 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBusemann Functions in the Wasserstein Space: Existence, Closed-Forms, and Applications to Slicing
Oct 06, 2025The Busemann function has recently found much interest in a variety of geometric machine learning problems, as it naturally defines projections onto geodesic rays of Riemannian manifolds and generalizes the notion of hyperplanes. As several sources of data can be conveniently modeled as probability distributions, it is natural to study this function in the Wasserstein space, which carries a rich formal Riemannian structure induced by Optimal Transport metrics. In this work, we investigate the existence and computation of Busemann functions in Wasserstein space, which admits geodesic rays. We establish closed-form expressions in two important cases: one-dimensional distributions and Gaussian measures. These results enable explicit projection schemes for probability distributions on $\mathbb{R}$, which in turn allow us to define novel Sliced-Wasserstein distances over Gaussian mixtures and labeled datasets. We demonstrate the efficiency of those original schemes on synthetic datasets as well as transfer learning problems.
Flowing Datasets with Wasserstein over Wasserstein Gradient Flows
Jun 09, 2025Many applications in machine learning involve data represented as probability distributions. The emergence of such data requires radically novel techniques to design tractable gradient flows on probability distributions over this type of (infinite-dimensional) objects. For instance, being able to flow labeled datasets is a core task for applications ranging from domain adaptation to transfer learning or dataset distillation. In this setting, we propose to represent each class by the associated conditional distribution of features, and to model the dataset as a mixture distribution supported on these classes (which are themselves probability distributions), meaning that labeled datasets can be seen as probability distributions over probability distributions. We endow this space with a metric structure from optimal transport, namely the Wasserstein over Wasserstein (WoW) distance, derive a differential structure on this space, and define WoW gradient flows. The latter enables to design dynamics over this space that decrease a given objective functional. We apply our framework to transfer learning and dataset distillation tasks, leveraging our gradient flow construction as well as novel tractable functionals that take the form of Maximum Mean Discrepancies with Sliced-Wasserstein based kernels between probability distributions.
DDEQs: Distributional Deep Equilibrium Models through Wasserstein Gradient Flows
Mar 03, 2025Deep Equilibrium Models (DEQs) are a class of implicit neural networks that solve for a fixed point of a neural network in their forward pass. Traditionally, DEQs take sequences as inputs, but have since been applied to a variety of data. In this work, we present Distributional Deep Equilibrium Models (DDEQs), extending DEQs to discrete measure inputs, such as sets or point clouds. We provide a theoretically grounded framework for DDEQs. Leveraging Wasserstein gradient flows, we show how the forward pass of the DEQ can be adapted to find fixed points of discrete measures under permutation-invariance, and derive adequate network architectures for DDEQs. In experiments, we show that they can compete with state-of-the-art models in tasks such as point cloud classification and point cloud completion, while being significantly more parameter-efficient.
Mirror and Preconditioned Gradient Descent in Wasserstein Space
Jun 13, 2024



As the problem of minimizing functionals on the Wasserstein space encompasses many applications in machine learning, different optimization algorithms on $\mathbb{R}^d$ have received their counterpart analog on the Wasserstein space. We focus here on lifting two explicit algorithms: mirror descent and preconditioned gradient descent. These algorithms have been introduced to better capture the geometry of the function to minimize and are provably convergent under appropriate (namely relative) smoothness and convexity conditions. Adapting these notions to the Wasserstein space, we prove guarantees of convergence of some Wasserstein-gradient-based discrete-time schemes for new pairings of objective functionals and regularizers. The difficulty here is to carefully select along which curves the functionals should be smooth and convex. We illustrate the advantages of adapting the geometry induced by the regularizer on ill-conditioned optimization tasks, and showcase the improvement of choosing different discrepancies and geometries in a computational biology task of aligning single-cells.
Sliced-Wasserstein Distances and Flows on Cartan-Hadamard Manifolds
Mar 11, 2024



While many Machine Learning methods were developed or transposed on Riemannian manifolds to tackle data with known non Euclidean geometry, Optimal Transport (OT) methods on such spaces have not received much attention. The main OT tool on these spaces is the Wasserstein distance which suffers from a heavy computational burden. On Euclidean spaces, a popular alternative is the Sliced-Wasserstein distance, which leverages a closed-form solution of the Wasserstein distance in one dimension, but which is not readily available on manifolds. In this work, we derive general constructions of Sliced-Wasserstein distances on Cartan-Hadamard manifolds, Riemannian manifolds with non-positive curvature, which include among others Hyperbolic spaces or the space of Symmetric Positive Definite matrices. Then, we propose different applications. Additionally, we derive non-parametric schemes to minimize these new distances by approximating their Wasserstein gradient flows.
Leveraging Optimal Transport via Projections on Subspaces for Machine Learning Applications
Nov 23, 2023Optimal Transport has received much attention in Machine Learning as it allows to compare probability distributions by exploiting the geometry of the underlying space. However, in its original formulation, solving this problem suffers from a significant computational burden. Thus, a meaningful line of work consists at proposing alternatives to reduce this burden while still enjoying its properties. In this thesis, we focus on alternatives which use projections on subspaces. The main such alternative is the Sliced-Wasserstein distance, which we first propose to extend to Riemannian manifolds in order to use it in Machine Learning applications for which using such spaces has been shown to be beneficial in the recent years. We also study sliced distances between positive measures in the so-called unbalanced OT problem. Back to the original Euclidean Sliced-Wasserstein distance between probability measures, we study the dynamic of gradient flows when endowing the space with this distance in place of the usual Wasserstein distance. Then, we investigate the use of the Busemann function, a generalization of the inner product in metric spaces, in the space of probability measures. Finally, we extend the subspace detour approach to incomparable spaces using the Gromov-Wasserstein distance.
Fast Optimal Transport through Sliced Wasserstein Generalized Geodesics
Jul 04, 2023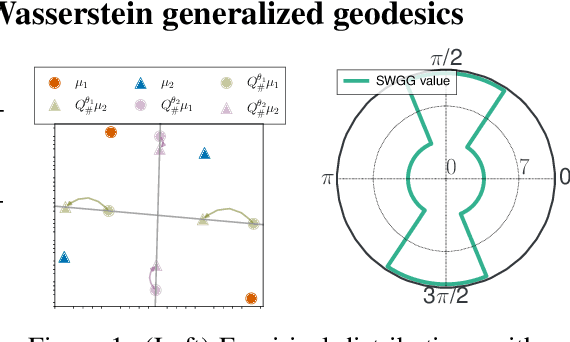

