 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Decision Theory with Counterfactual Loss
May 13, 2025Classical statistical decision theory evaluates treatment choices based solely on observed outcomes. However, by ignoring counterfactual outcomes, it cannot assess the quality of decisions relative to feasible alternatives. For example, the quality of a physician's decision may depend not only on patient survival, but also on whether a less invasive treatment could have produced a similar result. To address this limitation, we extend standard decision theory to incorporate counterfactual losses--criteria that evaluate decisions using all potential outcomes. The central challenge in this generalization is identification: because only one potential outcome is observed for each unit, the associated risk under a counterfactual loss is generally not identifiable. We show that under the assumption of strong ignorability, a counterfactual risk is identifiable if and only if the counterfactual loss function is additive in the potential outcomes. Moreover, we demonstrate that additive counterfactual losses can yield treatment recommendations that differ from those based on standard loss functions, provided that the decision problem involves more than two treatment options.
Using AI to Summarize US Presidential Campaign TV Advertisement Videos, 1952-2012
Mar 28, 2025This paper introduces the largest and most comprehensive dataset of US presidential campaign television advertisements, available in digital format. The dataset also includes machine-searchable transcripts and high-quality summaries designed to facilitate a variety of academic research. To date, there has been great interest in collecting and analyzing US presidential campaign advertisements, but the need for manual procurement and annotation led many to rely on smaller subsets. We design a large-scale parallelized, AI-based analysis pipeline that automates the laborious process of preparing, transcribing, and summarizing videos. We then apply this methodology to the 9,707 presidential ads from the Julian P. Kanter Political Commercial Archive. We conduct extensive human evaluations to show that these transcripts and summaries match the quality of manually generated alternatives. We illustrate the value of this data by including an application that tracks the genesis and evolution of current focal issue areas over seven decades of presidential elections. Our analysis pipeline and codebase also show how to use LLM-based tools to obtain high-quality summaries for other video datasets.
Minimax Regret Estimation for Generalizing Heterogeneous Treatment Effects with Multisite Data
Dec 15, 2024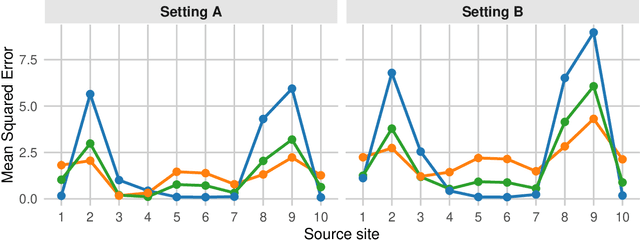



To test scientific theories and develop individualized treatment rules, researchers often wish to learn heterogeneous treatment effects that can be consistently found across diverse populations and contexts. We consider the problem of generalizing heterogeneous treatment effects (HTE) based on data from multiple sites. A key challenge is that a target population may differ from the source sites in unknown and unobservable ways. This means that the estimates from site-specific models lack external validity, and a simple pooled analysis risks bias. We develop a robust CATE (conditional average treatment effect) estimation methodology with multisite data from heterogeneous populations. We propose a minimax-regret framework that learns a generalizable CATE model by minimizing the worst-case regret over a class of target populations whose CATE can be represented as convex combinations of site-specific CATEs. Using robust optimization, the proposed methodology accounts for distribution shifts in both individual covariates and treatment effect heterogeneity across sites. We show that the resulting CATE model has an interpretable closed-form solution, expressed as a weighted average of site-specific CATE models. Thus, researchers can utilize a flexible CATE estimation method within each site and aggregate site-specific estimates to produce the final model. Through simulations and a real-world application, we show that the proposed methodology improves the robustness and generalizability of existing approaches.
Causal Representation Learning with Generative Artificial Intelligence: Application to Texts as Treatments
Oct 01, 2024In this paper, we demonstrate how to enhance the validity of causal inference with unstructured high-dimensional treatments like texts, by leveraging the power of generative Artificial Intelligence. Specifically, we propose to use a deep generative model such as large language models (LLMs) to efficiently generate treatments and use their internal representation for subsequent causal effect estimation. We show that the knowledge of this true internal representation helps separate the treatment features of interest, such as specific sentiments and certain topics, from other possibly unknown confounding features. Unlike the existing methods, our proposed approach eliminates the need to learn causal representation from the data and hence produces more accurate and efficient estimates. We formally establish the conditions required for the nonparametric identification of the average treatment effect, propose an estimation strategy that avoids the violation of the overlap assumption, and derive the asymptotic properties of the proposed estimator through the application of double machine learning. Finally, using an instrumental variables approach, we extend the proposed methodology to the settings, in which the treatment feature is based on human perception rather than is assumed to be fixed given the treatment object. We conduct simulation studies using the generated text data with an open-source LLM, Llama3, to illustrate the advantages of our estimator over the state-of-the-art causal representation learning algorithms.
