 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Jun 17, 2025Tokenization imposes a fixed granularity on the input text, freezing how a language model operates on data and how far in the future it predicts. Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model stuck with that choice. We relax this rigidity by introducing an autoregressive U-Net that learns to embed its own tokens as it trains. The network reads raw bytes, pools them into words, then pairs of words, then up to 4 words, giving it a multi-scale view of the sequence. At deeper stages, the model must predict further into the future -- anticipating the next few words rather than the next byte -- so deeper stages focus on broader semantic patterns while earlier stages handle fine details. When carefully tuning and controlling pretraining compute, shallow hierarchies tie strong BPE baselines, and deeper hierarchies have a promising trend. Because tokenization now lives inside the model, the same system can handle character-level tasks and carry knowledge across low-resource languages.
Better & Faster Large Language Models via Multi-token Prediction
Apr 30, 2024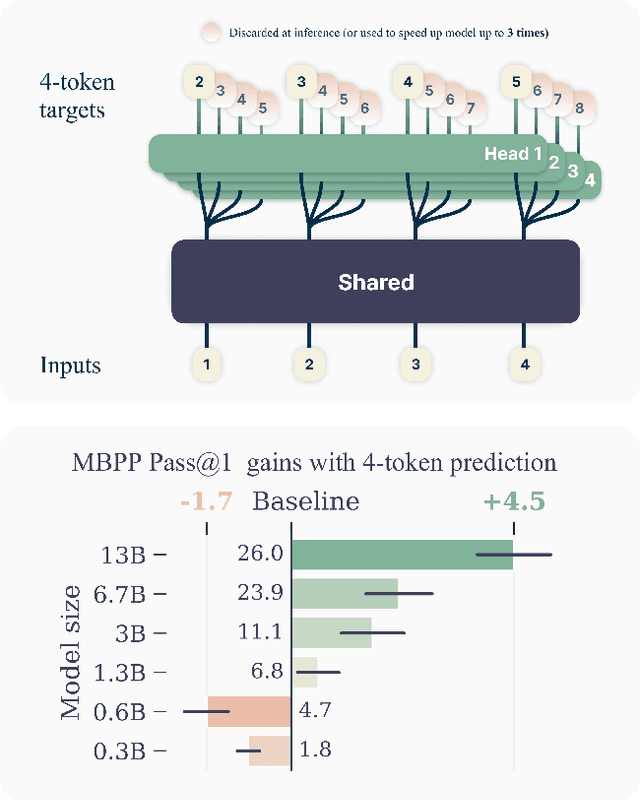
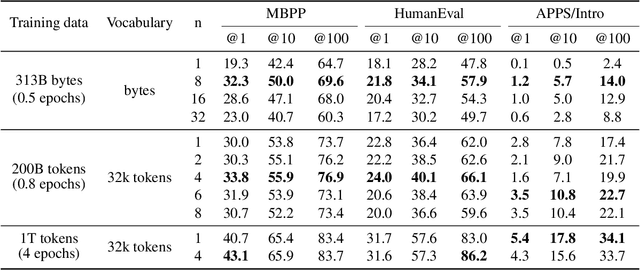
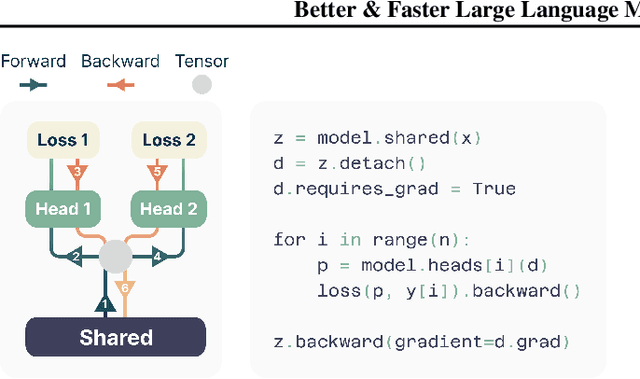
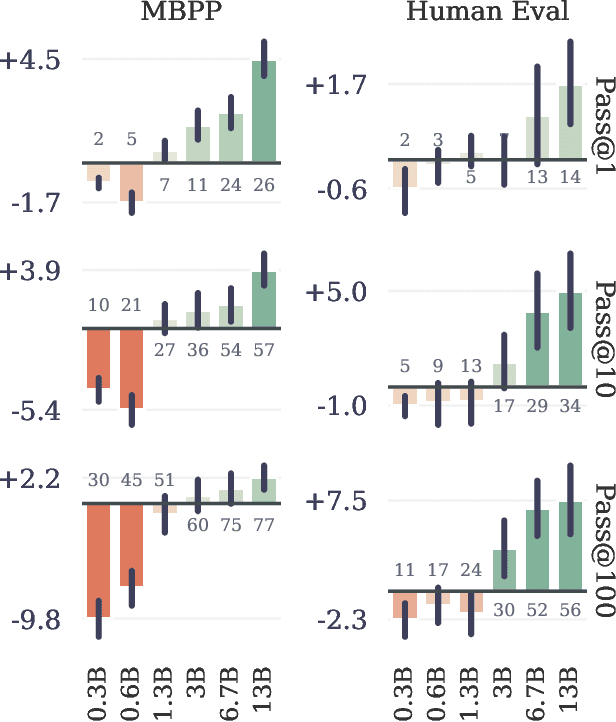
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Simple data balancing achieves competitive worst-group-accuracy
Oct 27, 2021



We study the problem of learning classifiers that perform well across (known or unknown) groups of data. After observing that common worst-group-accuracy datasets suffer from substantial imbalances, we set out to compare state-of-the-art methods to simple balancing of classes and groups by either subsampling or reweighting data. Our results show that these data balancing baselines achieve state-of-the-art-accuracy, while being faster to train and requiring no additional hyper-parameters. In addition, we highlight that access to group information is most critical for model selection purposes, and not so much during training. All in all, our findings beg closer examination of benchmarks and methods for research in worst-group-accuracy optimization.
