 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoseCDL: Robust and Scalable Convolutional Dictionary Learning for Rare-event Detection
Sep 10, 2025Identifying recurring patterns and rare events in large-scale signals is a fundamental challenge in fields such as astronomy, physical simulations, and biomedical science. Convolutional Dictionary Learning (CDL) offers a powerful framework for modeling local structures in signals, but its use for detecting rare or anomalous events remains largely unexplored. In particular, CDL faces two key challenges in this setting: high computational cost and sensitivity to artifacts and outliers. In this paper, we introduce RoseCDL, a scalable and robust CDL algorithm designed for unsupervised rare event detection in long signals. RoseCDL combines stochastic windowing for efficient training on large datasets with inline outlier detection to enhance robustness and isolate anomalous patterns. This reframes CDL as a practical tool for event discovery and characterization in real-world signals, extending its role beyond traditional tasks like compression or denoising.
Tuning without Peeking: Provable Privacy and Generalization Bounds for LLM Post-Training
Jul 02, 2025Gradient-based optimization is the workhorse of deep learning, offering efficient and scalable training via backpropagation. However, its reliance on large volumes of labeled data raises privacy and security concerns such as susceptibility to data poisoning attacks and the risk of overfitting. In contrast, black box optimization methods, which treat the model as an opaque function, relying solely on function evaluations to guide optimization, offer a promising alternative in scenarios where data access is restricted, adversarial risks are high, or overfitting is a concern. However, black box methods also pose significant challenges, including poor scalability to high-dimensional parameter spaces, as prevalent in large language models (LLMs), and high computational costs due to reliance on numerous model evaluations. This paper introduces BBoxER, an evolutionary black-box method for LLM post-training that induces an information bottleneck via implicit compression of the training data. Leveraging the tractability of information flow, we provide strong theoretical bounds on generalization, differential privacy, susceptibility to data poisoning attacks, and robustness to extraction attacks. BBoxER operates on top of pre-trained LLMs, offering a lightweight and modular enhancement suitable for deployment in restricted or privacy-sensitive environments, in addition to non-vacuous generalization guarantees. In experiments with LLMs, we demonstrate empirically that Retrofitting methods are able to learn, showing how a few iterations of BBoxER improve performance and generalize well on a benchmark of reasoning datasets. This positions BBoxER as an attractive add-on on top of gradient-based optimization.
Analysis and Synthesis Denoisers for Forward-Backward Plug-and-Play Algorithms
Nov 20, 2024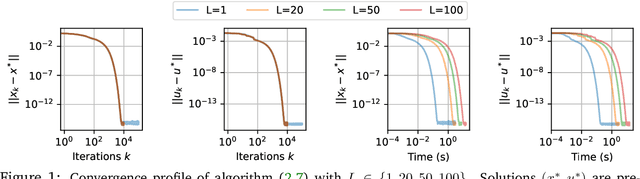

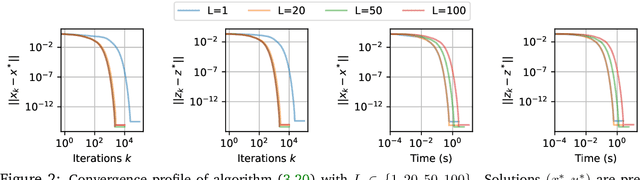

In this work we study the behavior of the forward-backward (FB) algorithm when the proximity operator is replaced by a sub-iterative procedure to approximate a Gaussian denoiser, in a Plug-and-Play (PnP) fashion. In particular, we consider both analysis and synthesis Gaussian denoisers within a dictionary framework, obtained by unrolling dual-FB iterations or FB iterations, respectively. We analyze the associated minimization problems as well as the asymptotic behavior of the resulting FB-PnP iterations. In particular, we show that the synthesis Gaussian denoising problem can be viewed as a proximity operator. For each case, analysis and synthesis, we show that the FB-PnP algorithms solve the same problem whether we use only one or an infinite number of sub-iteration to solve the denoising problem at each iteration. To this aim, we show that each "one sub-iteration" strategy within the FB-PnP can be interpreted as a primal-dual algorithm when a warm-restart strategy is used. We further present similar results when using a Moreau-Yosida smoothing of the global problem, for an arbitrary number of sub-iterations. Finally, we provide numerical simulations to illustrate our theoretical results. In particular we first consider a toy compressive sensing example, as well as an image restoration problem in a deep dictionary framework.
