 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-to-Video Conversion for Overhead Object Detection
Feb 09, 2024
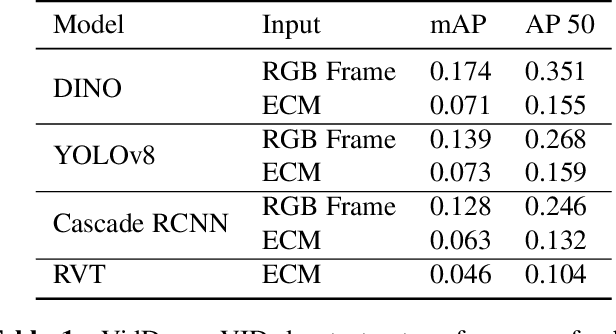
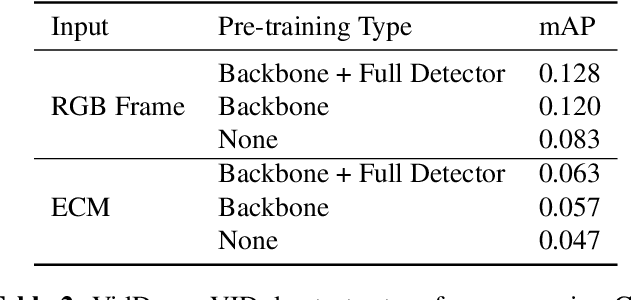
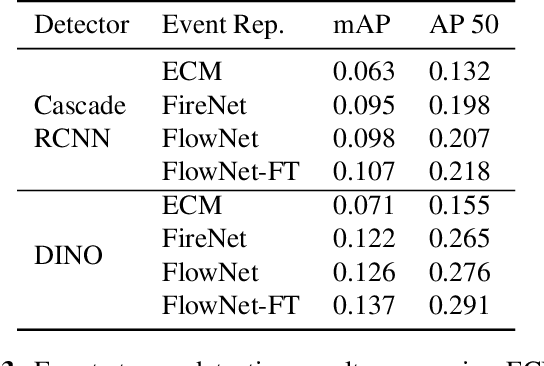
Collecting overhead imagery using an event camera is desirable due to the energy efficiency of the image sensor compared to standard cameras. However, event cameras complicate downstream image processing, especially for complex tasks such as object detection. In this paper, we investigate the viability of event streams for overhead object detection. We demonstrate that across a number of standard modeling approaches, there is a significant gap in performance between dense event representations and corresponding RGB frames. We establish that this gap is, in part, due to a lack of overlap between the event representations and the pre-training data used to initialize the weights of the object detectors. Then, we apply event-to-video conversion models that convert event streams into gray-scale video to close this gap. We demonstrate that this approach results in a large performance increase, outperforming even event-specific object detection techniques on our overhead target task. These results suggest that better alignment between event representations and existing large pre-trained models may result in greater short-term performance gains compared to end-to-end event-specific architectural improvements.
LCANets++: Robust Audio Classification using Multi-layer Neural Networks with Lateral Competition
Aug 23, 2023Audio classification aims at recognizing audio signals, including speech commands or sound events. However, current audio classifiers are susceptible to perturbations and adversarial attacks. In addition, real-world audio classification tasks often suffer from limited labeled data. To help bridge these gaps, previous work developed neuro-inspired convolutional neural networks (CNNs) with sparse coding via the Locally Competitive Algorithm (LCA) in the first layer (i.e., LCANets) for computer vision. LCANets learn in a combination of supervised and unsupervised learning, reducing dependency on labeled samples. Motivated by the fact that auditory cortex is also sparse, we extend LCANets to audio recognition tasks and introduce LCANets++, which are CNNs that perform sparse coding in multiple layers via LCA. We demonstrate that LCANets++ are more robust than standard CNNs and LCANets against perturbations, e.g., background noise, as well as black-box and white-box attacks, e.g., evasion and fast gradient sign (FGSM) attacks.