Neyman Meets Causal Machine Learning: Experimental Evaluation of Individualized Treatment Rules
Apr 25, 2024A century ago, Neyman showed how to evaluate the efficacy of treatment using a randomized experiment under a minimal set of assumptions. This classical repeated sampling framework serves as a basis of routine experimental analyses conducted by today's scientists across disciplines. In this paper, we demonstrate that Neyman's methodology can also be used to experimentally evaluate the efficacy of individualized treatment rules (ITRs), which are derived by modern causal machine learning algorithms. In particular, we show how to account for additional uncertainty resulting from a training process based on cross-fitting. The primary advantage of Neyman's approach is that it can be applied to any ITR regardless of the properties of machine learning algorithms that are used to derive the ITR. We also show, somewhat surprisingly, that for certain metrics, it is more efficient to conduct this ex-post experimental evaluation of an ITR than to conduct an ex-ante experimental evaluation that randomly assigns some units to the ITR. Our analysis demonstrates that Neyman's repeated sampling framework is as relevant for causal inference today as it has been since its inception.
Does AI help humans make better decisions? A methodological framework for experimental evaluation
Mar 18, 2024The use of Artificial Intelligence (AI) based on data-driven algorithms has become ubiquitous in today's society. Yet, in many cases and especially when stakes are high, humans still make final decisions. The critical question, therefore, is whether AI helps humans make better decisions as compared to a human alone or AI an alone. We introduce a new methodological framework that can be used to answer experimentally this question with no additional assumptions. We measure a decision maker's ability to make correct decisions using standard classification metrics based on the baseline potential outcome. We consider a single-blinded experimental design, in which the provision of AI-generated recommendations is randomized across cases with a human making final decisions. Under this experimental design, we show how to compare the performance of three alternative decision-making systems--human-alone, human-with-AI, and AI-alone. We apply the proposed methodology to the data from our own randomized controlled trial of a pretrial risk assessment instrument. We find that AI recommendations do not improve the classification accuracy of a judge's decision to impose cash bail. Our analysis also shows that AI-alone decisions generally perform worse than human decisions with or without AI assistance. Finally, AI recommendations tend to impose cash bail on non-white arrestees more often than necessary when compared to white arrestees.
The Cram Method for Efficient Simultaneous Learning and Evaluation
Mar 11, 2024We introduce the "cram" method, a general and efficient approach to simultaneous learning and evaluation using a generic machine learning (ML) algorithm. In a single pass of batched data, the proposed method repeatedly trains an ML algorithm and tests its empirical performance. Because it utilizes the entire sample for both learning and evaluation, cramming is significantly more data-efficient than sample-splitting. The cram method also naturally accommodates online learning algorithms, making its implementation computationally efficient. To demonstrate the power of the cram method, we consider the standard policy learning setting where cramming is applied to the same data to both develop an individualized treatment rule (ITR) and estimate the average outcome that would result if the learned ITR were to be deployed. We show that under a minimal set of assumptions, the resulting crammed evaluation estimator is consistent and asymptotically normal. While our asymptotic results require a relatively weak stabilization condition of ML algorithm, we develop a simple, generic method that can be used with any policy learning algorithm to satisfy this condition. Our extensive simulation studies show that, when compared to sample-splitting, cramming reduces the evaluation standard error by more than 40% while improving the performance of learned policy. We also apply the cram method to a randomized clinical trial to demonstrate its applicability to real-world problems. Finally, we briefly discuss future extensions of the cram method to other learning and evaluation settings.
Individualized Policy Evaluation and Learning under Clustered Network Interference
Nov 04, 2023


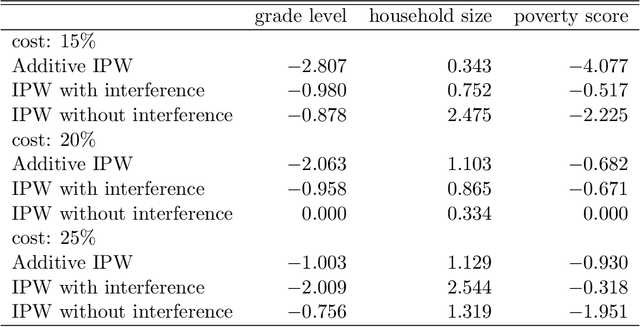
While there now exists a large literature on policy evaluation and learning, much of prior work assumes that the treatment assignment of one unit does not affect the outcome of another unit. Unfortunately, ignoring interference may lead to biased policy evaluation and yield ineffective learned policies. For example, treating influential individuals who have many friends can generate positive spillover effects, thereby improving the overall performance of an individualized treatment rule (ITR). We consider the problem of evaluating and learning an optimal ITR under clustered network (or partial) interference where clusters of units are sampled from a population and units may influence one another within each cluster. Under this model, we propose an estimator that can be used to evaluate the empirical performance of an ITR. We show that this estimator is substantially more efficient than the standard inverse probability weighting estimator, which does not impose any assumption about spillover effects. We derive the finite-sample regret bound for a learned ITR, showing that the use of our efficient evaluation estimator leads to the improved performance of learned policies. Finally, we conduct simulation and empirical studies to illustrate the advantages of the proposed methodology.
