 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Challenges and Opportunities of Few-Shot Learning Across Multiple Domains
Apr 05, 2025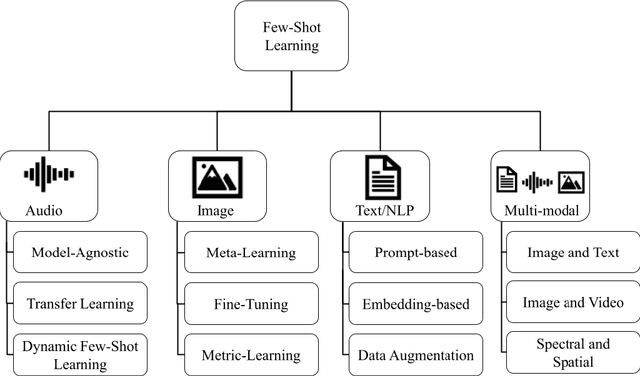

In a world where new domains are constantly discovered and machine learning (ML) is applied to automate new tasks every day, challenges arise with the number of samples available to train ML models. While the traditional ML training relies heavily on data volume, finding a large dataset with a lot of usable samples is not always easy, and often the process takes time. For instance, when a new human transmissible disease such as COVID-19 breaks out and there is an immediate surge for rapid diagnosis, followed by rapid isolation of infected individuals from healthy ones to contain the spread, there is an immediate need to create tools/automation using machine learning models. At the early stage of an outbreak, it is not only difficult to obtain a lot of samples, but also difficult to understand the details about the disease, to process the data needed to train a traditional ML model. A solution for this can be a few-shot learning approach. This paper presents challenges and opportunities of few-shot approaches that vary across major domains, i.e., audio, image, text, and their combinations, with their strengths and weaknesses. This detailed understanding can help to adopt appropriate approaches applicable to different domains and applications.