Implementing and Benchmarking the Locally Competitive Algorithm on the Loihi 2 Neuromorphic Processor
Jul 25, 2023Neuromorphic processors have garnered considerable interest in recent years for their potential in energy-efficient and high-speed computing. The Locally Competitive Algorithm (LCA) has been utilized for power efficient sparse coding on neuromorphic processors, including the first Loihi processor. With the Loihi 2 processor enabling custom neuron models and graded spike communication, more complex implementations of LCA are possible. We present a new implementation of LCA designed for the Loihi 2 processor and perform an initial set of benchmarks comparing it to LCA on CPU and GPU devices. In these experiments LCA on Loihi 2 is orders of magnitude more efficient and faster for large sparsity penalties, while maintaining similar reconstruction quality. We find this performance improvement increases as the LCA parameters are tuned towards greater representation sparsity. Our study highlights the potential of neuromorphic processors, particularly Loihi 2, in enabling intelligent, autonomous, real-time processing on small robots, satellites where there are strict SWaP (small, lightweight, and low power) requirements. By demonstrating the superior performance of LCA on Loihi 2 compared to conventional computing device, our study suggests that Loihi 2 could be a valuable tool in advancing these types of applications. Overall, our study highlights the potential of neuromorphic processors for efficient and accurate data processing on resource-constrained devices.
Sampling binary sparse coding QUBO models using a spiking neuromorphic processor
Jun 02, 2023

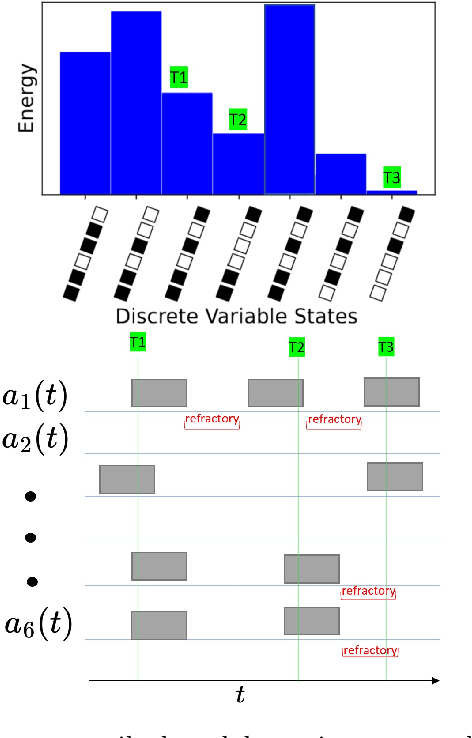

We consider the problem of computing a sparse binary representation of an image. To be precise, given an image and an overcomplete, non-orthonormal basis, we aim to find a sparse binary vector indicating the minimal set of basis vectors that when added together best reconstruct the given input. We formulate this problem with an $L_2$ loss on the reconstruction error, and an $L_0$ (or, equivalently, an $L_1$) loss on the binary vector enforcing sparsity. This yields a so-called Quadratic Unconstrained Binary Optimization (QUBO) problem, whose solution is generally NP-hard to find. The contribution of this work is twofold. First, the method of unsupervised and unnormalized dictionary feature learning for a desired sparsity level to best match the data is presented. Second, the binary sparse coding problem is then solved on the Loihi 1 neuromorphic chip by the use of stochastic networks of neurons to traverse the non-convex energy landscape. The solutions are benchmarked against the classical heuristic simulated annealing. We demonstrate neuromorphic computing is suitable for sampling low energy solutions of binary sparse coding QUBO models, and although Loihi 1 is capable of sampling very sparse solutions of the QUBO models, there needs to be improvement in the implementation in order to be competitive with simulated annealing.
