 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multitask Learning Using Gradient-based Estimation of Task Affinity
Paper and Code
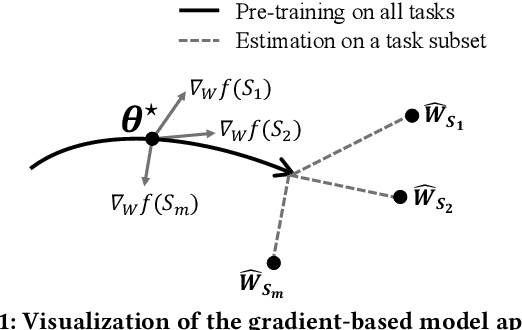
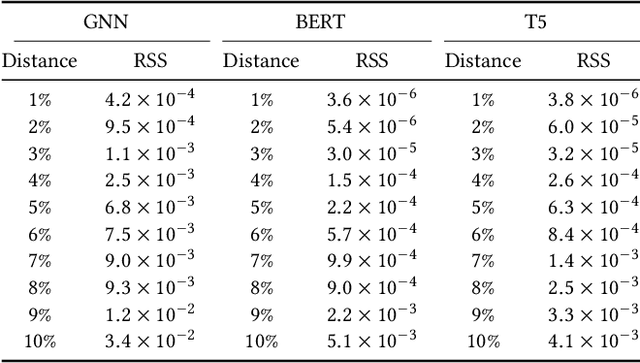

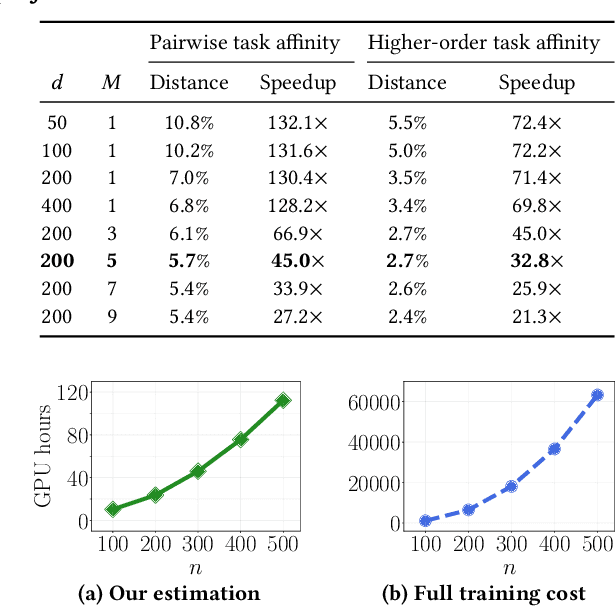
Multitask learning is a widely used paradigm for training models on diverse tasks, with applications ranging from graph neural networks to language model fine-tuning. Since tasks may interfere with each other, a key notion for modeling their relationships is task affinity. This includes pairwise task affinity, computed among pairs of tasks, and higher-order affinity, computed among subsets of tasks. Naively computing either of them requires repeatedly training on data from various task combinations, which is computationally intensive. We present a new algorithm Grad-TAG that can estimate task affinities without this repeated training. The key idea of Grad-TAG is to train a "base" model for all tasks and then use a linearization technique to estimate the loss of the model for a specific task combination. The linearization works by computing a gradient-based approximation of the loss, using low-dimensional projections of gradients as features in a logistic regression to predict labels for the task combination. We show that the linearized model can provably approximate the loss when the gradient-based approximation is accurate, and also empirically verify that on several large models. Then, given the estimated task affinity, we design a semi-definite program for clustering similar tasks by maximizing the average density of clusters. We evaluate Grad-TAG's performance across seven datasets, including multi-label classification on graphs, and instruction fine-tuning of language models. Our task affinity estimates are within 2.7% distance to the true affinities while needing only 3% of FLOPs in full training. On our largest graph with 21M edges and 500 labeling tasks, our algorithm delivers estimates within 5% distance to the true affinities, using only 112 GPU hours. Our results show that Grad-TAG achieves excellent performance and runtime tradeoffs compared to existing approaches.