Masked Adversarial Generation for Neural Machine Translation
Sep 01, 2021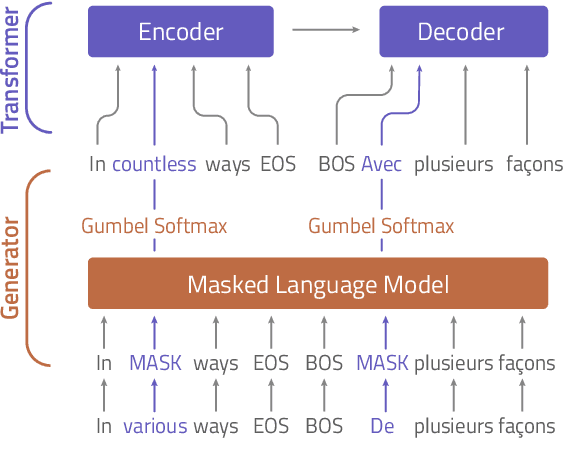
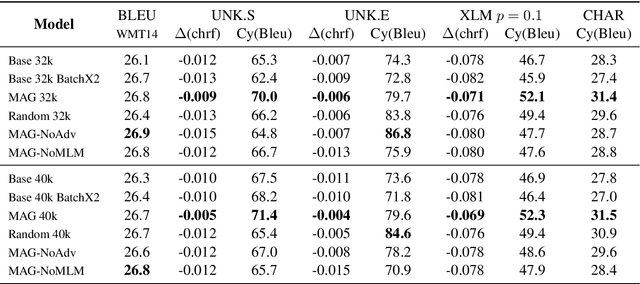
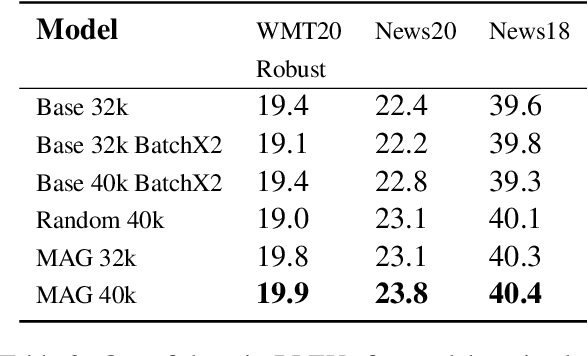
Attacking Neural Machine Translation models is an inherently combinatorial task on discrete sequences, solved with approximate heuristics. Most methods use the gradient to attack the model on each sample independently. Instead of mechanically applying the gradient, could we learn to produce meaningful adversarial attacks ? In contrast to existing approaches, we learn to attack a model by training an adversarial generator based on a language model. We propose the Masked Adversarial Generation (MAG) model, that learns to perturb the translation model throughout the training process. The experiments show that it improves the robustness of machine translation models, while being faster than competing methods.