Dictionary Learning with Accumulator Neurons
May 30, 2022
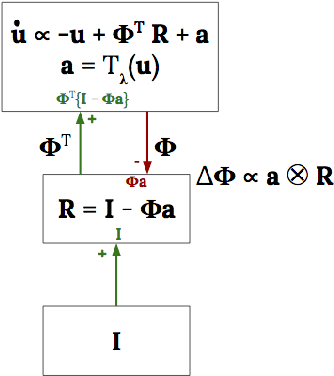
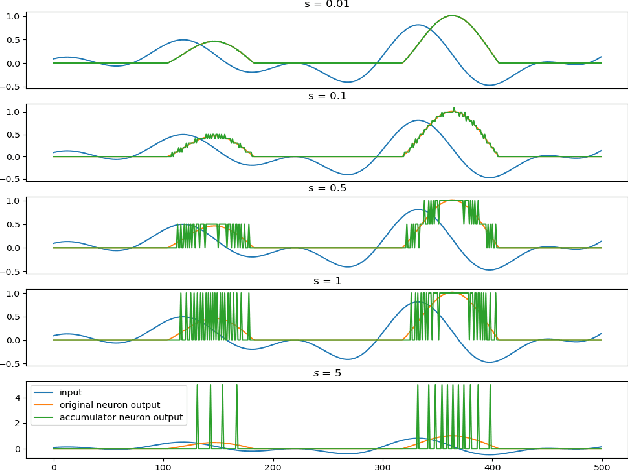

The Locally Competitive Algorithm (LCA) uses local competition between non-spiking leaky integrator neurons to infer sparse representations, allowing for potentially real-time execution on massively parallel neuromorphic architectures such as Intel's Loihi processor. Here, we focus on the problem of inferring sparse representations from streaming video using dictionaries of spatiotemporal features optimized in an unsupervised manner for sparse reconstruction. Non-spiking LCA has previously been used to achieve unsupervised learning of spatiotemporal dictionaries composed of convolutional kernels from raw, unlabeled video. We demonstrate how unsupervised dictionary learning with spiking LCA (\hbox{S-LCA}) can be efficiently implemented using accumulator neurons, which combine a conventional leaky-integrate-and-fire (\hbox{LIF}) spike generator with an additional state variable that is used to minimize the difference between the integrated input and the spiking output. We demonstrate dictionary learning across a wide range of dynamical regimes, from graded to intermittent spiking, for inferring sparse representations of both static images drawn from the CIFAR database as well as video frames captured from a DVS camera. On a classification task that requires identification of the suite from a deck of cards being rapidly flipped through as viewed by a DVS camera, we find essentially no degradation in performance as the LCA model used to infer sparse spatiotemporal representations migrates from graded to spiking. We conclude that accumulator neurons are likely to provide a powerful enabling component of future neuromorphic hardware for implementing online unsupervised learning of spatiotemporal dictionaries optimized for sparse reconstruction of streaming video from event based DVS cameras.
Prediction and compression of lattice QCD data using machine learning algorithms on quantum annealer
Dec 03, 2021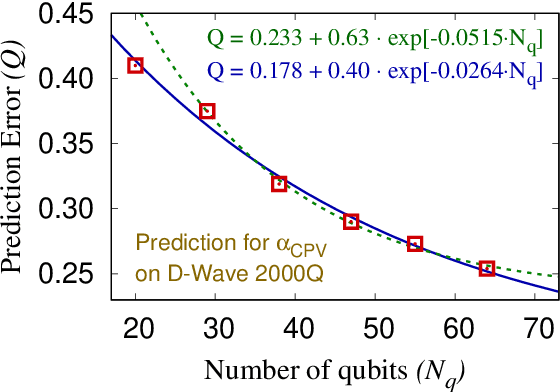
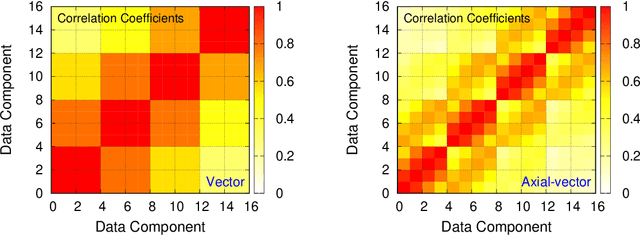
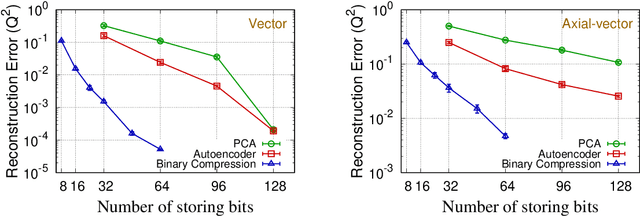
We present regression and compression algorithms for lattice QCD data utilizing the efficient binary optimization ability of quantum annealers. In the regression algorithm, we encode the correlation between the input and output variables into a sparse coding machine learning algorithm. The trained correlation pattern is used to predict lattice QCD observables of unseen lattice configurations from other observables measured on the lattice. In the compression algorithm, we define a mapping from lattice QCD data of floating-point numbers to the binary coefficients that closely reconstruct the input data from a set of basis vectors. Since the reconstruction is not exact, the mapping defines a lossy compression, but, a reasonably small number of binary coefficients are able to reconstruct the input vector of lattice QCD data with the reconstruction error much smaller than the statistical fluctuation. In both applications, we use D-Wave quantum annealers to solve the NP-hard binary optimization problems of the machine learning algorithms.
