 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Perturbations Are Not So Weird: Entanglement of Robust and Non-Robust Features in Neural Network Classifiers
Paper and Code
Feb 09, 2021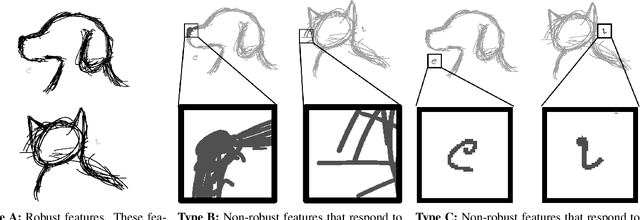
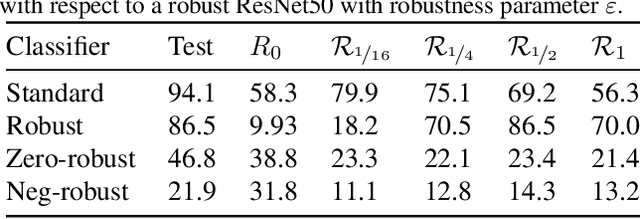

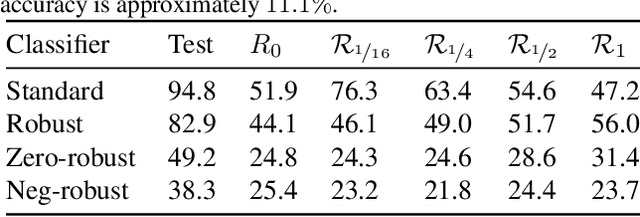
Neural networks trained on visual data are well-known to be vulnerable to often imperceptible adversarial perturbations. The reasons for this vulnerability are still being debated in the literature. Recently Ilyas et al. (2019) showed that this vulnerability arises, in part, because neural network classifiers rely on highly predictive but brittle "non-robust" features. In this paper we extend the work of Ilyas et al. by investigating the nature of the input patterns that give rise to these features. In particular, we hypothesize that in a neural network trained in a standard way, non-robust features respond to small, "non-semantic" patterns that are typically entangled with larger, robust patterns, known to be more human-interpretable, as opposed to solely responding to statistical artifacts in a dataset. Thus, adversarial examples can be formed via minimal perturbations to these small, entangled patterns. In addition, we demonstrate a corollary of our hypothesis: robust classifiers are more effective than standard (non-robust) ones as a source for generating transferable adversarial examples in both the untargeted and targeted settings. The results we present in this paper provide new insight into the nature of the non-robust features responsible for adversarial vulnerability of neural network classifiers.