 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientEQA: An Efficient Approach for Open Vocabulary Embodied Question Answering
Paper and Code
Oct 26, 2024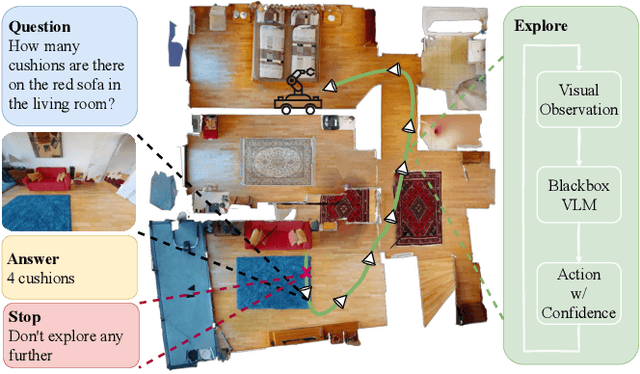
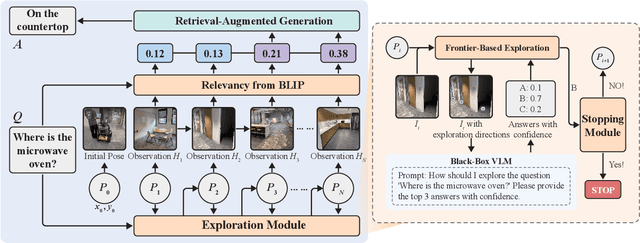
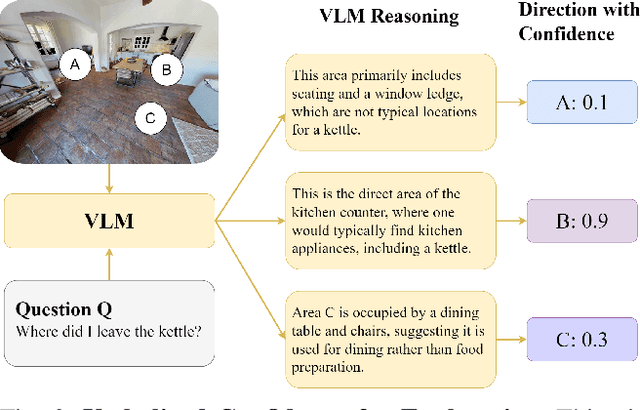
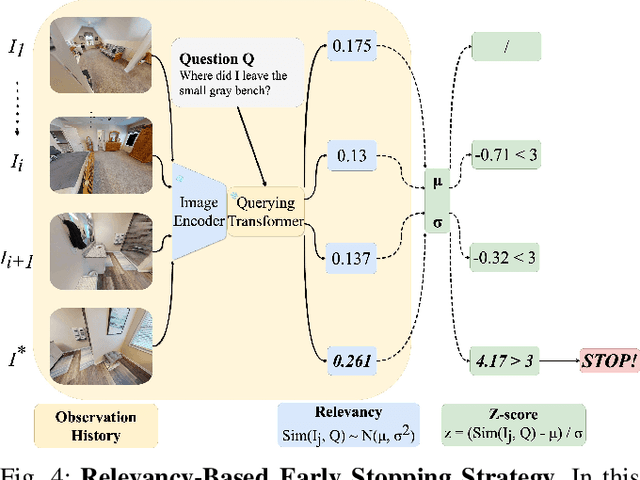
Embodied Question Answering (EQA) is an essential yet challenging task for robotic home assistants. Recent studies have shown that large vision-language models (VLMs) can be effectively utilized for EQA, but existing works either focus on video-based question answering without embodied exploration or rely on closed-form choice sets. In real-world scenarios, a robotic agent must efficiently explore and accurately answer questions in open-vocabulary settings. To address these challenges, we propose a novel framework called EfficientEQA for open-vocabulary EQA, which enables efficient exploration and accurate answering. In EfficientEQA, the robot actively explores unknown environments using Semantic-Value-Weighted Frontier Exploration, a strategy that prioritizes exploration based on semantic importance provided by calibrated confidence from black-box VLMs to quickly gather relevant information. To generate accurate answers, we employ Retrieval-Augmented Generation (RAG), which utilizes BLIP to retrieve useful images from accumulated observations and VLM reasoning to produce responses without relying on predefined answer choices. Additionally, we detect observations that are highly relevant to the question as outliers, allowing the robot to determine when it has sufficient information to stop exploring and provide an answer. Experimental results demonstrate the effectiveness of our approach, showing an improvement in answering accuracy by over 15% and efficiency, measured in running steps, by over 20% compared to state-of-the-art methods.