* 9 pages, 3 figures, Proceedings of the 38th International Symposium on Lattice Field Theory, LATTICE2021
A Little Robustness Goes a Long Way: Leveraging Universal Features for Targeted Transfer Attacks
Jun 03, 2021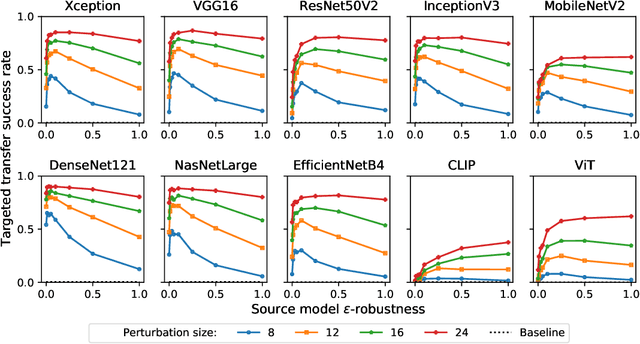
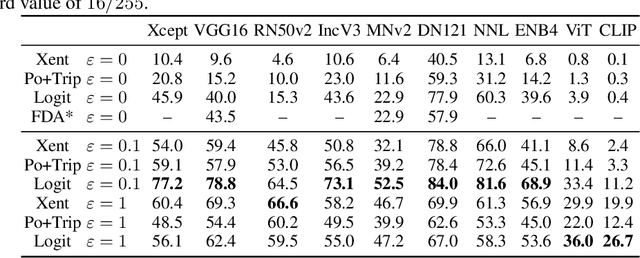
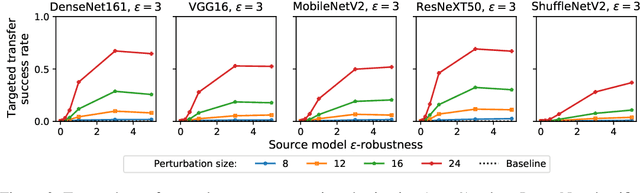
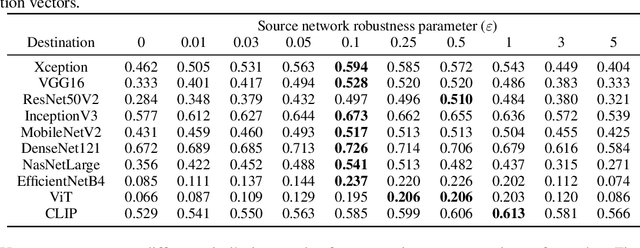
Adversarial examples for neural network image classifiers are known to be transferable: examples optimized to be misclassified by a source classifier are often misclassified as well by classifiers with different architectures. However, targeted adversarial examples -- optimized to be classified as a chosen target class -- tend to be less transferable between architectures. While prior research on constructing transferable targeted attacks has focused on improving the optimization procedure, in this work we examine the role of the source classifier. Here, we show that training the source classifier to be "slightly robust" -- that is, robust to small-magnitude adversarial examples -- substantially improves the transferability of targeted attacks, even between architectures as different as convolutional neural networks and transformers. We argue that this result supports a non-intuitive hypothesis: on the spectrum from non-robust (standard) to highly robust classifiers, those that are only slightly robust exhibit the most universal features -- ones that tend to overlap with the features learned by other classifiers trained on the same dataset. The results we present provide insight into the nature of adversarial examples as well as the mechanisms underlying so-called "robust" classifiers.