Sliced-Wasserstein on Symmetric Positive Definite Matrices for M/EEG Signals
Mar 10, 2023When dealing with electro or magnetoencephalography records, many supervised prediction tasks are solved by working with covariance matrices to summarize the signals. Learning with these matrices requires using Riemanian geometry to account for their structure. In this paper, we propose a new method to deal with distributions of covariance matrices and demonstrate its computational efficiency on M/EEG multivariate time series. More specifically, we define a Sliced-Wasserstein distance between measures of symmetric positive definite matrices that comes with strong theoretical guarantees. Then, we take advantage of its properties and kernel methods to apply this distance to brain-age prediction from MEG data and compare it to state-of-the-art algorithms based on Riemannian geometry. Finally, we show that it is an efficient surrogate to the Wasserstein distance in domain adaptation for Brain Computer Interface applications.
Dictionary and prior learning with unrolled algorithms for unsupervised inverse problems
Jun 11, 2021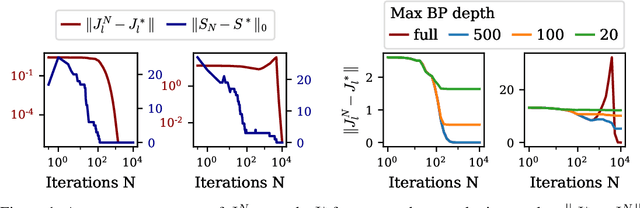

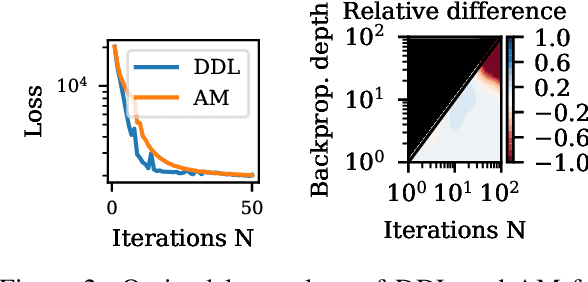

Inverse problems consist in recovering a signal given noisy observations. One classical resolution approach is to leverage sparsity and integrate prior knowledge of the signal to the reconstruction algorithm to get a plausible solution. Still, this prior might not be sufficiently adapted to the data. In this work, we study Dictionary and Prior learning from degraded measurements as a bi-level problem, and we take advantage of unrolled algorithms to solve approximate formulations of Synthesis and Analysis. We provide an empirical and theoretical analysis of automatic differentiation for Dictionary Learning to understand better the pros and cons of unrolling in this context. We find that unrolled algorithms speed up the recovery process for a small number of iterations by improving the gradient estimation. Then we compare Analysis and Synthesis by evaluating the performance of unrolled algorithms for inverse problems, without access to any ground truth data for several classes of dictionaries and priors. While Analysis can achieve good results,Synthesis is more robust and performs better. Finally, we illustrate our method on pattern and structure learning tasks from degraded measurements.
