 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenderFlow: Single-Step Neural Rendering via Flow Matching
Jan 11, 2026Conventional physically based rendering (PBR) pipelines generate photorealistic images through computationally intensive light transport simulations. Although recent deep learning approaches leverage diffusion model priors with geometry buffers (G-buffers) to produce visually compelling results without explicit scene geometry or light simulation, they remain constrained by two major limitations. First, the iterative nature of the diffusion process introduces substantial latency. Second, the inherent stochasticity of these generative models compromises physical accuracy and temporal consistency. In response to these challenges, we propose a novel, end-to-end, deterministic, single-step neural rendering framework, RenderFlow, built upon a flow matching paradigm. To further strengthen both rendering quality and generalization, we propose an efficient and effective module for sparse keyframe guidance. Our method significantly accelerates the rendering process and, by optionally incorporating sparsely rendered keyframes as guidance, enhances both the physical plausibility and overall visual quality of the output. The resulting pipeline achieves near real-time performance with photorealistic rendering quality, effectively bridging the gap between the efficiency of modern generative models and the precision of traditional physically based rendering. Furthermore, we demonstrate the versatility of our framework by introducing a lightweight, adapter-based module that efficiently repurposes the pretrained forward model for the inverse rendering task of intrinsic decomposition.
A Novel ViDAR Device With Visual Inertial Encoder Odometry and Reinforcement Learning-Based Active SLAM Method
Jun 16, 2025In the field of multi-sensor fusion for simultaneous localization and mapping (SLAM), monocular cameras and IMUs are widely used to build simple and effective visual-inertial systems. However, limited research has explored the integration of motor-encoder devices to enhance SLAM performance. By incorporating such devices, it is possible to significantly improve active capability and field of view (FOV) with minimal additional cost and structural complexity. This paper proposes a novel visual-inertial-encoder tightly coupled odometry (VIEO) based on a ViDAR (Video Detection and Ranging) device. A ViDAR calibration method is introduced to ensure accurate initialization for VIEO. In addition, a platform motion decoupled active SLAM method based on deep reinforcement learning (DRL) is proposed. Experimental data demonstrate that the proposed ViDAR and the VIEO algorithm significantly increase cross-frame co-visibility relationships compared to its corresponding visual-inertial odometry (VIO) algorithm, improving state estimation accuracy. Additionally, the DRL-based active SLAM algorithm, with the ability to decouple from platform motion, can increase the diversity weight of the feature points and further enhance the VIEO algorithm's performance. The proposed methodology sheds fresh insights into both the updated platform design and decoupled approach of active SLAM systems in complex environments.
* 12 pages, 13 figures
Whole-Body Impedance Coordinative Control of Wheel-Legged Robot on Uncertain Terrain
Nov 15, 2024



This article propose a whole-body impedance coordinative control framework for a wheel-legged humanoid robot to achieve adaptability on complex terrains while maintaining robot upper body stability. The framework contains a bi-level control strategy. The outer level is a variable damping impedance controller, which optimizes the damping parameters to ensure the stability of the upper body while holding an object. The inner level employs Whole-Body Control (WBC) optimization that integrates real-time terrain estimation based on wheel-foot position and force data. It generates motor torques while accounting for dynamic constraints, joint limits,friction cones, real-time terrain updates, and a model-free friction compensation strategy. The proposed whole-body coordinative control method has been tested on a recently developed quadruped humanoid robot. The results demonstrate that the proposed algorithm effectively controls the robot, maintaining upper body stability to successfully complete a water-carrying task while adapting to varying terrains.
Mx2M: Masked Cross-Modality Modeling in Domain Adaptation for 3D Semantic Segmentation
Jul 09, 2023Existing methods of cross-modal domain adaptation for 3D semantic segmentation predict results only via 2D-3D complementarity that is obtained by cross-modal feature matching. However, as lacking supervision in the target domain, the complementarity is not always reliable. The results are not ideal when the domain gap is large. To solve the problem of lacking supervision, we introduce masked modeling into this task and propose a method Mx2M, which utilizes masked cross-modality modeling to reduce the large domain gap. Our Mx2M contains two components. One is the core solution, cross-modal removal and prediction (xMRP), which makes the Mx2M adapt to various scenarios and provides cross-modal self-supervision. The other is a new way of cross-modal feature matching, the dynamic cross-modal filter (DxMF) that ensures the whole method dynamically uses more suitable 2D-3D complementarity. Evaluation of the Mx2M on three DA scenarios, including Day/Night, USA/Singapore, and A2D2/SemanticKITTI, brings large improvements over previous methods on many metrics.
