 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATATA: A weakly-supervised MAthematical Tool-Assisted reasoning for Tabular Applications
Dec 10, 2024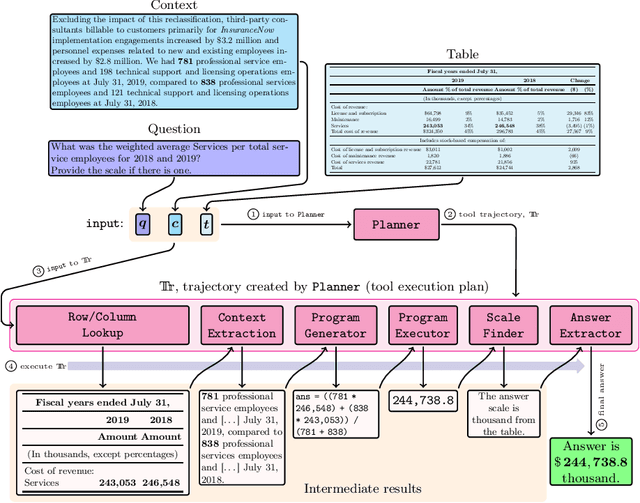
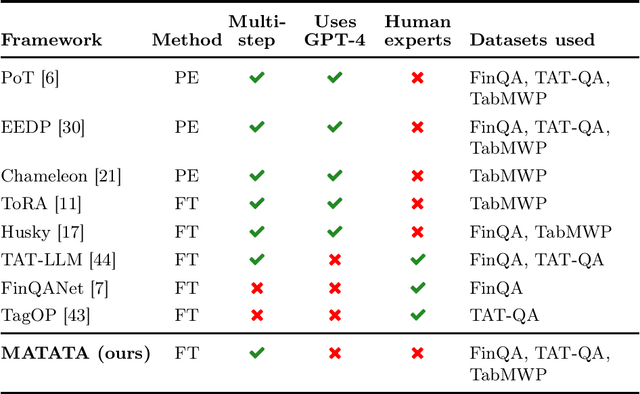

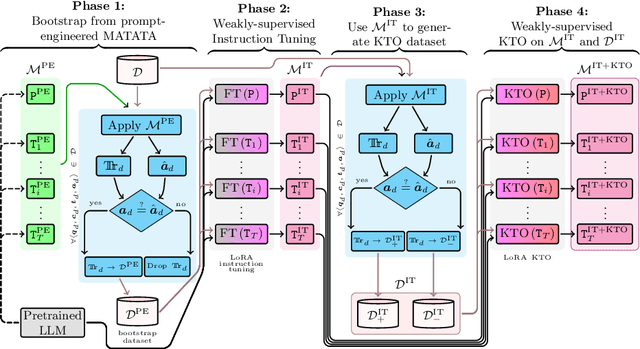
Mathematical reasoning capabilities are increasing with tool-augmented language agents, but methods often rely either on closed-source or large models, external data, or extensive prompt engineering. This work introduces MATATA, a novel cost-effective method to train LLM agents for tabular data problems through reasoning, planning, and tool use. With a progressive self-improvement paradigm and an iterative weak supervision, it empowers 3.8B/8B Small Language Models (SLMs), particularly suited for local hosting and sensitive business contexts where data privacy is crucial. By employing a flexible and reusable tools across different datasets, it achieves robust performance with effective scalability across shared tasks. Experiments show that MATATA reaches state-of-the-art performances on FinQA and TAT-QA among reasoning frameworks based on open-source models. Moreover, MATATA models compete with GPT-4 based frameworks on TabMWP, while being SLMs.
MATATA: a weak-supervised MAthematical Tool-Assisted reasoning for Tabular Applications
Dec 02, 2024Mathematical reasoning capabilities are increasing with tool-augmented language agents, but methods often rely either on closed-source or large models, external data, or extensive prompt engineering. This work introduces MATATA, a novel cost-effective method to train LLM agents for tabular data problems through reasoning, planning, and tool use. With a progressive self-improvement paradigm and an iterative weak supervision, it empowers 3.8B/8B Small Language Models (SLMs), particularly suited for local hosting and sensitive business contexts where data privacy is crucial. By employing a flexible and reusable tools across different datasets, it achieves robust performance with effective scalability across shared tasks. Experiments show that MATATA reaches state-of-the-art performances on FinQA and TAT-QA among reasoning frameworks based on open-source models. Moreover, MATATA models compete with GPT-4 based frameworks on TabMWP, while being SLMs.
Masked ELMo: An evolution of ELMo towards fully contextual RNN language models
Oct 08, 2020



This paper presents Masked ELMo, a new RNN-based model for language model pre-training, evolved from the ELMo language model. Contrary to ELMo which only uses independent left-to-right and right-to-left contexts, Masked ELMo learns fully bidirectional word representations. To achieve this, we use the same Masked language model objective as BERT. Additionally, thanks to optimizations on the LSTM neuron, the integration of mask accumulation and bidirectional truncated backpropagation through time, we have increased the training speed of the model substantially. All these improvements make it possible to pre-train a better language model than ELMo while maintaining a low computational cost. We evaluate Masked ELMo by comparing it to ELMo within the same protocol on the GLUE benchmark, where our model outperforms significantly ELMo and is competitive with transformer approaches.
