 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Retrieval Barrier: Indirect Prompt Injection in the Wild for LLM Systems
Jan 11, 2026Large language models (LLMs) increasingly rely on retrieving information from external corpora. This creates a new attack surface: indirect prompt injection (IPI), where hidden instructions are planted in the corpora and hijack model behavior once retrieved. Previous studies have highlighted this risk but often avoid the hardest step: ensuring that malicious content is actually retrieved. In practice, unoptimized IPI is rarely retrieved under natural queries, which leaves its real-world impact unclear. We address this challenge by decomposing the malicious content into a trigger fragment that guarantees retrieval and an attack fragment that encodes arbitrary attack objectives. Based on this idea, we design an efficient and effective black-box attack algorithm that constructs a compact trigger fragment to guarantee retrieval for any attack fragment. Our attack requires only API access to embedding models, is cost-efficient (as little as $0.21 per target user query on OpenAI's embedding models), and achieves near-100% retrieval across 11 benchmarks and 8 embedding models (including both open-source models and proprietary services). Based on this attack, we present the first end-to-end IPI exploits under natural queries and realistic external corpora, spanning both RAG and agentic systems with diverse attack objectives. These results establish IPI as a practical and severe threat: when a user issued a natural query to summarize emails on frequently asked topics, a single poisoned email was sufficient to coerce GPT-4o into exfiltrating SSH keys with over 80% success in a multi-agent workflow. We further evaluate several defenses and find that they are insufficient to prevent the retrieval of malicious text, highlighting retrieval as a critical open vulnerability.
Feature Inference Attack on Shapley Values
Jul 16, 2024



As a solution concept in cooperative game theory, Shapley value is highly recognized in model interpretability studies and widely adopted by the leading Machine Learning as a Service (MLaaS) providers, such as Google, Microsoft, and IBM. However, as the Shapley value-based model interpretability methods have been thoroughly studied, few researchers consider the privacy risks incurred by Shapley values, despite that interpretability and privacy are two foundations of machine learning (ML) models. In this paper, we investigate the privacy risks of Shapley value-based model interpretability methods using feature inference attacks: reconstructing the private model inputs based on their Shapley value explanations. Specifically, we present two adversaries. The first adversary can reconstruct the private inputs by training an attack model based on an auxiliary dataset and black-box access to the model interpretability services. The second adversary, even without any background knowledge, can successfully reconstruct most of the private features by exploiting the local linear correlations between the model inputs and outputs. We perform the proposed attacks on the leading MLaaS platforms, i.e., Google Cloud, Microsoft Azure, and IBM aix360. The experimental results demonstrate the vulnerability of the state-of-the-art Shapley value-based model interpretability methods used in the leading MLaaS platforms and highlight the significance and necessity of designing privacy-preserving model interpretability methods in future studies. To our best knowledge, this is also the first work that investigates the privacy risks of Shapley values.
Exploring Privacy and Fairness Risks in Sharing Diffusion Models: An Adversarial Perspective
Mar 04, 2024



Diffusion models have recently gained significant attention in both academia and industry due to their impressive generative performance in terms of both sampling quality and distribution coverage. Accordingly, proposals are made for sharing pre-trained diffusion models across different organizations, as a way of improving data utilization while enhancing privacy protection by avoiding sharing private data directly. However, the potential risks associated with such an approach have not been comprehensively examined. In this paper, we take an adversarial perspective to investigate the potential privacy and fairness risks associated with the sharing of diffusion models. Specifically, we investigate the circumstances in which one party (the sharer) trains a diffusion model using private data and provides another party (the receiver) black-box access to the pre-trained model for downstream tasks. We demonstrate that the sharer can execute fairness poisoning attacks to undermine the receiver's downstream models by manipulating the training data distribution of the diffusion model. Meanwhile, the receiver can perform property inference attacks to reveal the distribution of sensitive features in the sharer's dataset. Our experiments conducted on real-world datasets demonstrate remarkable attack performance on different types of diffusion models, which highlights the critical importance of robust data auditing and privacy protection protocols in pertinent applications.
Passive Inference Attacks on Split Learning via Adversarial Regularization
Oct 16, 2023



Split Learning (SL) has emerged as a practical and efficient alternative to traditional federated learning. While previous attempts to attack SL have often relied on overly strong assumptions or targeted easily exploitable models, we seek to develop more practical attacks. We introduce SDAR, a novel attack framework against SL with an honest-but-curious server. SDAR leverages auxiliary data and adversarial regularization to learn a decodable simulator of the client's private model, which can effectively infer the client's private features under the vanilla SL, and both features and labels under the U-shaped SL. We perform extensive experiments in both configurations to validate the effectiveness of our proposed attacks. Notably, in challenging but practical scenarios where existing passive attacks struggle to reconstruct the client's private data effectively, SDAR consistently achieves attack performance comparable to active attacks. On CIFAR-10, at the deep split level of 7, SDAR achieves private feature reconstruction with less than 0.025 mean squared error in both the vanilla and the U-shaped SL, and attains a label inference accuracy of over 98% in the U-shaped setting, while existing attacks fail to produce non-trivial results.
A Fusion-Denoising Attack on InstaHide with Data Augmentation
May 17, 2021


