 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCVR Scene Generation: High Compatibility Virtual Reality Environment Generation for Extended Redirected Walking
Jan 21, 2026Natural walking enhances immersion in virtual environments (VEs), but physical space limitations and obstacles hinder exploration, especially in large virtual scenes. Redirected Walking (RDW) techniques mitigate this by subtly manipulating the virtual camera to guide users away from physical collisions within pre-defined VEs. However, RDW efficacy diminishes significantly when substantial geometric divergence exists between the physical and virtual environments, leading to unavoidable collisions. Existing scene generation methods primarily focus on object relationships or layout aesthetics, often neglecting the crucial aspect of physical compatibility required for effective RDW. To address this, we introduce HCVR (High Compatibility Virtual Reality Environment Generation), a novel framework that generates virtual scenes inherently optimized for alignment-based RDW controllers. HCVR first employs ENI++, a novel, boundary-sensitive metric to evaluate the incompatibility between physical and virtual spaces by comparing rotation-sensitive visibility polygons. Guided by the ENI++ compatibility map and user prompts, HCVR utilizes a Large Language Model (LLM) for context-aware 3D asset retrieval and initial layout generation. The framework then strategically adjusts object selection, scaling, and placement to maximize coverage of virtually incompatible regions, effectively guiding users towards RDW-feasible paths. User studies evaluating physical collisions and layout quality demonstrate HCVR's effectiveness with HCVR-generated scenes, resulting in 22.78 times fewer physical collisions and received 35.89\% less on ENI++ score compared to LLM-based generation with RDW, while also receiving 12.5\% higher scores on user feedback to layout design.
Handle-based Mesh Deformation Guided By Vision Language Model
Jun 05, 2025Mesh deformation is a fundamental tool in 3D content manipulation. Despite extensive prior research, existing approaches often suffer from low output quality, require significant manual tuning, or depend on data-intensive training. To address these limitations, we introduce a training-free, handle-based mesh deformation method. % Our core idea is to leverage a Vision-Language Model (VLM) to interpret and manipulate a handle-based interface through prompt engineering. We begin by applying cone singularity detection to identify a sparse set of potential handles. The VLM is then prompted to select both the deformable sub-parts of the mesh and the handles that best align with user instructions. Subsequently, we query the desired deformed positions of the selected handles in screen space. To reduce uncertainty inherent in VLM predictions, we aggregate the results from multiple camera views using a novel multi-view voting scheme. % Across a suite of benchmarks, our method produces deformations that align more closely with user intent, as measured by CLIP and GPTEval3D scores, while introducing low distortion -- quantified via membrane energy. In summary, our approach is training-free, highly automated, and consistently delivers high-quality mesh deformations.
EfficientEQA: An Efficient Approach for Open Vocabulary Embodied Question Answering
Oct 26, 2024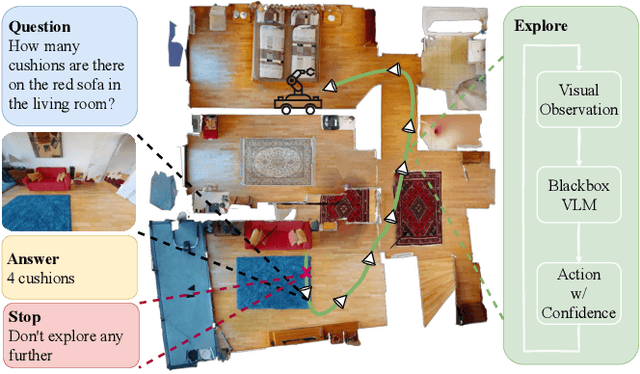
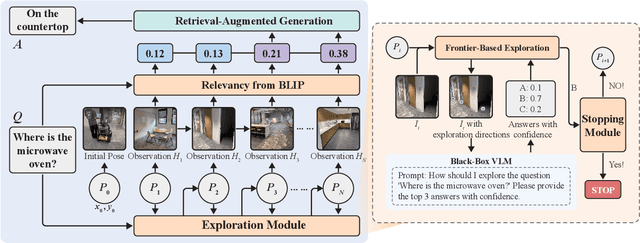
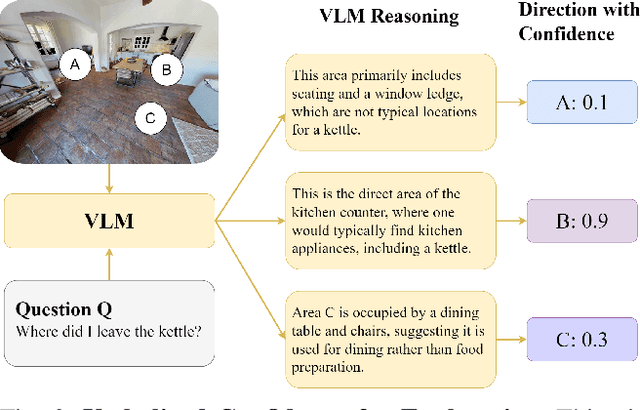
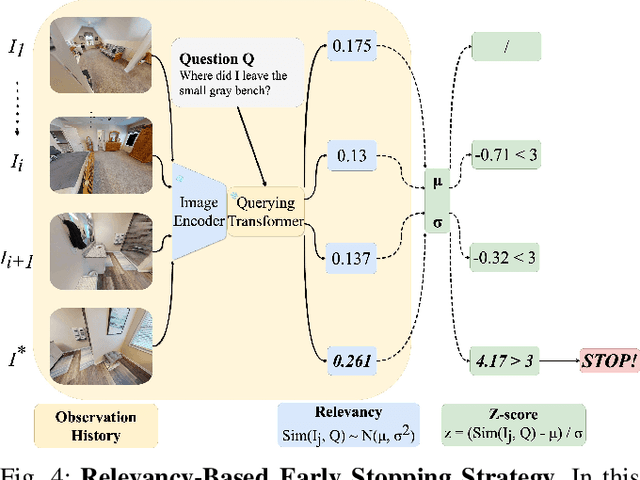
