 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Pre-Prompt Optimization for Mathematical Reasoning
Paper and Code
Dec 05, 2024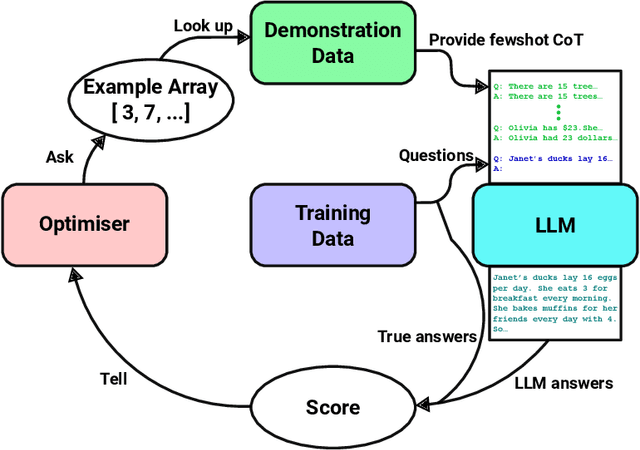
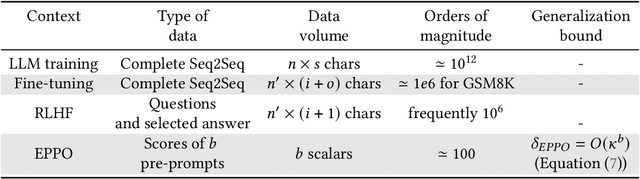
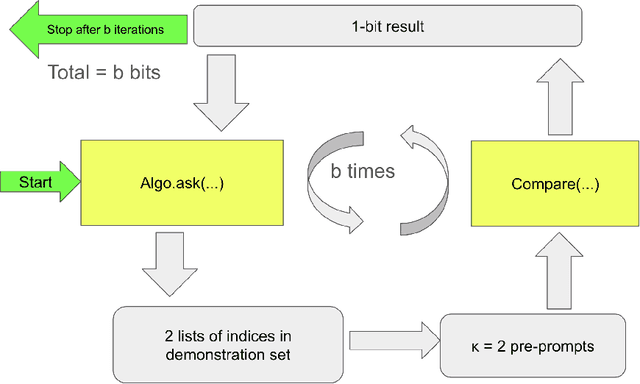
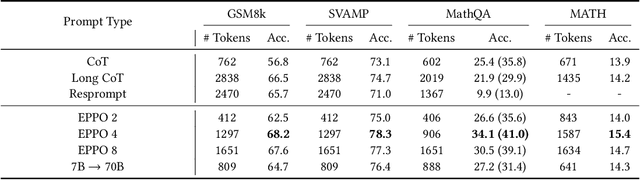
Recent advancements have highlighted that large language models (LLMs), when given a small set of task-specific examples, demonstrate remarkable proficiency, a capability that extends to complex reasoning tasks. In particular, the combination of few-shot learning with the chain-of-thought (CoT) approach has been pivotal in steering models towards more logically consistent conclusions. This paper explores the optimization of example selection for designing effective CoT pre-prompts and shows that the choice of the optimization algorithm, typically in favor of comparison-based methods such as evolutionary computation, significantly enhances efficacy and feasibility. Specifically, thanks to a limited exploitative and overfitted optimization, Evolutionary Pre-Prompt Optimization (EPPO) brings an improvement over the naive few-shot approach exceeding 10 absolute points in exact match scores on benchmark datasets such as GSM8k and MathQA. These gains are consistent across various contexts and are further amplified when integrated with self-consistency (SC)