VirAAL: Virtual Adversarial Active Learning
May 14, 2020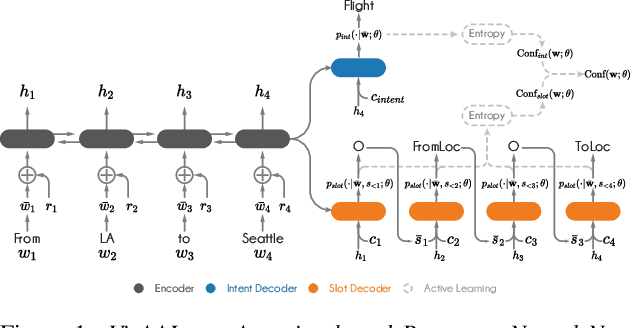
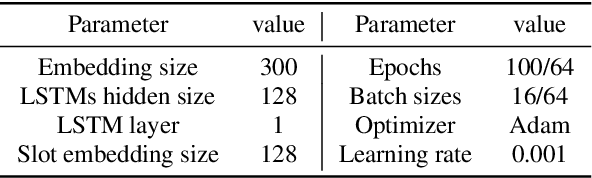
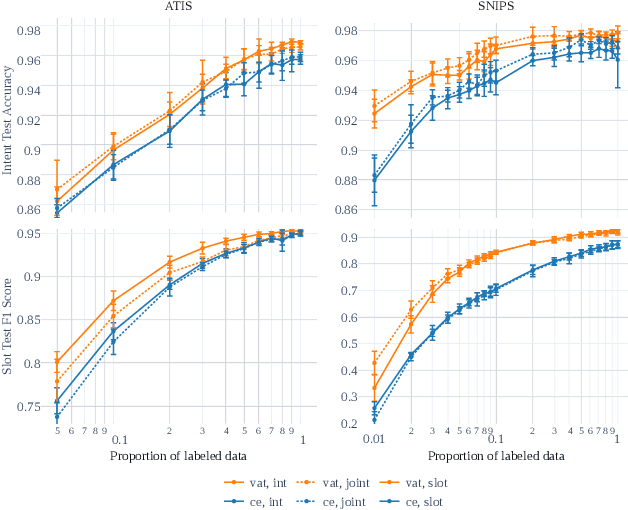
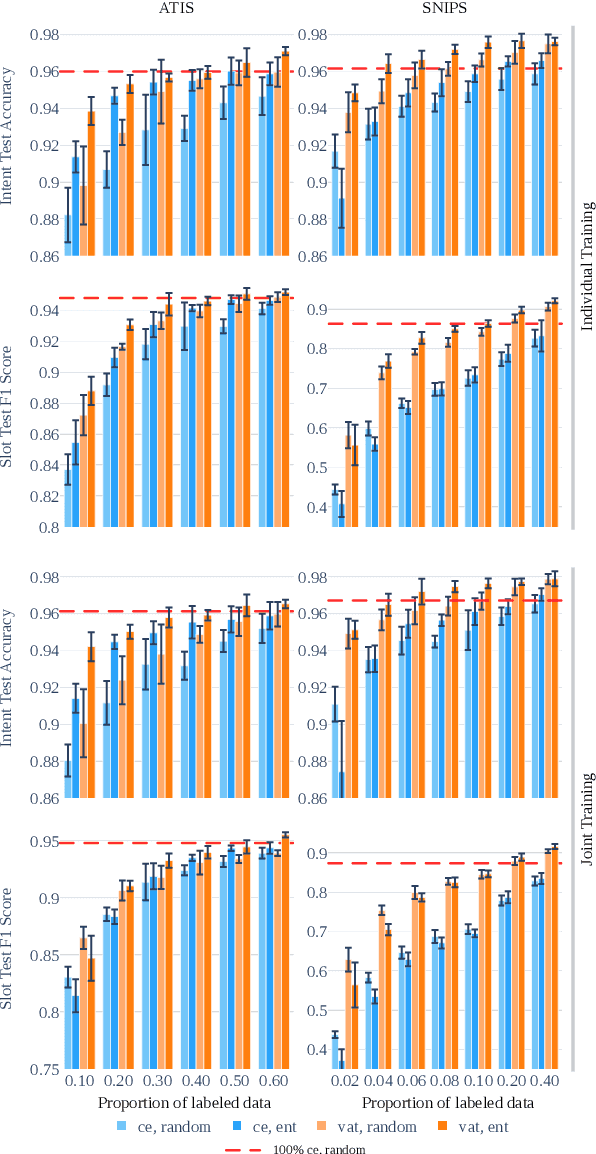
This paper presents VirAAL, an Active Learning framework based on Adversarial Training. VirAAL aims to reduce the effort of annotation in Natural Language Understanding (NLU). VirAAL is based on Virtual Adversarial Training (VAT), a semi-supervised approach that regularizes the model through Local Distributional Smoothness. With that, adversarial perturbations are added to the inputs making the posterior distribution more consistent. Therefore, entropy-based Active Learning becomes robust by querying more informative samples without requiring additional components. The first set of experiments studies the impact of VAT on NLU tasks (joint or not) within low labeled data regimes. The second set shows the effect of VirAAL in an Active Learning (AL) process. Results demonstrate that VAT is robust even on multitask training where the adversarial noise is computed from multiple loss functions. Substantial improvements are observed with entropy-based AL with VirAAL for querying data to annotate. VirAAL is an inexpensive method in terms of AL computation with a positive impact on data sampling. Furthermore, VirAAL decreases annotations in AL up to 80%.