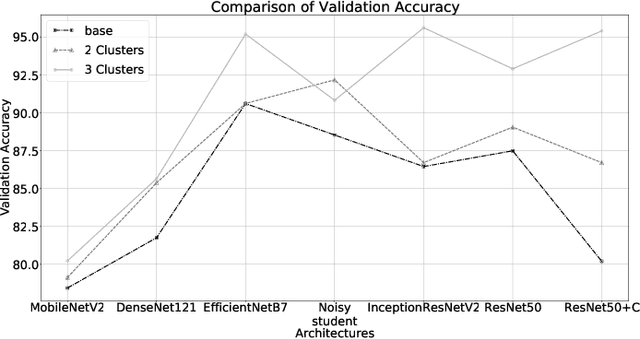


Convolutional networks are at the center of best in class computer vision applications for a wide assortment of undertakings. Since 2014, profound amount of work began to make better convolutional architectures, yielding generous additions in different benchmarks. Albeit expanded model size and computational cost will, in general, mean prompt quality increases for most undertakings but, the architectures now need to have some additional information to increase the performance. We show empirical evidence that with the amalgamation of content-based image similarity and deep learning models, we can provide the flow of information which can be used in making clustered learning possible. We show how parallel training of sub-dataset clusters not only reduces the cost of computation but also increases the benchmark accuracies by 5-11 percent.
Improving the efficiency of spectral features extraction by structuring the audio files
Oct 07, 2020



The extraction of spectral features from a music clip is a computationally expensive task. As in order to extract accurate features, we need to process the clip for its whole length. This preprocessing task creates a large overhead and also makes the extraction process slower. We show how formatting a dataset in a certain way, can help make the process more efficient by eliminating the need for processing the clip for its whole duration, and still extract the features accurately. In addition, we discuss the possibility of defining set generic durations for analyzing a certain type of music clip while training. And in doing so we cut down the need of processing the clip duration to just 10% of the global average.