Adversarial Perturbations Are Not So Weird: Entanglement of Robust and Non-Robust Features in Neural Network Classifiers
Feb 09, 2021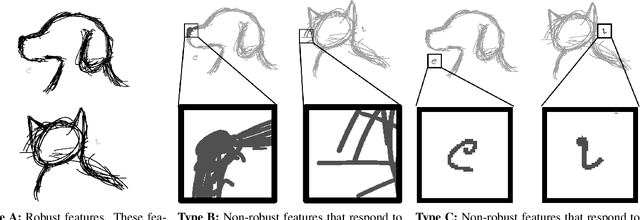
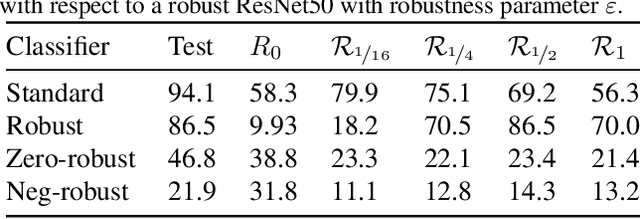

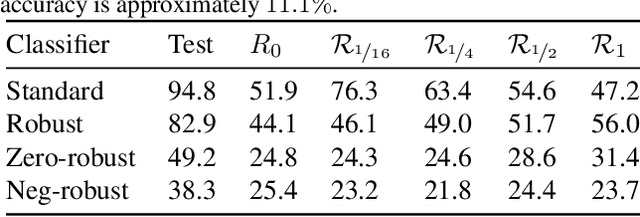
Neural networks trained on visual data are well-known to be vulnerable to often imperceptible adversarial perturbations. The reasons for this vulnerability are still being debated in the literature. Recently Ilyas et al. (2019) showed that this vulnerability arises, in part, because neural network classifiers rely on highly predictive but brittle "non-robust" features. In this paper we extend the work of Ilyas et al. by investigating the nature of the input patterns that give rise to these features. In particular, we hypothesize that in a neural network trained in a standard way, non-robust features respond to small, "non-semantic" patterns that are typically entangled with larger, robust patterns, known to be more human-interpretable, as opposed to solely responding to statistical artifacts in a dataset. Thus, adversarial examples can be formed via minimal perturbations to these small, entangled patterns. In addition, we demonstrate a corollary of our hypothesis: robust classifiers are more effective than standard (non-robust) ones as a source for generating transferable adversarial examples in both the untargeted and targeted settings. The results we present in this paper provide new insight into the nature of the non-robust features responsible for adversarial vulnerability of neural network classifiers.
The Selectivity and Competition of the Mind's Eye in Visual Perception
Nov 23, 2020
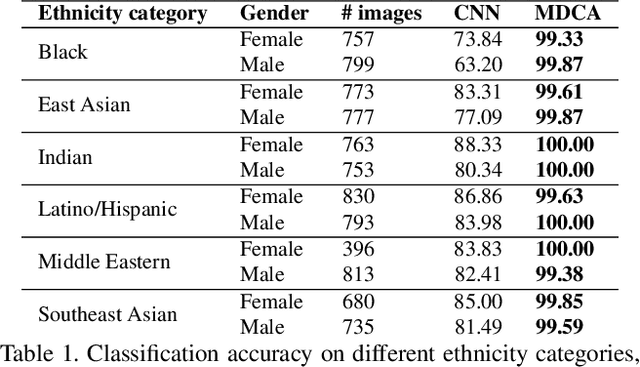
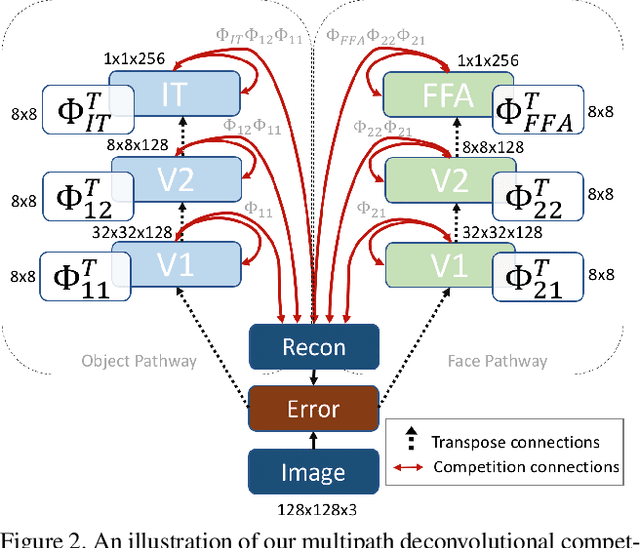

Research has shown that neurons within the brain are selective to certain stimuli. For example, the fusiform face area (FFA) region is known by neuroscientists to selectively activate when people see faces over non-face objects. However, the mechanisms by which the primary visual system directs information to the correct higher levels of the brain are currently unknown. In our work, we advance the understanding of the neural mechanisms of perception by creating a novel computational model that incorporates lateral and top down feedback in the form of hierarchical competition. We show that these elements can help explain the information flow and selectivity of high level areas within the brain. Additionally, we present both quantitative and qualitative results that demonstrate consistency with general themes and specific responses observed in the visual system. Finally, we show that our generative framework enables a wide range of applications in computer vision, including overcoming issues of bias that have been discovered in standard deep learning models.
