 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-Based Clustering for Enhancing Image Classification Architectures
Paper and Code
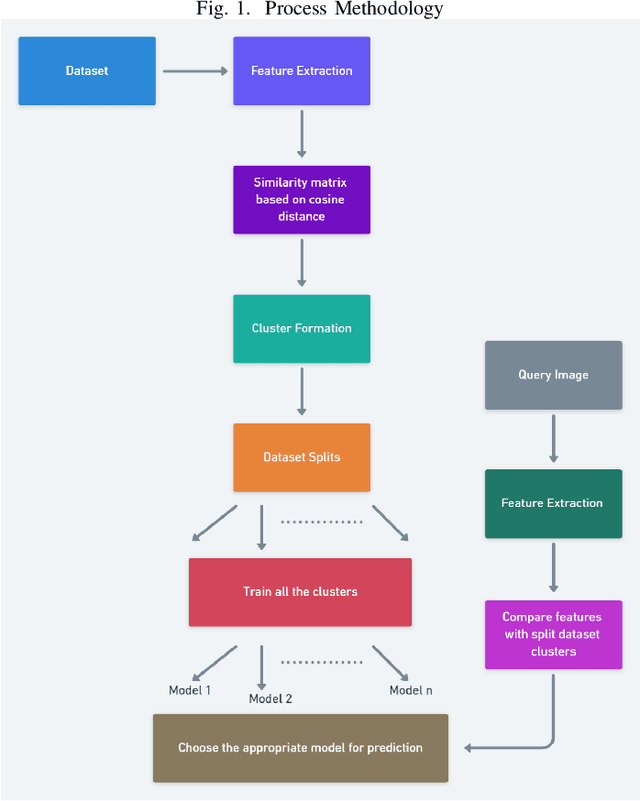
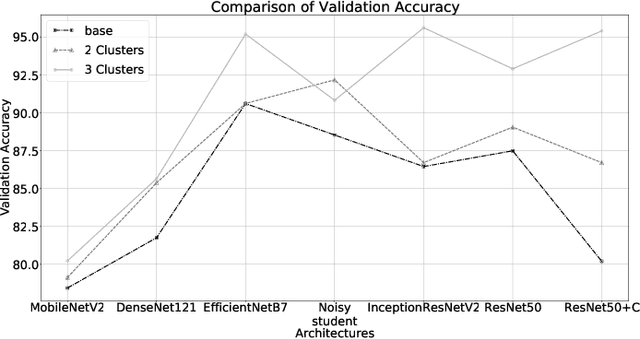


Convolutional networks are at the center of best in class computer vision applications for a wide assortment of undertakings. Since 2014, profound amount of work began to make better convolutional architectures, yielding generous additions in different benchmarks. Albeit expanded model size and computational cost will, in general, mean prompt quality increases for most undertakings but, the architectures now need to have some additional information to increase the performance. We show empirical evidence that with the amalgamation of content-based image similarity and deep learning models, we can provide the flow of information which can be used in making clustered learning possible. We show how parallel training of sub-dataset clusters not only reduces the cost of computation but also increases the benchmark accuracies by 5-11 percent.