 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Robustness Goes a Long Way: Leveraging Universal Features for Targeted Transfer Attacks
Jun 03, 2021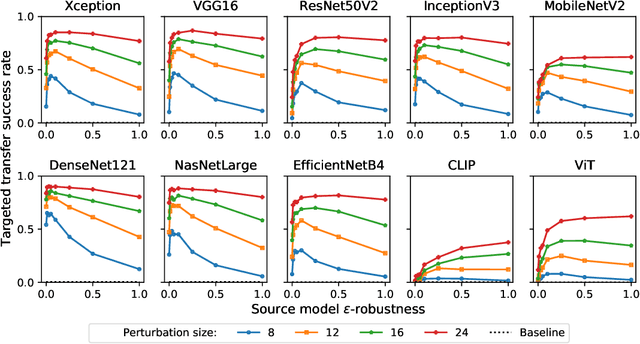
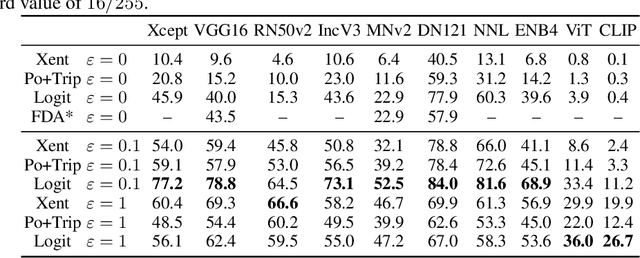
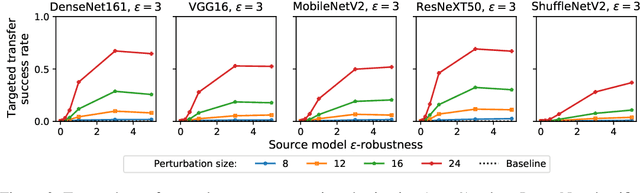
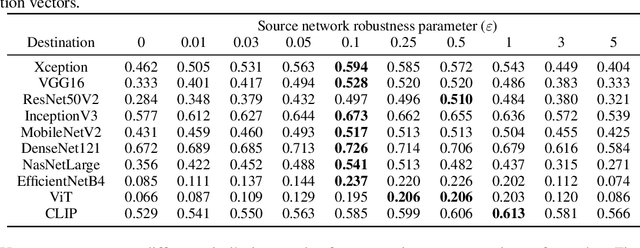
Adversarial examples for neural network image classifiers are known to be transferable: examples optimized to be misclassified by a source classifier are often misclassified as well by classifiers with different architectures. However, targeted adversarial examples -- optimized to be classified as a chosen target class -- tend to be less transferable between architectures. While prior research on constructing transferable targeted attacks has focused on improving the optimization procedure, in this work we examine the role of the source classifier. Here, we show that training the source classifier to be "slightly robust" -- that is, robust to small-magnitude adversarial examples -- substantially improves the transferability of targeted attacks, even between architectures as different as convolutional neural networks and transformers. We argue that this result supports a non-intuitive hypothesis: on the spectrum from non-robust (standard) to highly robust classifiers, those that are only slightly robust exhibit the most universal features -- ones that tend to overlap with the features learned by other classifiers trained on the same dataset. The results we present provide insight into the nature of adversarial examples as well as the mechanisms underlying so-called "robust" classifiers.
Adversarial Perturbations Are Not So Weird: Entanglement of Robust and Non-Robust Features in Neural Network Classifiers
Feb 09, 2021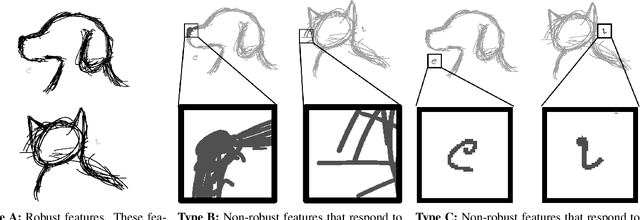
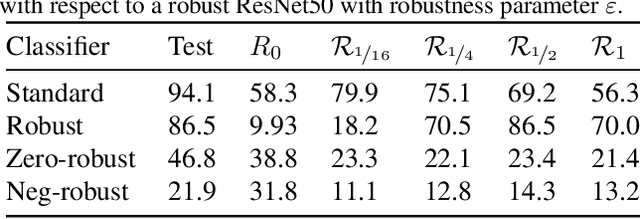

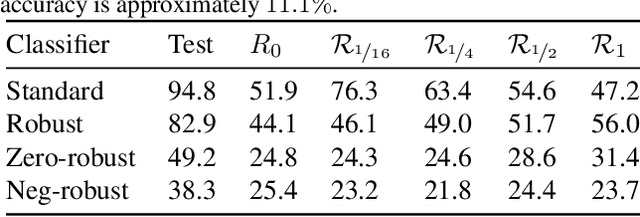
Neural networks trained on visual data are well-known to be vulnerable to often imperceptible adversarial perturbations. The reasons for this vulnerability are still being debated in the literature. Recently Ilyas et al. (2019) showed that this vulnerability arises, in part, because neural network classifiers rely on highly predictive but brittle "non-robust" features. In this paper we extend the work of Ilyas et al. by investigating the nature of the input patterns that give rise to these features. In particular, we hypothesize that in a neural network trained in a standard way, non-robust features respond to small, "non-semantic" patterns that are typically entangled with larger, robust patterns, known to be more human-interpretable, as opposed to solely responding to statistical artifacts in a dataset. Thus, adversarial examples can be formed via minimal perturbations to these small, entangled patterns. In addition, we demonstrate a corollary of our hypothesis: robust classifiers are more effective than standard (non-robust) ones as a source for generating transferable adversarial examples in both the untargeted and targeted settings. The results we present in this paper provide new insight into the nature of the non-robust features responsible for adversarial vulnerability of neural network classifiers.
STRATA: Building Robustness with a Simple Method for Generating Black-box Adversarial Attacks for Models of Code
Sep 28, 2020



