Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo show or not to show: Redacting sensitive text from videos of electronic displays
Aug 19, 2022
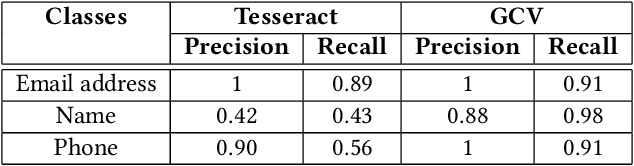
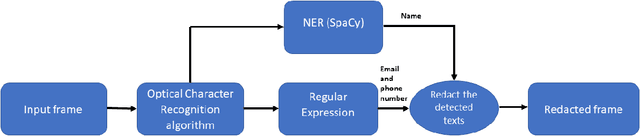

With the increasing prevalence of video recordings there is a growing need for tools that can maintain the privacy of those recorded. In this paper, we define an approach for redacting personally identifiable text from videos using a combination of optical character recognition (OCR) and natural language processing (NLP) techniques. We examine the relative performance of this approach when used with different OCR models, specifically Tesseract and the OCR system from Google Cloud Vision (GCV). For the proposed approach the performance of GCV, in both accuracy and speed, is significantly higher than Tesseract. Finally, we explore the advantages and disadvantages of both models in real-world applications.
Via