Embodied Question Answering (EQA) is an essential yet challenging task for robotic home assistants. Recent studies have shown that large vision-language models (VLMs) can be effectively utilized for EQA, but existing works either focus on video-based question answering without embodied exploration or rely on closed-form choice sets. In real-world scenarios, a robotic agent must efficiently explore and accurately answer questions in open-vocabulary settings. To address these challenges, we propose a novel framework called EfficientEQA for open-vocabulary EQA, which enables efficient exploration and accurate answering. In EfficientEQA, the robot actively explores unknown environments using Semantic-Value-Weighted Frontier Exploration, a strategy that prioritizes exploration based on semantic importance provided by calibrated confidence from black-box VLMs to quickly gather relevant information. To generate accurate answers, we employ Retrieval-Augmented Generation (RAG), which utilizes BLIP to retrieve useful images from accumulated observations and VLM reasoning to produce responses without relying on predefined answer choices. Additionally, we detect observations that are highly relevant to the question as outliers, allowing the robot to determine when it has sufficient information to stop exploring and provide an answer. Experimental results demonstrate the effectiveness of our approach, showing an improvement in answering accuracy by over 15% and efficiency, measured in running steps, by over 20% compared to state-of-the-art methods.
TrustNavGPT: Modeling Uncertainty to Improve Trustworthiness of Audio-Guided LLM-Based Robot Navigation
Aug 03, 2024



While LLMs are proficient at processing text in human conversations, they often encounter difficulties with the nuances of verbal instructions and, thus, remain prone to hallucinate trust in human command. In this work, we present TrustNavGPT, an LLM based audio guided navigation agent that uses affective cues in spoken communication elements such as tone and inflection that convey meaning beyond words, allowing it to assess the trustworthiness of human commands and make effective, safe decisions. Our approach provides a lightweight yet effective approach that extends existing LLMs to model audio vocal features embedded in the voice command and model uncertainty for safe robotic navigation.
Beyond Text: Improving LLM's Decision Making for Robot Navigation via Vocal Cues
Feb 05, 2024



This work highlights a critical shortcoming in text-based Large Language Models (LLMs) used for human-robot interaction, demonstrating that text alone as a conversation modality falls short in such applications. While LLMs excel in processing text in these human conversations, they struggle with the nuances of verbal instructions in scenarios like social navigation, where ambiguity and uncertainty can erode trust in robotic and other AI systems. We can address this shortcoming by moving beyond text and additionally focusing on the paralinguistic features of these audio responses. These features are the aspects of spoken communication that do not involve the literal wording (lexical content) but convey meaning and nuance through how something is said. We present "Beyond Text"; an approach that improves LLM decision-making by integrating audio transcription along with a subsection of these features, which focus on the affect and more relevant in human-robot conversations. This approach not only achieves a 70.26% winning rate, outperforming existing LLMs by 48.30%, but also enhances robustness against token manipulation adversarial attacks, highlighted by a 22.44% less decrease ratio than the text-only language model in winning rate. "Beyond Text" marks an advancement in social robot navigation and broader Human-Robot interactions, seamlessly integrating text-based guidance with human-audio-informed language models.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.