Statistical Performance Guarantee for Selecting Those Predicted to Benefit Most from Treatment
Oct 12, 2023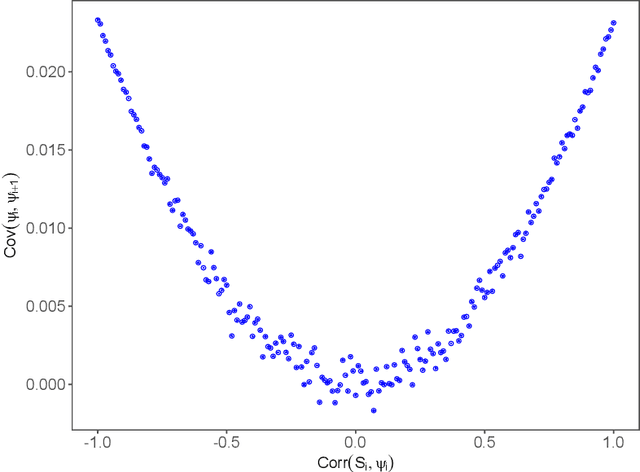



Across a wide array of disciplines, many researchers use machine learning (ML) algorithms to identify a subgroup of individuals, called exceptional responders, who are likely to be helped by a treatment the most. A common approach consists of two steps. One first estimates the conditional average treatment effect or its proxy using an ML algorithm. They then determine the cutoff of the resulting treatment prioritization score to select those predicted to benefit most from the treatment. Unfortunately, these estimated treatment prioritization scores are often biased and noisy. Furthermore, utilizing the same data to both choose a cutoff value and estimate the average treatment effect among the selected individuals suffer from a multiple testing problem. To address these challenges, we develop a uniform confidence band for experimentally evaluating the sorted average treatment effect (GATES) among the individuals whose treatment prioritization score is at least as high as any given quantile value, regardless of how the quantile is chosen. This provides a statistical guarantee that the GATES for the selected subgroup exceeds a certain threshold. The validity of the proposed methodology depends solely on randomization of treatment and random sampling of units without requiring modeling assumptions or resampling methods. This widens its applicability including a wide range of other causal quantities. A simulation study shows that the empirical coverage of the proposed uniform confidence bands is close to the nominal coverage when the sample is as small as 100. We analyze a clinical trial of late-stage prostate cancer and find a relatively large proportion of exceptional responders with a statistical performance guarantee.
Bayesian Safe Policy Learning with Chance Constrained Optimization: Application to Military Security Assessment during the Vietnam War
Jul 17, 2023Algorithmic and data-driven decisions and recommendations are commonly used in high-stakes decision-making settings such as criminal justice, medicine, and public policy. We investigate whether it would have been possible to improve a security assessment algorithm employed during the Vietnam War, using outcomes measured immediately after its introduction in late 1969. This empirical application raises several methodological challenges that frequently arise in high-stakes algorithmic decision-making. First, before implementing a new algorithm, it is essential to characterize and control the risk of yielding worse outcomes than the existing algorithm. Second, the existing algorithm is deterministic, and learning a new algorithm requires transparent extrapolation. Third, the existing algorithm involves discrete decision tables that are common but difficult to optimize over. To address these challenges, we introduce the Average Conditional Risk (ACRisk), which first quantifies the risk that a new algorithmic policy leads to worse outcomes for subgroups of individual units and then averages this over the distribution of subgroups. We also propose a Bayesian policy learning framework that maximizes the posterior expected value while controlling the posterior expected ACRisk. This framework separates the estimation of heterogeneous treatment effects from policy optimization, enabling flexible estimation of effects and optimization over complex policy classes. We characterize the resulting chance-constrained optimization problem as a constrained linear programming problem. Our analysis shows that compared to the actual algorithm used during the Vietnam War, the learned algorithm assesses most regions as more secure and emphasizes economic and political factors over military factors.