Estimation with Low-Rank Time-Frequency Synthesis Models
Jun 29, 2018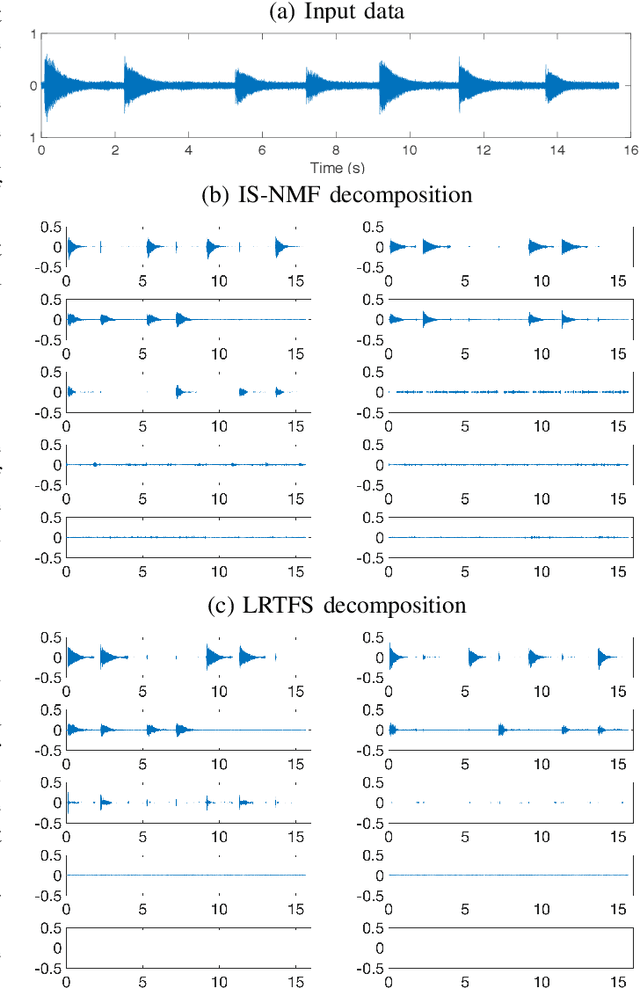
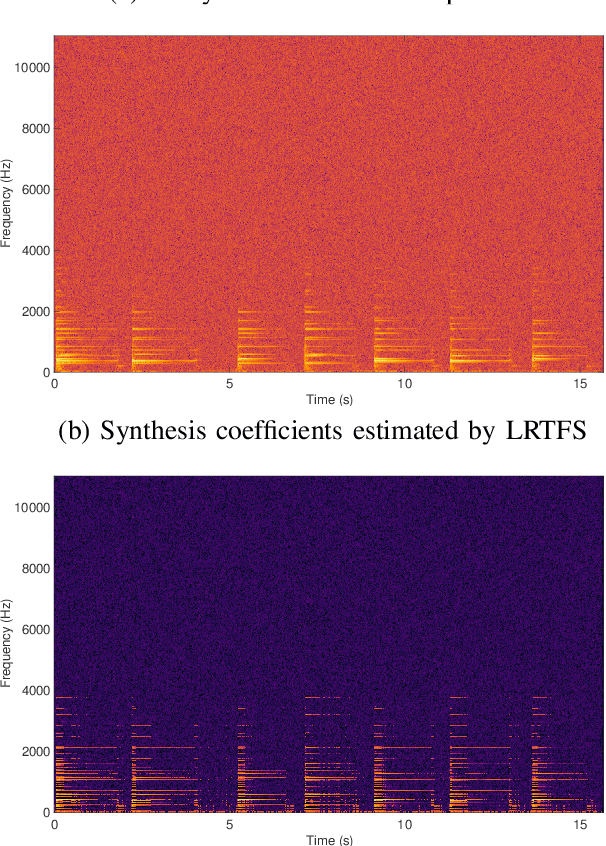
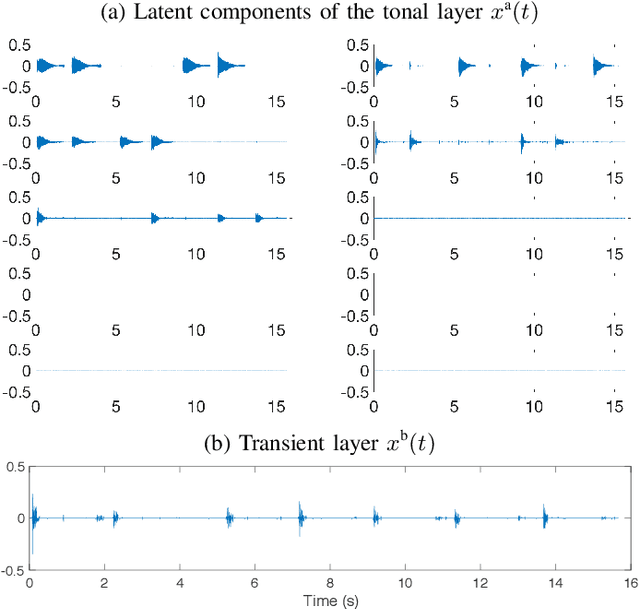
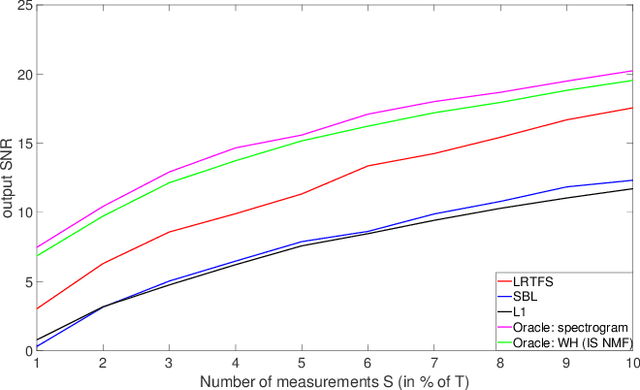
Many state-of-the-art signal decomposition techniques rely on a low-rank factorization of a time-frequency (t-f) transform. In particular, nonnegative matrix factorization (NMF) of the spectrogram has been considered in many audio applications. This is an analysis approach in the sense that the factorization is applied to the squared magnitude of the analysis coefficients returned by the t-f transform. In this paper we instead propose a synthesis approach, where low-rankness is imposed to the synthesis coefficients of the data signal over a given t-f dictionary (such as a Gabor frame). As such we offer a novel modeling paradigm that bridges t-f synthesis modeling and traditional analysis-based NMF approaches. The proposed generative model allows in turn to design more sophisticated multi-layer representations that can efficiently capture diverse forms of structure. Additionally, the