 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAMDRL: Augmented Asset Management with Deep Reinforcement Learning
Paper and Code
Sep 30, 2020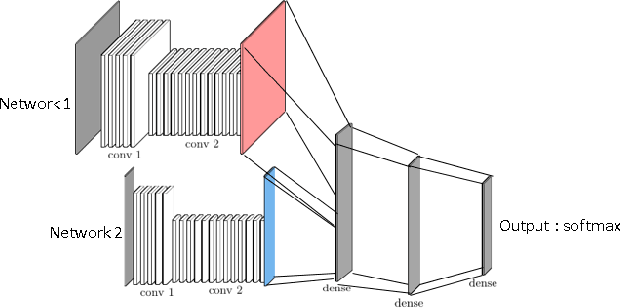
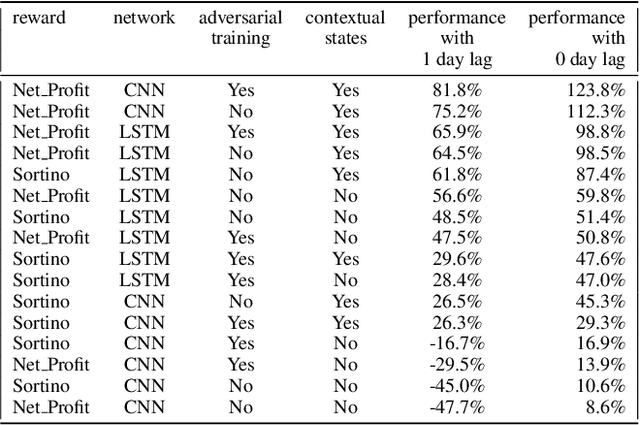

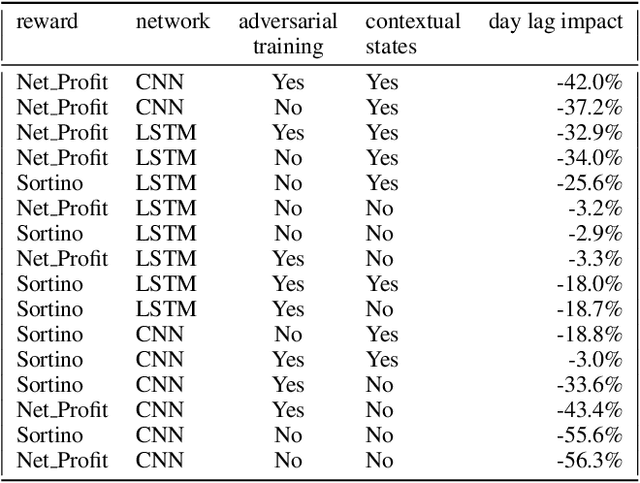
Can an agent learn efficiently in a noisy and self adapting environment with sequential, non-stationary and non-homogeneous observations? Through trading bots, we illustrate how Deep Reinforcement Learning (DRL) can tackle this challenge. Our contributions are threefold: (i) the use of contextual information also referred to as augmented state in DRL, (ii) the impact of a one period lag between observations and actions that is more realistic for an asset management environment, (iii) the implementation of a new repetitive train test method called walk forward analysis, similar in spirit to cross validation for time series. Although our experiment is on trading bots, it can easily be translated to other bot environments that operate in sequential environment with regime changes and noisy data. Our experiment for an augmented asset manager interested in finding the best portfolio for hedging strategies shows that AAMDRL achieves superior returns and lower risk.