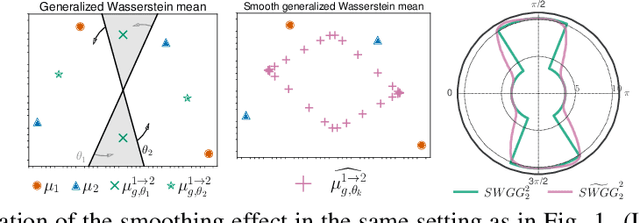
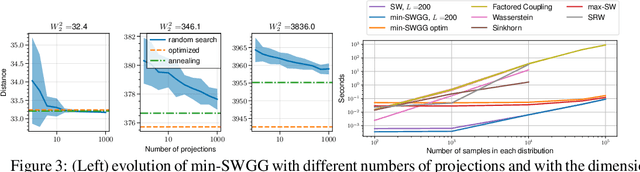
Wasserstein distance (WD) and the associated optimal transport plan have been proven useful in many applications where probability measures are at stake. In this paper, we propose a new proxy of the squared WD, coined min-SWGG, that is based on the transport map induced by an optimal one-dimensional projection of the two input distributions. We draw connections between min-SWGG and Wasserstein generalized geodesics in which the pivot measure is supported on a line. We notably provide a new closed form for the exact Wasserstein distance in the particular case of one of the distributions supported on a line allowing us to derive a fast computational scheme that is amenable to gradient descent optimization. We show that min-SWGG is an upper bound of WD and that it has a complexity similar to as Sliced-Wasserstein, with the additional feature of providing an associated transport plan. We also investigate some theoretical properties such as metricity, weak convergence, computational and topological properties. Empirical evidences support the benefits of min-SWGG in various contexts, from gradient flows, shape matching and image colorization, among others.
Unbalanced Optimal Transport meets Sliced-Wasserstein
Jun 12, 2023Optimal transport (OT) has emerged as a powerful framework to compare probability measures, a fundamental task in many statistical and machine learning problems. Substantial advances have been made over the last decade in designing OT variants which are either computationally and statistically more efficient, or more robust to the measures and datasets to compare. Among them, sliced OT distances have been extensively used to mitigate optimal transport's cubic algorithmic complexity and curse of dimensionality. In parallel, unbalanced OT was designed to allow comparisons of more general positive measures, while being more robust to outliers. In this paper, we propose to combine these two concepts, namely slicing and unbalanced OT, to develop a general framework for efficiently comparing positive measures. We propose two new loss functions based on the idea of slicing unbalanced OT, and study their induced topology and statistical properties. We then develop a fast Frank-Wolfe-type algorithm to compute these loss functions, and show that the resulting methodology is modular as it encompasses and extends prior related work. We finally conduct an empirical analysis of our loss functions and methodology on both synthetic and real datasets, to illustrate their relevance and applicability.
Sliced-Wasserstein on Symmetric Positive Definite Matrices for M/EEG Signals
Mar 10, 2023When dealing with electro or magnetoencephalography records, many supervised prediction tasks are solved by working with covariance matrices to summarize the signals. Learning with these matrices requires using Riemanian geometry to account for their structure. In this paper, we propose a new method to deal with distributions of covariance matrices and demonstrate its computational efficiency on M/EEG multivariate time series. More specifically, we define a Sliced-Wasserstein distance between measures of symmetric positive definite matrices that comes with strong theoretical guarantees. Then, we take advantage of its properties and kernel methods to apply this distance to brain-age prediction from MEG data and compare it to state-of-the-art algorithms based on Riemannian geometry. Finally, we show that it is an efficient surrogate to the Wasserstein distance in domain adaptation for Brain Computer Interface applications.
Hyperbolic Sliced-Wasserstein via Geodesic and Horospherical Projections
Nov 18, 2022



It has been shown beneficial for many types of data which present an underlying hierarchical structure to be embedded in hyperbolic spaces. Consequently, many tools of machine learning were extended to such spaces, but only few discrepancies to compare probability distributions defined over those spaces exist. Among the possible candidates, optimal transport distances are well defined on such Riemannian manifolds and enjoy strong theoretical properties, but suffer from high computational cost. On Euclidean spaces, sliced-Wasserstein distances, which leverage a closed-form of the Wasserstein distance in one dimension, are more computationally efficient, but are not readily available on hyperbolic spaces. In this work, we propose to derive novel hyperbolic sliced-Wasserstein discrepancies. These constructions use projections on the underlying geodesics either along horospheres or geodesics. We study and compare them on different tasks where hyperbolic representations are relevant, such as sampling or image classification.