Domain Adaptation Gaze Estimation by Embedding with Prediction Consistency
Nov 15, 2020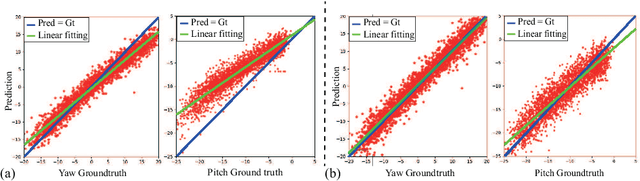
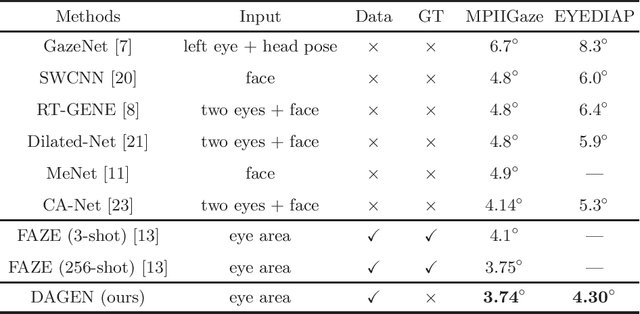
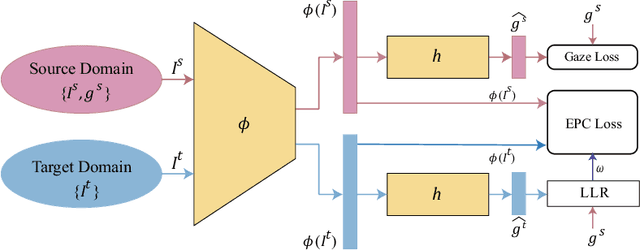

Gaze is the essential manifestation of human attention. In recent years, a series of work has achieved high accuracy in gaze estimation. However, the inter-personal difference limits the reduction of the subject-independent gaze estimation error. This paper proposes an unsupervised method for domain adaptation gaze estimation to eliminate the impact of inter-personal diversity. In domain adaption, we design an embedding representation with prediction consistency to ensure that the linear relationship between gaze directions in different domains remains consistent on gaze space and embedding space. Specifically, we employ source gaze to form a locally linear representation in the gaze space for each target domain prediction. Then the same linear combinations are applied in the embedding space to generate hypothesis embedding for the target domain sample, remaining prediction consistency. The deviation between the target and source domain is reduced by approximating the predicted and hypothesis embedding for the target domain sample. Guided by the proposed strategy, we design Domain Adaptation Gaze Estimation Network(DAGEN), which learns embedding with prediction consistency and achieves state-of-the-art results on both the MPIIGaze and the EYEDIAP datasets.
Learning End-to-End Action Interaction by Paired-Embedding Data Augmentation
Jul 16, 2020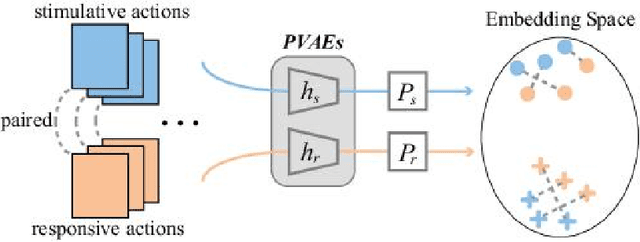
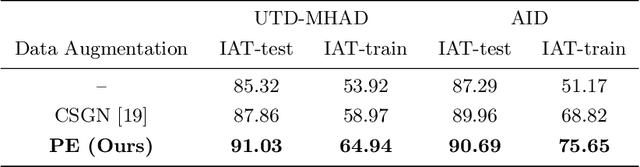
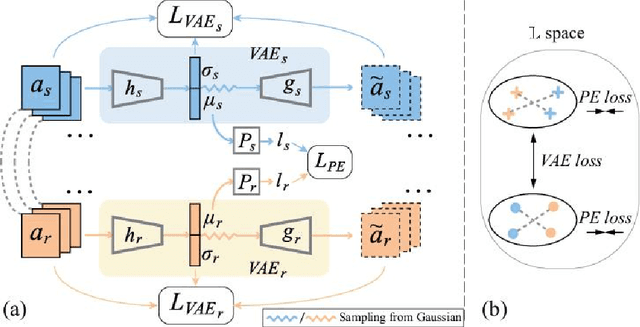
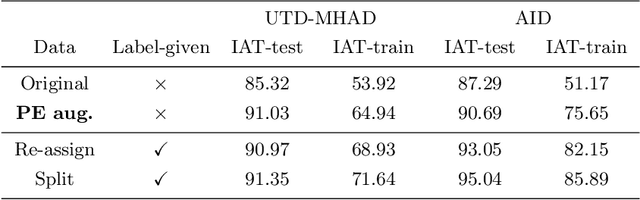
In recognition-based action interaction, robots' responses to human actions are often pre-designed according to recognized categories and thus stiff. In this paper, we specify a new Interactive Action Translation (IAT) task which aims to learn end-to-end action interaction from unlabeled interactive pairs, removing explicit action recognition. To enable learning on small-scale data, we propose a Paired-Embedding (PE) method for effective and reliable data augmentation. Specifically, our method first utilizes paired relationships to cluster individual actions in an embedding space. Then two actions originally paired can be replaced with other actions in their respective neighborhood, assembling into new pairs. An Act2Act network based on conditional GAN follows to learn from augmented data. Besides, IAT-test and IAT-train scores are specifically proposed for evaluating methods on our task. Experimental results on two datasets show impressive effects and broad application prospects of our method.
