 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Defenses against GAN-Based Feature Inference Attacks in Federated Learning
Apr 27, 2020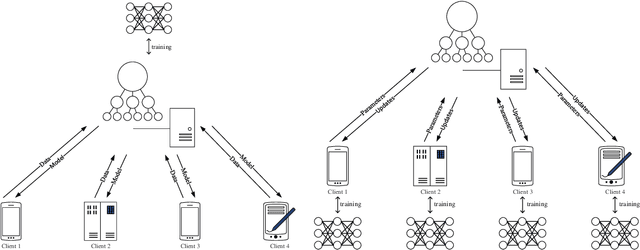
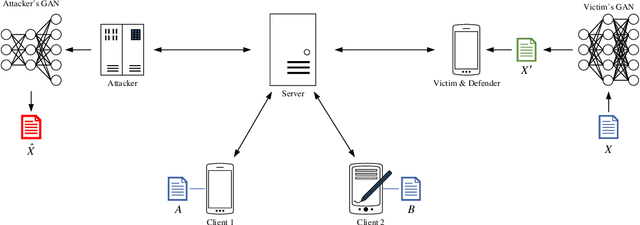

With the rapid increasing of computing power and dataset volume, machine learning algorithms have been widely adopted in classification and regression tasks. Though demonstrating superior performance than traditional algorithms, machine learning algorithms are vulnerable to adversarial attacks, such as model inversion and membership inference. To protect user privacy, federated learning is proposed for decentralized model training. Recent studies, however, show that Generative Adversarial Network (GAN) based attacks could be applied in federated learning to effectively reconstruct user-level privacy data. In this paper, we exploit defenses against GAN-based attacks in federated learning. Given that GAN could effectively learn the distribution of training data, GAN-based attacks aim to reconstruct human-distinguishable images from victim's personal dataset. To defense such attacks, we propose a framework, Anti-GAN, to prevent attackers from learning the real distribution of victim's data. More specifically, victims first project personal training data onto a GAN's generator, then feed the generated fake images into the global shared model for federated learning. In addition, we design a new loss function to encourage victim's GAN to generate images which not only have similar classification features with original training data, but also have indistinguishable visual features to prevent inference attack.