VirAAL: Virtual Adversarial Active Learning
May 14, 2020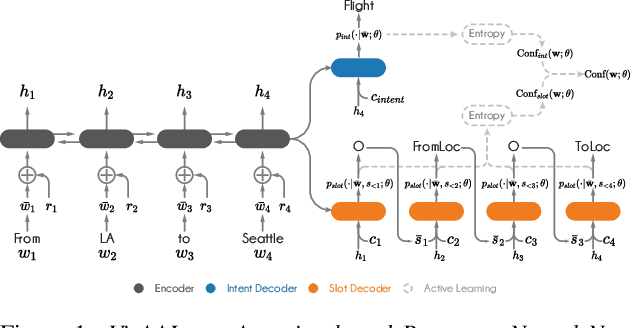
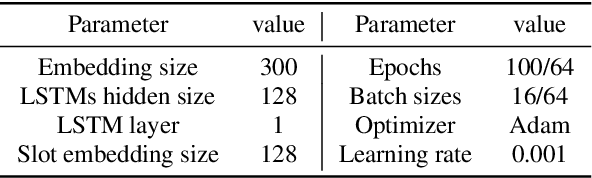
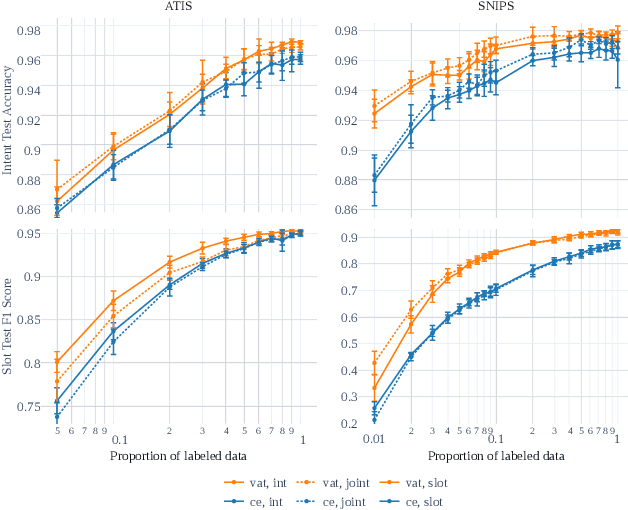
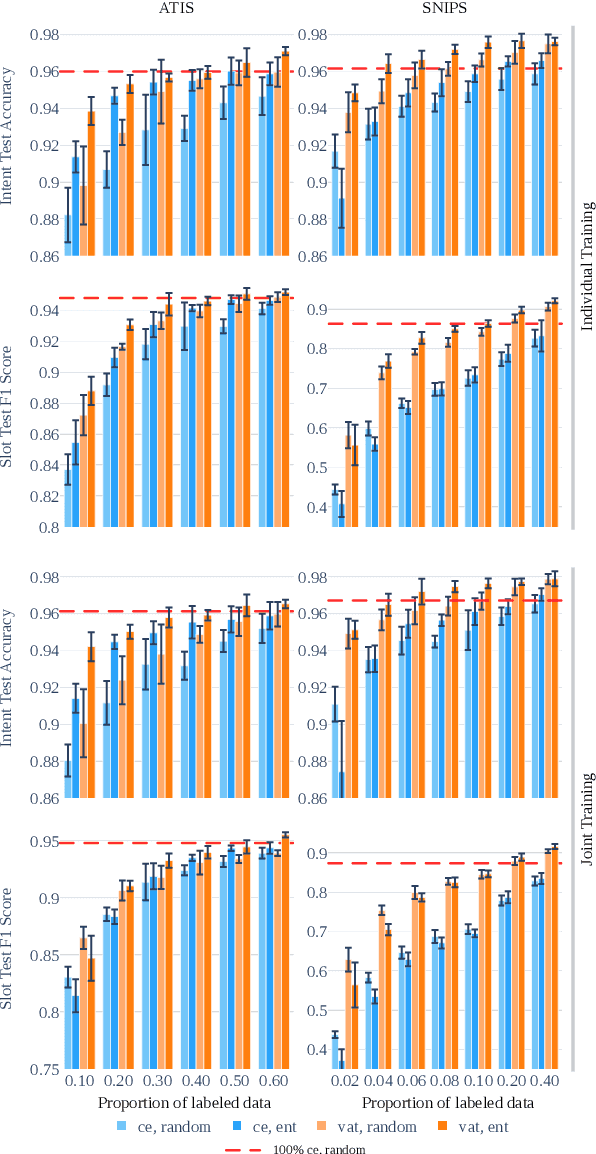
This paper presents VirAAL, an Active Learning framework based on Adversarial Training. VirAAL aims to reduce the effort of annotation in Natural Language Understanding (NLU). VirAAL is based on Virtual Adversarial Training (VAT), a semi-supervised approach that regularizes the model through Local Distributional Smoothness. With that, adversarial perturbations are added to the inputs making the posterior distribution more consistent. Therefore, entropy-based Active Learning becomes robust by querying more informative samples without requiring additional components. The first set of experiments studies the impact of VAT on NLU tasks (joint or not) within low labeled data regimes. The second set shows the effect of VirAAL in an Active Learning (AL) process. Results demonstrate that VAT is robust even on multitask training where the adversarial noise is computed from multiple loss functions. Substantial improvements are observed with entropy-based AL with VirAAL for querying data to annotate. VirAAL is an inexpensive method in terms of AL computation with a positive impact on data sampling. Furthermore, VirAAL decreases annotations in AL up to 80%.