generative modeling allows to exploit t-f low-rankness for compressive sensing. We present efficient iterative shrinkage algorithms to perform estimation in the proposed models and illustrate the capabilities of the new modeling paradigm over audio signal processing examples.
Social-sparsity brain decoders: faster spatial sparsity
Jun 21, 2016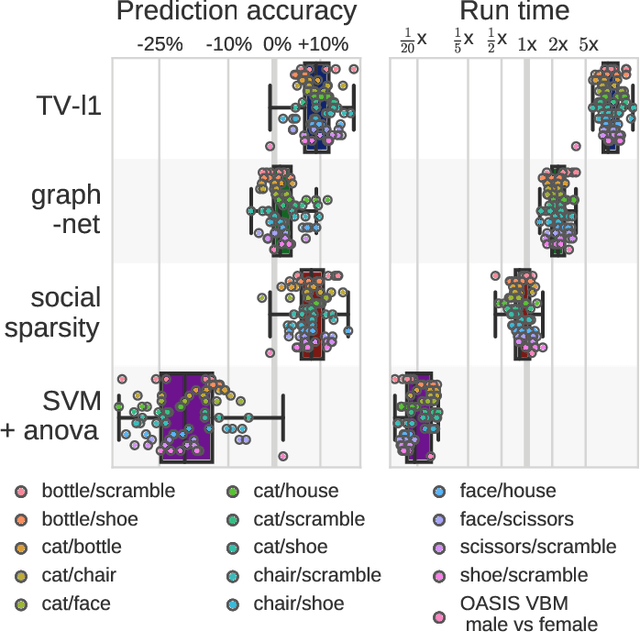
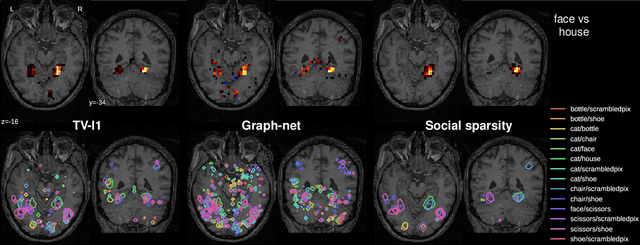
Spatially-sparse predictors are good models for brain decoding: they give accurate predictions and their weight maps are interpretable as they focus on a small number of regions. However, the state of the art, based on total variation or graph-net, is computationally costly. Here we introduce sparsity in the local neighborhood of each voxel with social-sparsity, a structured shrinkage operator. We find that, on brain imaging classification problems, social-sparsity performs almost as well as total-variation models and better than graph-net, for a fraction of the computational cost. It also very clearly outlines predictive regions. We give details of the model and the algorithm.