 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting gets full Attention for Relational Learning
Paper and Code
Feb 22, 2024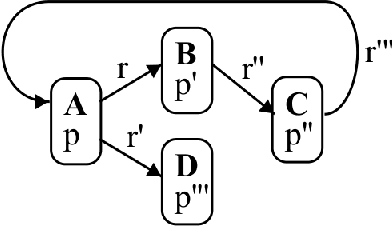
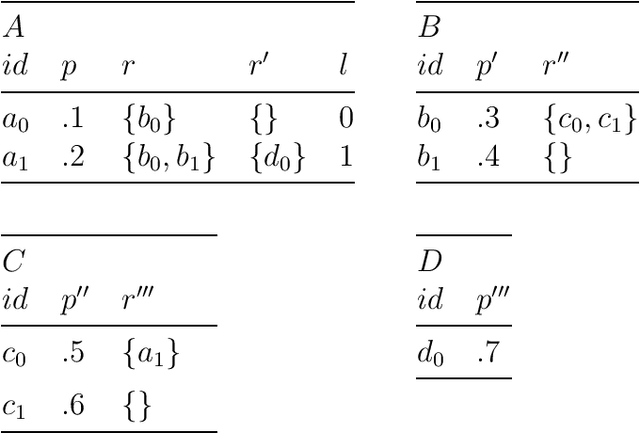
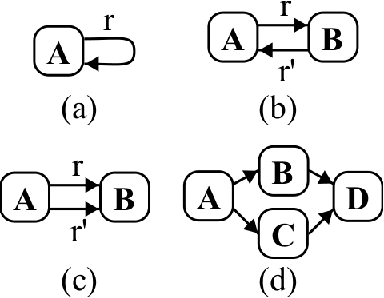

More often than not in benchmark supervised ML, tabular data is flat, i.e. consists of a single $m \times d$ (rows, columns) file, but cases abound in the real world where observations are described by a set of tables with structural relationships. Neural nets-based deep models are a classical fit to incorporate general topological dependence among description features (pixels, words, etc.), but their suboptimality to tree-based models on tabular data is still well documented. In this paper, we introduce an attention mechanism for structured data that blends well with tree-based models in the training context of (gradient) boosting. Each aggregated model is a tree whose training involves two steps: first, simple tabular models are learned descending tables in a top-down fashion with boosting's class residuals on tables' features. Second, what has been learned progresses back bottom-up via attention and aggregation mechanisms, progressively crafting new features that complete at the end the set of observation features over which a single tree is learned, boosting's iteration clock is incremented and new class residuals are computed. Experiments on simulated and real-world domains display the competitiveness of our method against a state of the art containing both tree-based and neural nets-based models.