 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precision in Appearance-based Gaze Estimation in the Wild
Feb 14, 2023Appearance-based gaze estimation systems have shown great progress recently, yet the performance of these techniques depend on the datasets used for training. Most of the existing gaze estimation datasets setup in interactive settings were recorded in laboratory conditions and those recorded in the wild conditions display limited head pose and illumination variations. Further, we observed little attention so far towards precision evaluations of existing gaze estimation approaches. In this work, we present a large gaze estimation dataset, PARKS-Gaze, with wider head pose and illumination variation and with multiple samples for a single Point of Gaze (PoG). The dataset contains 974 minutes of data from 28 participants with a head pose range of 60 degrees in both yaw and pitch directions. Our within-dataset and cross-dataset evaluations and precision evaluations indicate that the proposed dataset is more challenging and enable models to generalize on unseen participants better than the existing in-the-wild datasets. The project page can be accessed here: https://github.com/lrdmurthy/PARKS-Gaze
To show or not to show: Redacting sensitive text from videos of electronic displays
Aug 19, 2022
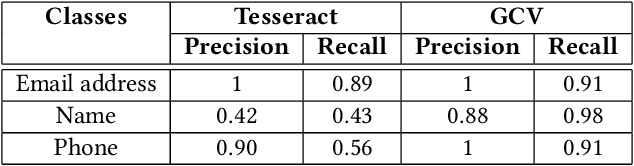
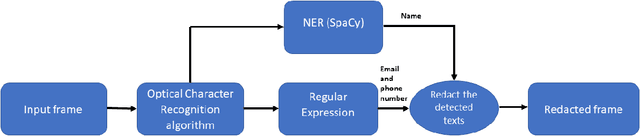

With the increasing prevalence of video recordings there is a growing need for tools that can maintain the privacy of those recorded. In this paper, we define an approach for redacting personally identifiable text from videos using a combination of optical character recognition (OCR) and natural language processing (NLP) techniques. We examine the relative performance of this approach when used with different OCR models, specifically Tesseract and the OCR system from Google Cloud Vision (GCV). For the proposed approach the performance of GCV, in both accuracy and speed, is significantly higher than Tesseract. Finally, we explore the advantages and disadvantages of both models in real-world applications.
Decoding CNN based Object Classifier Using Visualization
Jul 15, 2020
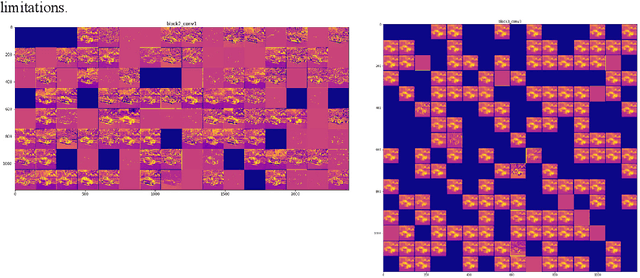

This paper investigates how working of Convolutional Neural Network (CNN) can be explained through visualization in the context of machine perception of autonomous vehicles. We visualize what type of features are extracted in different convolution layers of CNN that helps to understand how CNN gradually increases spatial information in every layer. Thus, it concentrates on region of interests in every transformation. Visualizing heat map of activation helps us to understand how CNN classifies and localizes different objects in image. This study also helps us to reason behind low accuracy of a model helps to increase trust on object detection module.
Eye Gaze Controlled Robotic Arm for Persons with SSMI
May 25, 2020
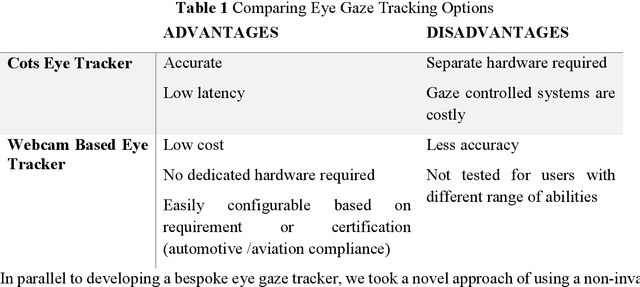
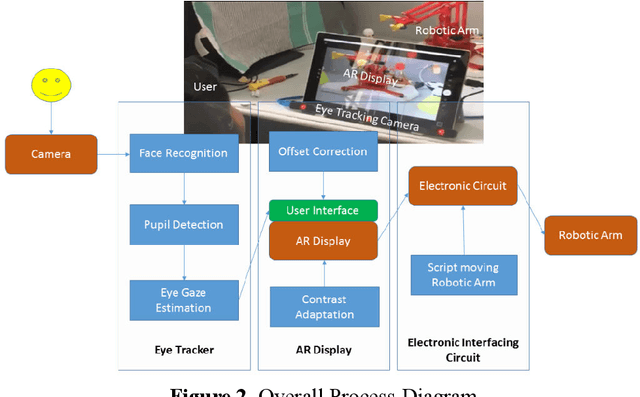
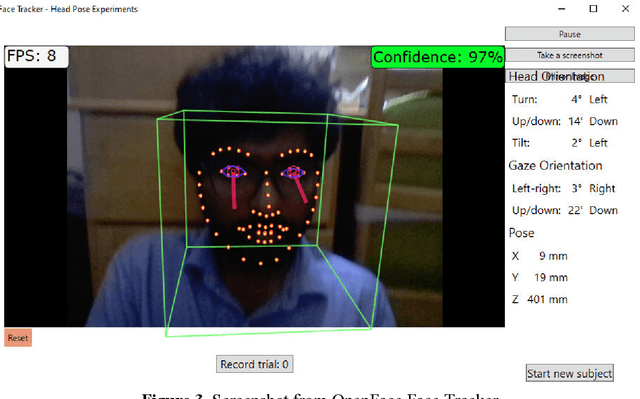
Background: People with severe speech and motor impairment (SSMI) often uses a technique called eye pointing to communicate with outside world. One of their parents, caretakers or teachers hold a printed board in front of them and by analyzing their eye gaze manually, their intentions are interpreted. This technique is often error prone and time consuming and depends on a single caretaker. Objective: We aimed to automate the eye tracking process electronically by using commercially available tablet, computer or laptop and without requiring any dedicated hardware for eye gaze tracking. The eye gaze tracker is used to develop a video see through based AR (augmented reality) display that controls a robotic device with eye gaze and deployed for a fabric printing task. Methodology: We undertook a user centred design process and separately evaluated the web cam based gaze tracker and the video see through based human robot interaction involving users with SSMI. We also reported a user study on manipulating a robotic arm with webcam based eye gaze tracker. Results: Using our bespoke eye gaze controlled interface, able bodied users can select one of nine regions of screen at a median of less than 2 secs and users with SSMI can do so at a median of 4 secs. Using the eye gaze controlled human-robot AR display, users with SSMI could undertake representative pick and drop task at an average duration less than 15 secs and reach a randomly designated target within 60 secs using a COTS eye tracker and at an average time of 2 mins using the webcam based eye gaze tracker.