 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Paper and Code
Jul 02, 2020
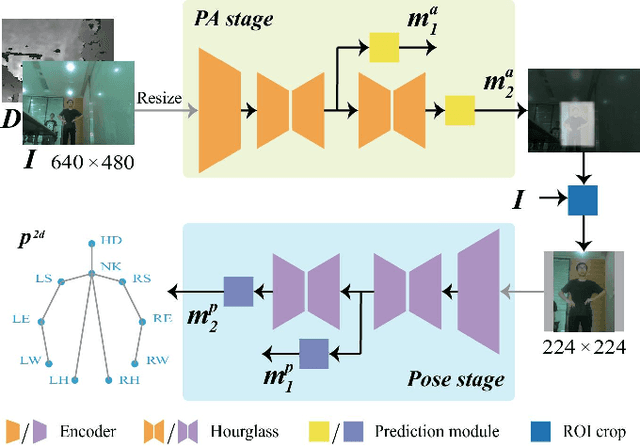
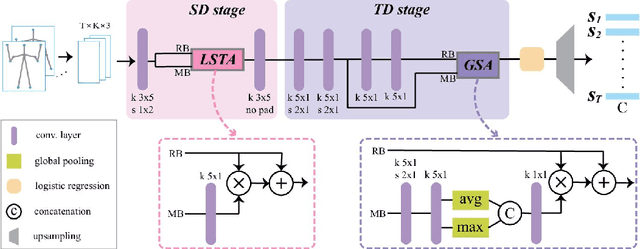
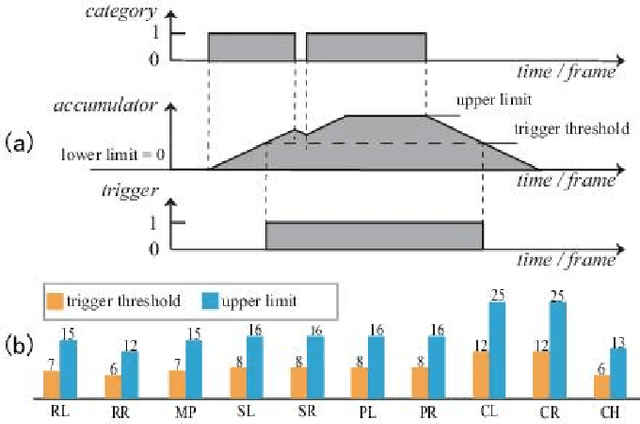
Despite the notable progress made in action recognition tasks, not much work has been done in action recognition specifically for human-robot interaction. In this paper, we deeply explore the characteristics of the action recognition task in interaction scenarios and propose an attention-oriented multi-level network framework to meet the need for real-time interaction. Specifically, a Pre-Attention network is employed to roughly focus on the interactor in the scene at low resolution firstly and then perform fine-grained pose estimation at high resolution. The other compact CNN receives the extracted skeleton sequence as input for action recognition, utilizing attention-like mechanisms to capture local spatial-temporal patterns and global semantic information effectively. To evaluate our approach, we construct a new action dataset specially for the recognition task in interaction scenarios. Experimental results on our dataset and high efficiency (112 fps at 640 x 480 RGBD) on the mobile computing platform (Nvidia Jetson AGX Xavier) demonstrate excellent applicability of our method on action recognition in real-time human-robot interaction.