 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRAVAL -- WRiting Assist eVALuation
Dec 19, 2025The emergence of Large Language Models (LLMs) has shifted language model evaluation toward reasoning and problem-solving tasks as measures of general intelligence. Small Language Models (SLMs) -- defined here as models under 10B parameters -- typically score 3-4 times lower than LLMs on these metrics. However, we demonstrate that these evaluations fail to capture SLMs' effectiveness in common industrial applications, such as tone modification tasks (e.g., funny, serious, professional). We propose an evaluation framework specifically designed to highlight SLMs' capabilities in non-reasoning tasks where predefined evaluation datasets don't exist. Our framework combines novel approaches in data generation, prompt-tuning, and LLM-based evaluation to demonstrate the potential of task-specific finetuning. This work provides practitioners with tools to effectively benchmark both SLMs and LLMs for practical applications, particularly in edge and private computing scenarios. Our implementation is available at: https://github.com/amazon-science/wraval.
Using AI to Summarize US Presidential Campaign TV Advertisement Videos, 1952-2012
Mar 28, 2025This paper introduces the largest and most comprehensive dataset of US presidential campaign television advertisements, available in digital format. The dataset also includes machine-searchable transcripts and high-quality summaries designed to facilitate a variety of academic research. To date, there has been great interest in collecting and analyzing US presidential campaign advertisements, but the need for manual procurement and annotation led many to rely on smaller subsets. We design a large-scale parallelized, AI-based analysis pipeline that automates the laborious process of preparing, transcribing, and summarizing videos. We then apply this methodology to the 9,707 presidential ads from the Julian P. Kanter Political Commercial Archive. We conduct extensive human evaluations to show that these transcripts and summaries match the quality of manually generated alternatives. We illustrate the value of this data by including an application that tracks the genesis and evolution of current focal issue areas over seven decades of presidential elections. Our analysis pipeline and codebase also show how to use LLM-based tools to obtain high-quality summaries for other video datasets.
Creating a level playing field for all symbols in a discretization
Oct 18, 2012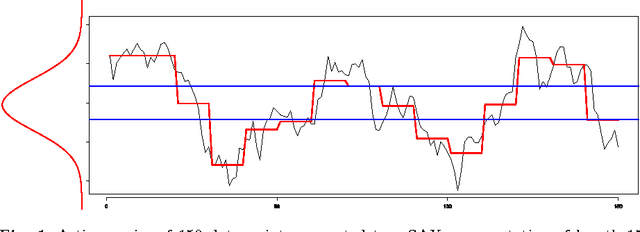
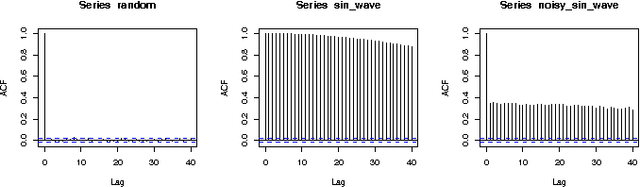

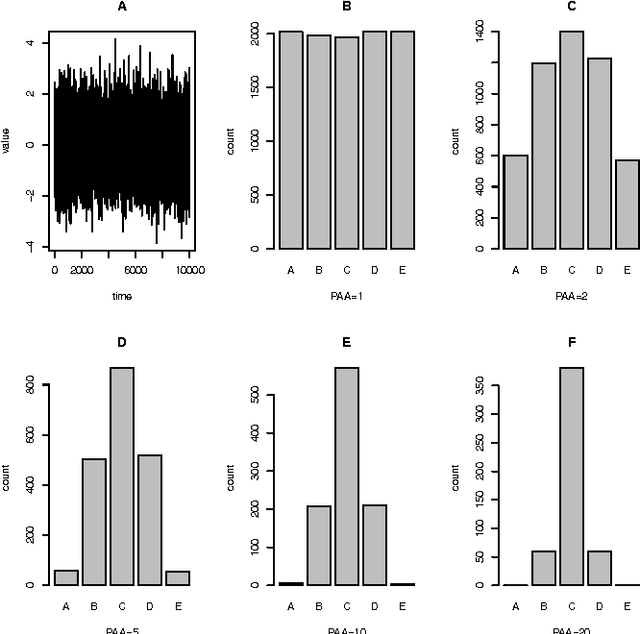
In time series analysis research there is a strong interest in discrete representations of real valued data streams. One approach that emerged over a decade ago and is still considered state-of-the-art is the Symbolic Aggregate Approximation algorithm. This discretization algorithm was the first symbolic approach that mapped a real-valued time series to a symbolic representation that was guaranteed to lower-bound Euclidean distance. The interest of this paper concerns the SAX assumption of data being highly Gaussian and the use of the standard normal curve to choose partitions to discretize the data. Though not necessarily, but generally, and certainly in its canonical form, the SAX approach chooses partitions on the standard normal curve that would produce an equal probability for each symbol in a finite alphabet to occur. This procedure is generally valid as a time series is normalized before the rest of the SAX algorithm is applied. However there exists a caveat to this assumption of equi-probability due to the intermediate step of Piecewise Aggregate Approximation (PAA). What we will show in this paper is that when PAA is applied the distribution of the data is indeed altered, resulting in a shrinking standard deviation that is proportional to the number of points used to create a segment of the PAA representation and the degree of auto-correlation within the series. Data that exhibits statistically significant auto-correlation is less affected by this shrinking distribution. As the standard deviation of the data contracts, the mean remains the same, however the distribution is no longer standard normal and therefore the partitions based on the standard normal curve are no longer valid for the assumption of equal probability.