It's Hard for Neural Networks To Learn the Game of Life
Sep 03, 2020
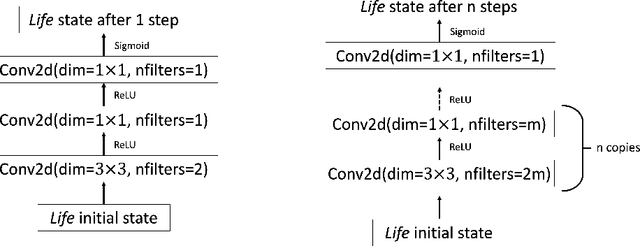
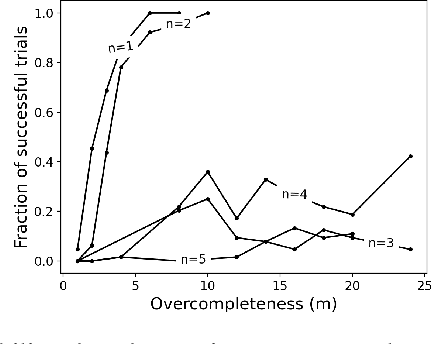
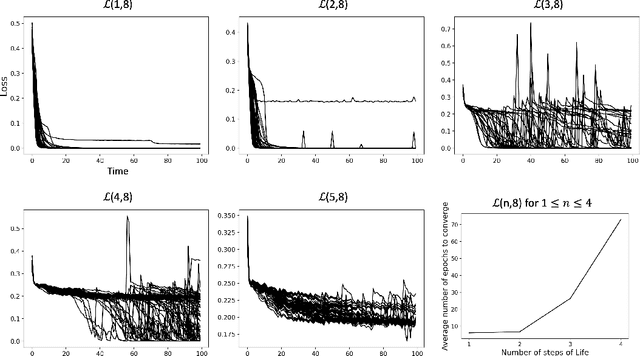
Efforts to improve the learning abilities of neural networks have focused mostly on the role of optimization methods rather than on weight initializations. Recent findings, however, suggest that neural networks rely on lucky random initial weights of subnetworks called "lottery tickets" that converge quickly to a solution. To investigate how weight initializations affect performance, we examine small convolutional networks that are trained to predict n steps of the two-dimensional cellular automaton Conway's Game of Life, the update rules of which can be implemented efficiently in a 2n+1 layer convolutional network. We find that networks of this architecture trained on this task rarely converge. Rather, networks require substantially more parameters to consistently converge. In addition, near-minimal architectures are sensitive to tiny changes in parameters: changing the sign of a single weight can cause the network to fail to learn. Finally, we observe a critical value d_0 such that training minimal networks with examples in which cells are alive with probability d_0 dramatically increases the chance of convergence to a solution. We conclude that training convolutional neural networks to learn the input/output function represented by n steps of Game of Life exhibits many characteristics predicted by the lottery ticket hypothesis, namely, that the size of the networks required to learn this function are often significantly larger than the minimal network required to implement the function.