 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebalance -- a Python package for balancing biased data samples
Jul 13, 2023Surveys are an important research tool, providing unique measurements on subjective experiences such as sentiment and opinions that cannot be measured by other means. However, because survey data is collected from a self-selected group of participants, directly inferring insights from it to a population of interest, or training ML models on such data, can lead to erroneous estimates or under-performing models. In this paper we present balance, an open-source Python package by Meta, offering a simple workflow for analyzing and adjusting biased data samples with respect to a population of interest. The balance workflow includes three steps: understanding the initial bias in the data relative to a target we would like to infer, adjusting the data to correct for the bias by producing weights for each unit in the sample based on propensity scores, and evaluating the final biases and the variance inflation after applying the fitted weights. The package provides a simple API that can be used by researchers and data scientists from a wide range of fields on a variety of data. The paper provides the relevant context, methodological background, and presents the package's API.
Friend or Faux: Graph-Based Early Detection of Fake Accounts on Social Networks
Apr 09, 2020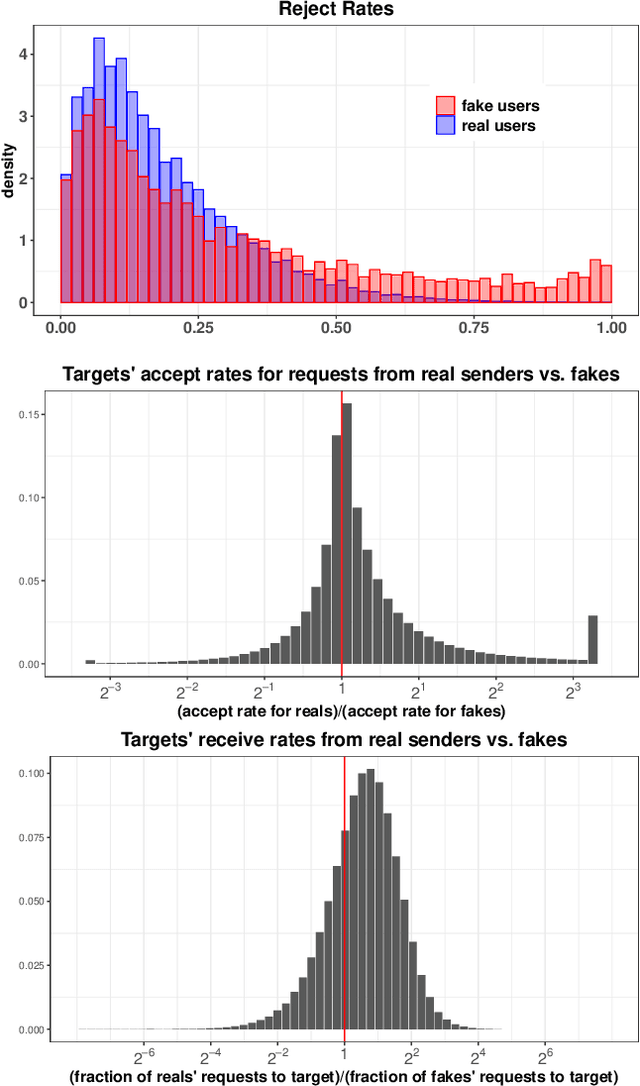

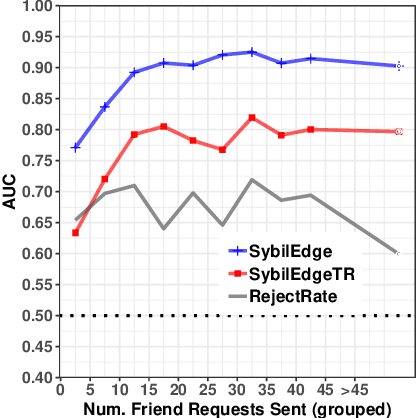
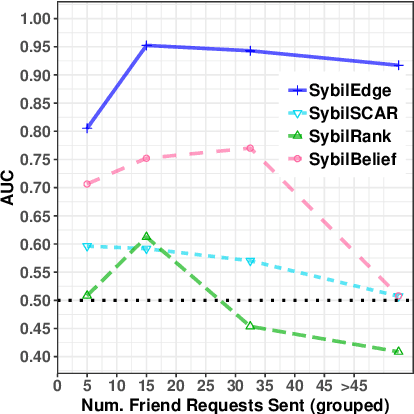
In this paper, we study the problem of early detection of fake user accounts on social networks based solely on their network connectivity with other users. Removing such accounts is a core task for maintaining the integrity of social networks, and early detection helps to reduce the harm that such accounts inflict. However, new fake accounts are notoriously difficult to detect via graph-based algorithms, as their small number of connections are unlikely to reflect a significant structural difference from those of new real accounts. We present the SybilEdge algorithm, which determines whether a new user is a fake account (`sybil') by aggregating over (I) her choices of friend request targets and (II) these targets' respective responses. SybilEdge performs this aggregation giving more weight to a user's choices of targets to the extent that these targets are preferred by other fakes versus real users, and also to the extent that these targets respond differently to fakes versus real users. We show that SybilEdge rapidly detects new fake users at scale on the Facebook network and outperforms state-of-the-art algorithms. We also show that SybilEdge is robust to label noise in the training data, to different prevalences of fake accounts in the network, and to several different ways fakes can select targets for their friend requests. To our knowledge, this is the first time a graph-based algorithm has been shown to achieve high performance (AUC>0.9) on new users who have only sent a small number of friend requests.