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Jul 02, 2020
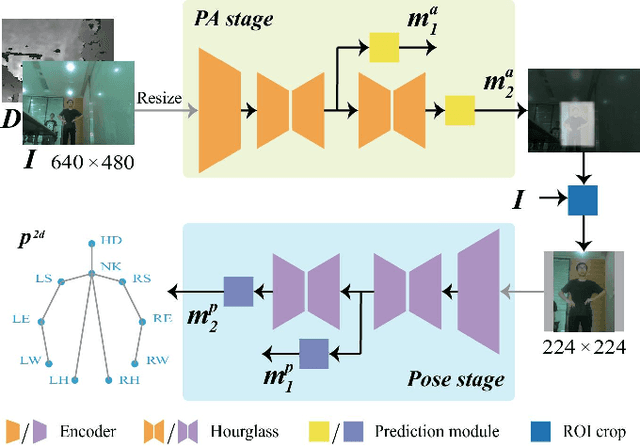
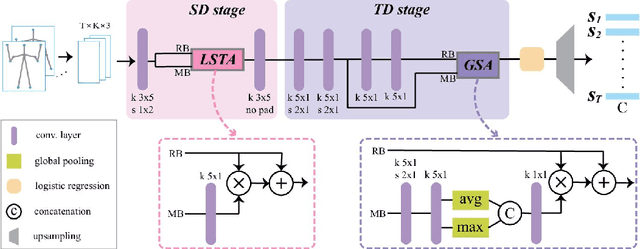
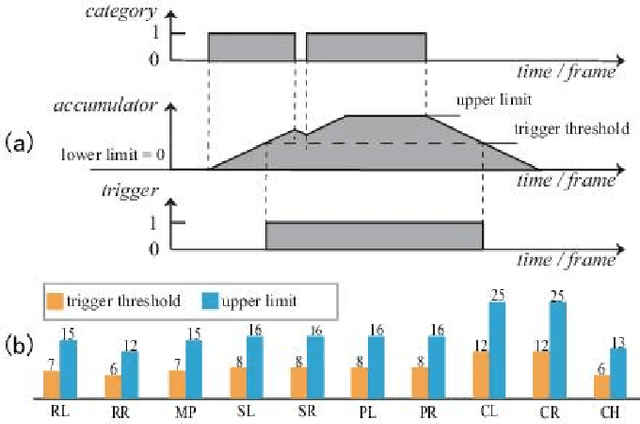
Despite the notable progress made in action recognition tasks, not much work has been done in action recognition specifically for human-robot interaction. In this paper, we deeply explore the characteristics of the action recognition task in interaction scenarios and propose an attention-oriented multi-level network framework to meet the need for real-time interaction. Specifically, a Pre-Attention network is employed to roughly focus on the interactor in the scene at low resolution firstly and then perform fine-grained pose estimation at high resolution. The other compact CNN receives the extracted skeleton sequence as input for action recognition, utilizing attention-like mechanisms to capture local spatial-temporal patterns and global semantic information effectively. To evaluate our approach, we construct a new action dataset specially for the recognition task in interaction scenarios. Experimental results on our dataset and high efficiency (112 fps at 640 x 480 RGBD) on the mobile computing platform (Nvidia Jetson AGX Xavier) demonstrate excellent applicability of our method on action recognition in real-time human-robot interaction.