 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Using Python for Model Inference in Deep Learning
Apr 01, 2021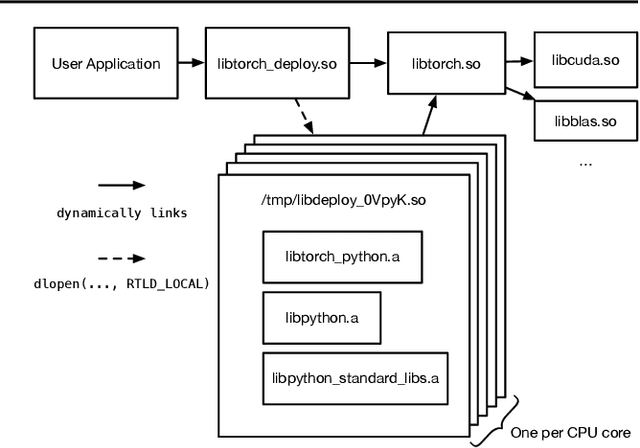


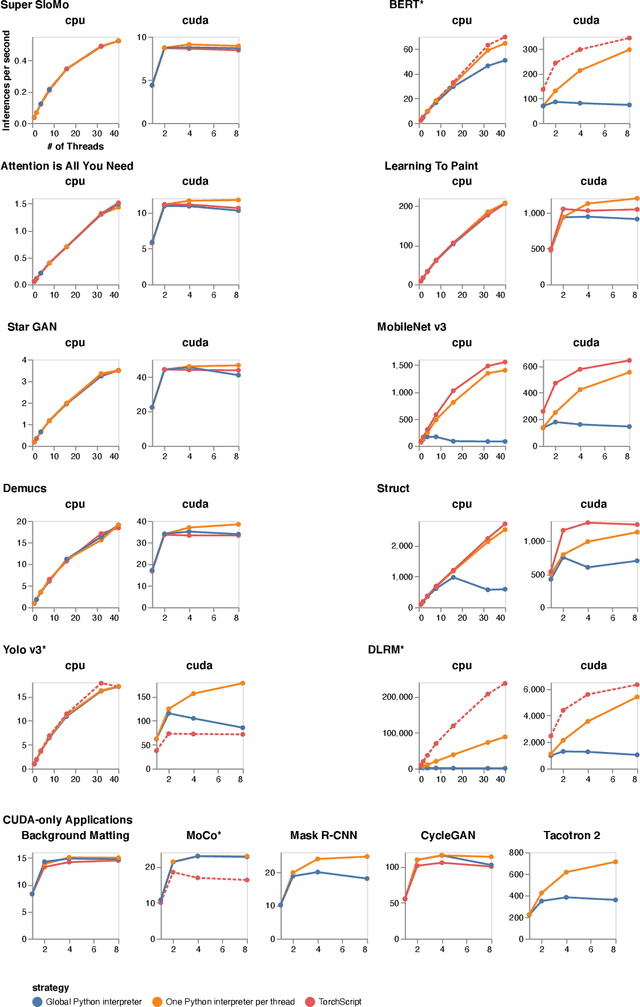
Python has become the de-facto language for training deep neural networks, coupling a large suite of scientific computing libraries with efficient libraries for tensor computation such as PyTorch or TensorFlow. However, when models are used for inference they are typically extracted from Python as TensorFlow graphs or TorchScript programs in order to meet performance and packaging constraints. The extraction process can be time consuming, impeding fast prototyping. We show how it is possible to meet these performance and packaging constraints while performing inference in Python. In particular, we present a way of using multiple Python interpreters within a single process to achieve scalable inference and describe a new container format for models that contains both native Python code and data. This approach simplifies the model deployment story by eliminating the model extraction step, and makes it easier to integrate existing performance-enhancing Python libraries. We evaluate our design on a suite of popular PyTorch models on Github, showing how they can be packaged in our inference format, and comparing their performance to TorchScript. For larger models, our packaged Python models perform the same as TorchScript, and for smaller models where there is some Python overhead, our multi-interpreter approach ensures inference is still scalable.