 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Parallelism Opportunities with Deep Learning Frameworks
Paper and Code
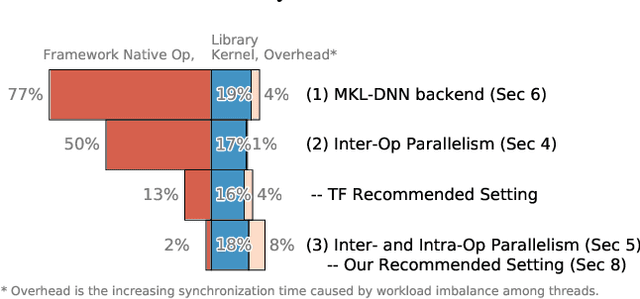
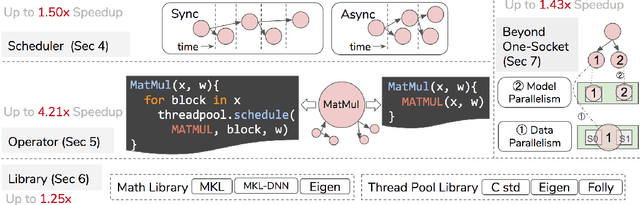
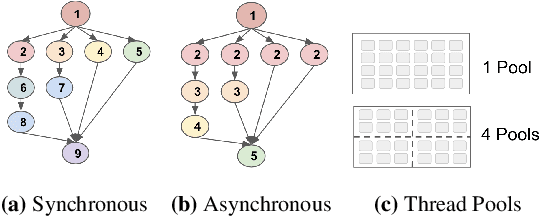
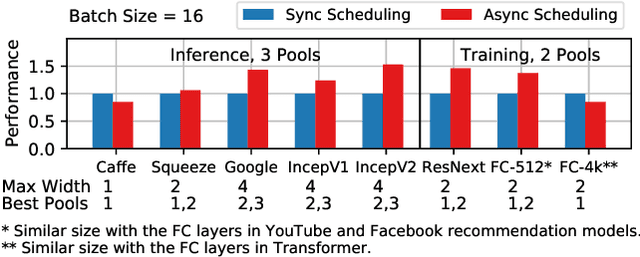
State-of-the-art machine learning frameworks support a wide variety of design features to enable a flexible machine learning programming interface and to ease the programmability burden on machine learning developers. Identifying and using a performance-optimal setting in feature-rich frameworks, however, involves a non-trivial amount of performance characterization and domain-specific knowledge. This paper takes a deep dive into analyzing the performance impact of key design features and the role of parallelism. The observations and insights distill into a simple set of guidelines that one can use to achieve much higher training and inference speedup. The evaluation results show that our proposed performance tuning guidelines outperform both the Intel and TensorFlow recommended settings by 1.29x and 1.34x, respectively, across a diverse set of real-world deep learning models.