 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFecTek: Enhancing Term Weight in Lexicon-Based Retrieval with Feature Context and Term-level Knowledge
Apr 18, 2024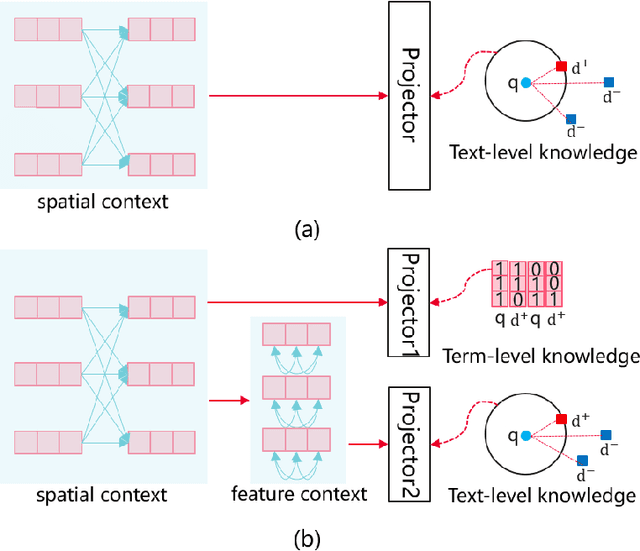



Lexicon-based retrieval has gained siginificant popularity in text retrieval due to its efficient and robust performance. To further enhance performance of lexicon-based retrieval, researchers have been diligently incorporating state-of-the-art methodologies like Neural retrieval and text-level contrastive learning approaches. Nonetheless, despite the promising outcomes, current lexicon-based retrieval methods have received limited attention in exploring the potential benefits of feature context representations and term-level knowledge guidance. In this paper, we introduce an innovative method by introducing FEature Context and TErm-level Knowledge modules(FecTek). To effectively enrich the feature context representations of term weight, the Feature Context Module (FCM) is introduced, which leverages the power of BERT's representation to determine dynamic weights for each element in the embedding. Additionally, we develop a term-level knowledge guidance module (TKGM) for effectively utilizing term-level knowledge to intelligently guide the modeling process of term weight. Evaluation of the proposed method on MS Marco benchmark demonstrates its superiority over the previous state-of-the-art approaches.
Mx2M: Masked Cross-Modality Modeling in Domain Adaptation for 3D Semantic Segmentation
Jul 09, 2023Existing methods of cross-modal domain adaptation for 3D semantic segmentation predict results only via 2D-3D complementarity that is obtained by cross-modal feature matching. However, as lacking supervision in the target domain, the complementarity is not always reliable. The results are not ideal when the domain gap is large. To solve the problem of lacking supervision, we introduce masked modeling into this task and propose a method Mx2M, which utilizes masked cross-modality modeling to reduce the large domain gap. Our Mx2M contains two components. One is the core solution, cross-modal removal and prediction (xMRP), which makes the Mx2M adapt to various scenarios and provides cross-modal self-supervision. The other is a new way of cross-modal feature matching, the dynamic cross-modal filter (DxMF) that ensures the whole method dynamically uses more suitable 2D-3D complementarity. Evaluation of the Mx2M on three DA scenarios, including Day/Night, USA/Singapore, and A2D2/SemanticKITTI, brings large improvements over previous methods on many metrics.