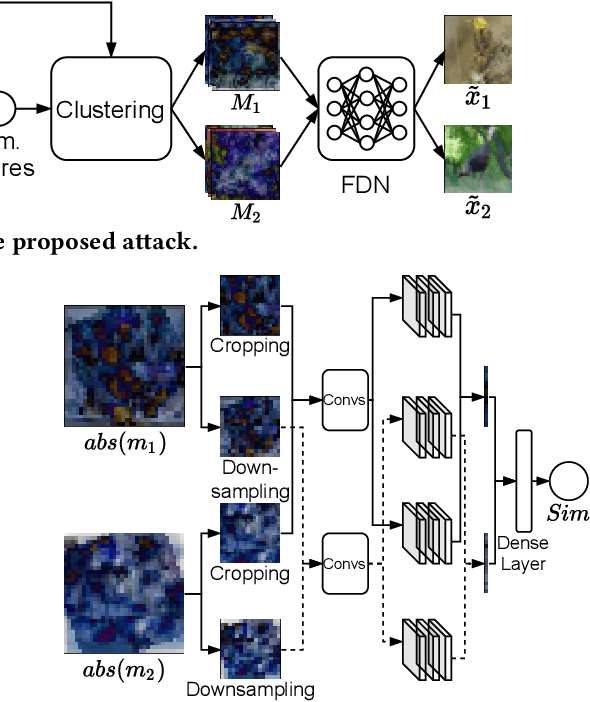
InstaHide is a state-of-the-art mechanism for protecting private training images in collaborative learning. It works by mixing multiple private images and modifying them in such a way that their visual features are no longer distinguishable to the naked eye, without significantly degrading the accuracy of training. In recent work, however, Carlini et al. show that it is possible to reconstruct private images from the encrypted dataset generated by InstaHide, by exploiting the correlations among the encrypted images. Nevertheless, Carlini et al.'s attack relies on the assumption that each private image is used without modification when mixing up with other private images. As a consequence, it could be easily defeated by incorporating data augmentation into InstaHide. This leads to a natural question: is InstaHide with data augmentation secure? This paper provides a negative answer to the above question, by present an attack for recovering private images from the outputs of InstaHide even when data augmentation is present. The basic idea of our attack is to use a comparative network to identify encrypted images that are likely to correspond to the same private image, and then employ a fusion-denoising network for restoring the private image from the encrypted ones, taking into account the effects of data augmentation. Extensive experiments demonstrate the effectiveness of the proposed attack in comparison to Carlini et al.'s attack.
Feature Inference Attack on Model Predictions in Vertical Federated Learning
Oct 20, 2020Federated learning (FL) is an emerging paradigm for facilitating multiple organizations' data collaboration without revealing their private data to each other. Recently, vertical FL, where the participating organizations hold the same set of samples but with disjoint features and only one organization owns the labels, has received increased attention. This paper presents several feature inference attack methods to investigate the potential privacy leakages in the model prediction stage of vertical FL. The attack methods consider the most stringent setting that the adversary controls only the trained vertical FL model and the model predictions, relying on no background information. We first propose two specific attacks on the logistic regression (LR) and decision tree (DT) models, according to individual prediction output. We further design a general attack method based on multiple prediction outputs accumulated by the adversary to handle complex models, such as neural networks (NN) and random forest (RF) models. Experimental evaluations demonstrate the effectiveness of the proposed attacks and highlight the need for designing private mechanisms to protect the prediction outputs in vertical FL.
Exploiting Defenses against GAN-Based Feature Inference Attacks in Federated Learning
Apr 27, 2020
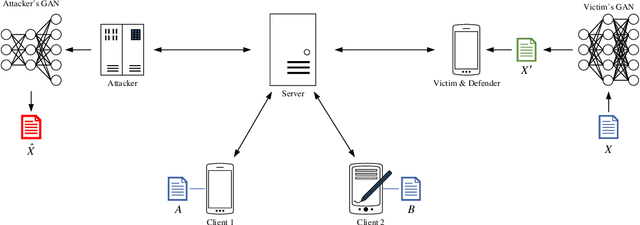

With the rapid increasing of computing power and dataset volume, machine learning algorithms have been widely adopted in classification and regression tasks. Though demonstrating superior performance than traditional algorithms, machine learning algorithms are vulnerable to adversarial attacks, such as model inversion and membership inference. To protect user privacy, federated learning is proposed for decentralized model training. Recent studies, however, show that Generative Adversarial Network (GAN) based attacks could be applied in federated learning to effectively reconstruct user-level privacy data. In this paper, we exploit defenses against GAN-based attacks in federated learning. Given that GAN could effectively learn the distribution of training data, GAN-based attacks aim to reconstruct human-distinguishable images from victim's personal dataset. To defense such attacks, we propose a framework, Anti-GAN, to prevent attackers from learning the real distribution of victim's data. More specifically, victims first project personal training data onto a GAN's generator, then feed the generated fake images into the global shared model for federated learning. In addition, we design a new loss function to encourage victim's GAN to generate images which not only have similar classification features with original training data, but also have indistinguishable visual features to prevent inference attack.