Adversarial examples are imperceptible perturbations in the input to a neural model that result in misclassification. Generating adversarial examples for source code poses an additional challenge compared to the domains of images and natural language, because source code perturbations must adhere to strict semantic guidelines so the resulting programs retain the functional meaning of the code. We propose a simple and efficient black-box method for generating state-of-the-art adversarial examples on models of code. Our method generates untargeted and targeted attacks, and empirically outperforms competing gradient-based methods with less information and less computational effort. We also use adversarial training to construct a model robust to these attacks; our attack reduces the F1 score of code2seq by 42%. Adversarial training brings the F1 score on adversarial examples up to 99% of baseline.
It's Hard for Neural Networks To Learn the Game of Life
Sep 03, 2020
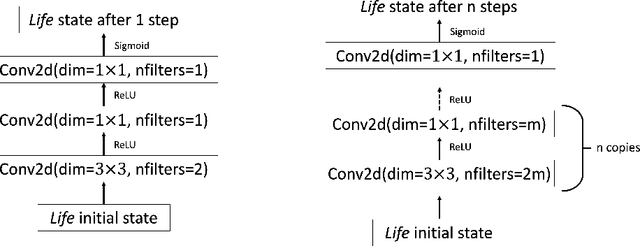
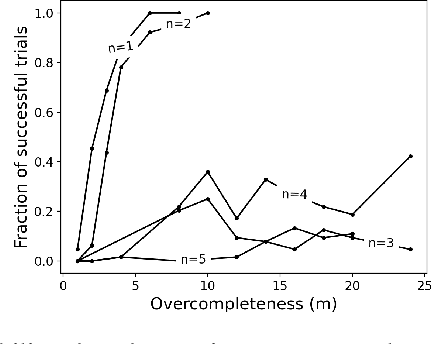
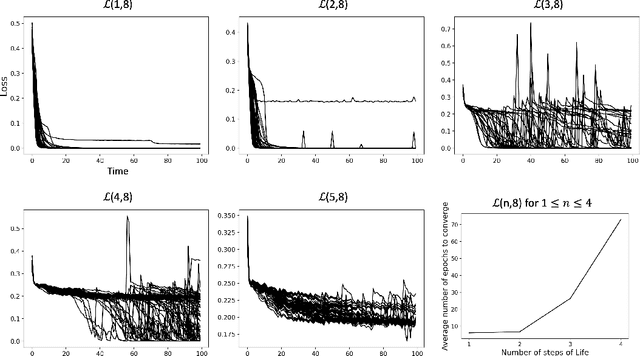
Efforts to improve the learning abilities of neural networks have focused mostly on the role of optimization methods rather than on weight initializations. Recent findings, however, suggest that neural networks rely on lucky random initial weights of subnetworks called "lottery tickets" that converge quickly to a solution. To investigate how weight initializations affect performance, we examine small convolutional networks that are trained to predict n steps of the two-dimensional cellular automaton Conway's Game of Life, the update rules of which can be implemented efficiently in a 2n+1 layer convolutional network. We find that networks of this architecture trained on this task rarely converge. Rather, networks require substantially more parameters to consistently converge. In addition, near-minimal architectures are sensitive to tiny changes in parameters: changing the sign of a single weight can cause the network to fail to learn. Finally, we observe a critical value d_0 such that training minimal networks with examples in which cells are alive with probability d_0 dramatically increases the chance of convergence to a solution. We conclude that training convolutional neural networks to learn the input/output function represented by n steps of Game of Life exhibits many characteristics predicted by the lottery ticket hypothesis, namely, that the size of the networks required to learn this function are often significantly larger than the minimal network required to implement the function.
Classifiers Based on Deep Sparse Coding Architectures are Robust to Deep Learning Transferable Examples
Nov 20, 2018



Although deep learning has shown great success in recent years, researchers have discovered a critical flaw where small, imperceptible changes in the input to the system can drastically change the output classification. These attacks are exploitable in nearly all of the existing deep learning classification frameworks. However, the susceptibility of deep sparse coding models to adversarial examples has not been examined. Here, we show that classifiers based on a deep sparse coding model whose classification accuracy is competitive with a variety of deep neural network models are robust to adversarial examples that effectively fool those same deep learning models. We demonstrate both quantitatively and qualitatively that the robustness of deep sparse coding models to adversarial examples arises from two key properties. First, because deep sparse coding models learn general features corresponding to generators of the dataset as a whole, rather than highly discriminative features for distinguishing specific classes, the resulting classifiers are less dependent on idiosyncratic features that might be more easily exploited. Second, because deep sparse coding models utilize fixed point attractor dynamics with top-down feedback, it is more difficult to find small changes to the input that drive the resulting representations out of the correct attractor basin.